TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024166749
公報種別
公開特許公報(A)
公開日
2024-11-29
出願番号
2023083069
出願日
2023-05-19
発明の名称
学習モデル生成方法、情報処理装置、シーン判定システム、学習プログラム及びシーン判定プログラム
出願人
株式会社デンソーテン
代理人
弁理士法人秀和特許事務所
主分類
G08G
1/16 20060101AFI20241122BHJP(信号)
要約
【課題】異なる種別のデータを用いた学習モデルの作成を効率化する学習モデル生成方法、情報処理装置、シーン判定システム、学習プログラム及びシーン判定プログラムを提供する。
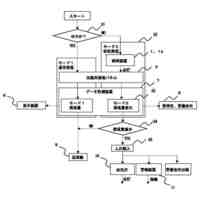
【解決手段】画像データに対して画像データのシーンを識別する学習モデルの生成方法であって、カメラで撮影された第1の画像データの撮影時点に対応した音声取得期間に取得された音声データを可視化した第2の画像データを作成するステップS2と、第1の画像データと第2の画像データとを統合した第3の画像データを作成するステップS3と、第3の画像データに、第1の画像データに対応するシーンを正解データとして付与した学習データにより学習モデルを生成するための学習を行うステップS4と、を含む。
【選択図】図8
特許請求の範囲
【請求項1】
画像データに対して前記画像データのシーンを識別する学習モデルの生成方法であって、
カメラで撮影された第1の画像データの撮影時点に対応した音声取得期間に取得された音声データを可視化した第2の画像データを作成し、
前記第1の画像データと前記第2の画像データとを統合した第3の画像データを作成し、
前記第3の画像データに、前記第1の画像データに対応するシーンを正解データとして付与した学習データにより前記学習モデルを生成するための学習を行う、
学習モデル生成方法。
続きを表示(約 2,100 文字)
【請求項2】
前記第3の画像データは、前記第1の画像データと前記第2の画像データとを重畳して作成される
請求項1に記載の学習モデル生成方法。
【請求項3】
前記第1の画像データが撮像された地点の周囲の環境に応じて、前記第1の画像データと前記第2の画像データとを重畳する割合を変更する
請求項2に記載の学習モデル生成方法。
【請求項4】
前記音声データは、異なる方向の音声を取得する複数のマイクロフォンを介して取得された複数の音声データを含み、
前記複数の音声データをそれぞれ可視化した複数の前記第2の画像データを作成し、
前記複数の第2の画像データの各々を前記第1の画像データに対して異なる位置に配置して前記第3の画像データが作成される
請求項1に記載の学習モデル生成方法。
【請求項5】
前記音声取得期間は、前記第1の画像データの撮影時点から設定時間前を開始時刻とし、前記第1の画像データの撮影時点を終了時刻とする期間である
請求項1に記載の学習モデル生成方法。
【請求項6】
前記可視化は、周波数解析の結果を表す画像を生成することにより行われる
請求項1に記載の学習モデル生成方法。
【請求項7】
画像データに対して前記画像データのシーンを識別する情報処理装置であって、
カメラで撮影された学習用の学習用画像データと、前記学習用画像データの撮影時点に対応した音声取得期間に取得された学習用の学習用音声データを可視化した音声画像データとを統合した学習用統合画像データを入力データとし、前記入力データに前記学習用画像データに対応するシーンを正解データとして付与した学習データで学習した学習済モデルを備え、
カメラが撮影した識別用の識別用画像データを取得し、
前記識別用画像データの撮影時点に対応した音声取得期間に識別用の識別用音声データを取得し、
前記識別用音声データを可視化した音声画像データと前記識別用画像データを統合した識別用統合画像データを作成し、
前記識別用統合画像データを前記学習済モデルに適用してシーンを識別する
情報処理装置。
【請求項8】
周囲の音声を取得するマイクロフォンと、
周囲を撮影するカメラと、
前記マイクロフォンの出力する音声データと、前記カメラの出力する画像データを入力して、前記画像データのシーンを識別する情報処理装置と、を含む車両に搭載されるシーン判定システムであって、
前記情報処理装置は、
カメラで撮影された学習用の学習用画像データと、前記学習用画像データの撮影時点に対応した音声取得期間に取得された学習用の学習用音声データを可視化した音声画像データとを統合した学習用統合画像データを入力データとし、前記入力データに前記学習用画像データに対応するシーンを正解データとして付与した学習データで学習した学習済モデルを備え、
カメラが撮影した識別用の識別用画像データを取得し、
前記識別用画像データの撮影時点に対応した音声取得期間に識別用の識別用音声データを取得し、
前記識別用音声データを可視化した音声画像データと前記識別用画像データを統合した識別用統合画像データを作成し、
前記識別用統合画像データを前記学習済モデルに適用してシーンを識別する
シーン判定システム。
【請求項9】
コンピュータにより実行され、画像データのシーンを識別する学習モデルを生成する学習プログラムであって、
カメラで撮影された第1の画像データの撮影時点に対応した音声取得期間に取得された音声データを可視化した第2の画像データを作成し、
前記第1の画像データと前記第2の画像データとを統合した第3の画像データを作成し、
前記第3の画像データに、前記第1の画像データに対応するシーンを正解データとして付与した学習データにより学習モデルの学習を行い、前記学習モデルを生成する
学習プログラム。
【請求項10】
コンピュータにより実行され、画像データのシーンを識別するシーン判定プログラムであって、
カメラで撮影された学習用の学習用画像データと、前記学習用画像データの撮影時点に対応した音声取得期間に取得された学習用の学習用音声データを可視化した音声画像データとを統合した学習用統合画像データを学習データとし、前記学習データに前記学習用画像データに対応するシーンを正解データとして付与した前記学習データで学習した学習済モデルを備え、
カメラが撮影した識別用の識別用画像データを取得し、
前記識別用画像データの撮影時点に対応した音声取得期間に識別用の識別用音声データを取得し、
前記識別用音声データを可視化した音声画像データと前記識別用画像データを統合した識別用統合画像データを作成し、
前記識別用統合画像データを前記学習済モデルに適用してシーンを識別する
シーン判定プログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、シーン認識を行うための学習モデルを生成する学習モデル生成方法、シーン認識を行う情報処理装置、シーン判定システム、学習プログラム及びシーン判定プログラムに関する。
続きを表示(約 2,100 文字)
【背景技術】
【0002】
従来、複数のマイク及びセンサを搭載している複数の車両と、複数のマイクで録音された音声信号及びセンサで測定されたセンシングデータを取得する取得部を有するサーバと、を備える運転支援システムが提案されていた(例えば、特許文献1)。サーバは、音声信号及びセンシングデータに音源の危険性を表す情報を関連付けた学習データを記憶する記憶部と、学習データを用いて、音声信号及びセンシングデータに基づいて、音源の危険性を予測する学習モデルを生成するモデル生成部と、危険性を複数の車両に提供する提供部と、を有する。また、音源の画像を撮影させる撮影部をさらに有し、音源の危険性を表す情報と関連付けて学習データとして蓄積することも開示されている。すなわち、画像を用いて音源を認識し、音源の危険性を表す情報を生成する。危険性を表す情報は、学習データに対するアノテーションに用いられる。
【先行技術文献】
【特許文献】
【0003】
特開2020-144404号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
車両から取得した音声信号及びセンシングデータ等の複数のデータを用いて学習データや学習モデルを生成する場合、様々なデータ種別やサイズ等に対応するように学習モデルの入力部分の構成を構築する必要がある。そこで、本開示は、異なる種別のデータによる学習モデルの作成の効率化を目的とする。
【課題を解決するための手段】
【0005】
本開示に係る学習モデル生成方法は、画像データに対して前記画像データのシーンを識別する学習モデルを生成するための方法である。該学習モデル生成方法は、カメラで撮影された第1の画像データの撮影時点に対応した音声取得期間に取得された音声データを可視化した第2の画像データを作成し、前記第1の画像データと前記第2の画像データとを統合した第3の画像データを作成し、前記第3の画像データに、前記第1の画像データに対応するシーンを正解データとして付与した学習データにより前記学習モデルを生成するための学習を行う。
【発明の効果】
【0006】
本技術によれば、異なる種別のデータを用いた学習モデルの作成を効率化することができる。
【図面の簡単な説明】
【0007】
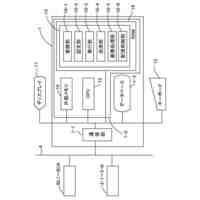
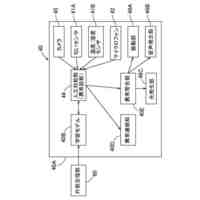
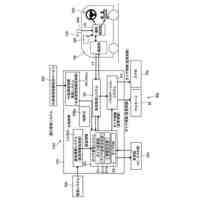
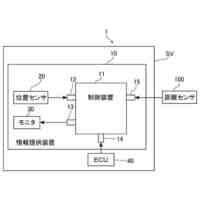
図1は、システムの構成の一例を説明するためのブロック図である。
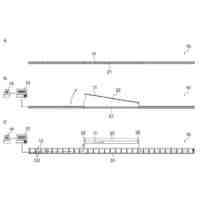
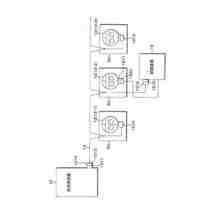
図2は、カメラで撮像された画像データの一例を示す図である。
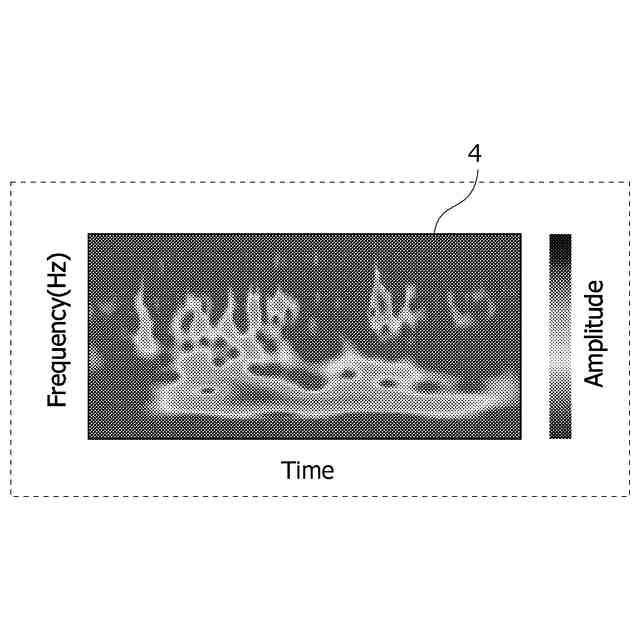
図3は、音声をウェーブレット変換して作成した可視化画像の一例を示す。
図4は、FFTにより作成される可視化画像の一例を示す図である。
図5は、統合データの一例を示す図である。
図6は、変形例に係る統合データを示す図である。
図7は、変形例に係る統合データを示す図である。
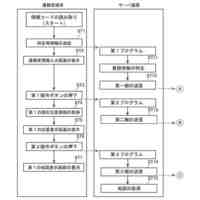
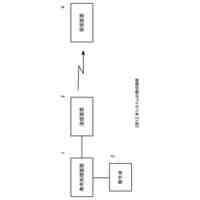
図8は、学習処理の一例を示す処理フロー図である。
図9は、シーン認識処理の一例を示す処理フロー図である。
図10は、出力されるシーン認識の結果を説明するための図である。
【発明を実施するための形態】
【0008】
<実施形態>
以下、図面を参照しつつ実施形態について説明する。図1は、システムの構成の一例を説明するためのブロック図である。システム100は、車両1と情報処理装置2とを含む。車両1は、カメラにより撮像された画像データと、マイクロフォンにより取得された音声データと、情報処理装置2が機械学習を行い作成した学習済モデルとを用いて、シーン認識を行う。学習済モデルは、例えば、交差点での車や歩行者の接近といった危険な状況等のシーンを検知するための判別器である。学習済モデルは、走行中において所定の状況が生じる画像と、当該画像の撮像時点に対応する所定期間の音声とからなる入力(問題)データとして、且つシーンを表すラベル(正解データ)を教師データとして、機械学習により作成される。
【0009】
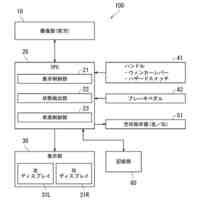
車両1は、乗用車等である。車両1は、プロセッサ11と、記憶装置12と、カメラ13と、マイクロフォン14と、ユーザインターフェース(UI)15とを備える。これらの構成要素は、バスを介して接続され、シーン判定システムを構成する。車両1は、走行中に本実施形態に係るシーン認識を行うものとする。
【0010】
プロセッサ11は、CPU(Central Processing Unit)等の演算処理装置である。プ
ロセッサ11は、プログラムを実行することにより、実施形態に係る各処理を行う。図1の例では、プロセッサ11内に機能ブロックを示している。すなわち、プロセッサ11は、所定のプログラムを実行することにより、前処理部111及び判定部112として機能する。これらの機能部については後述する。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社デンソーテン
制御装置および制御方法
1日前
株式会社デンソーテン
レバースイッチ、ディスプレイ装置、及び車載機器
今日
株式会社デンソーテン
映像処理装置、車載カメラシステムおよび映像処理方法
今日
株式会社デンソーテン
充電制御装置、車載装置、充電制御方法、及び充電制御プログラム
今日
個人
自動運転車
2か月前
個人
黄色点滅式信号機
10日前
個人
空飛ぶ自動車の空路
6日前
個人
迷子支援システム
1か月前
個人
万引き防止システム
27日前
株式会社ニカデン
検出装置
1か月前
ABT合同会社
詐欺防止装置
27日前
株式会社サンライン
発炎筒携行容器
2か月前
ニッタン株式会社
発信機
1か月前
ニッタン株式会社
発信機
1か月前
株式会社あおい興産
避難誘導灯
1か月前
株式会社国際電気
防災システム
1か月前
日本信号株式会社
運行管理システム
20日前
ホーチキ株式会社
防災システム
27日前
京セラ株式会社
制御装置
1か月前
合同会社ORIC-LAB
太陽光発電管理装置
1日前
シャープ株式会社
表示装置
2か月前
株式会社SUBARU
危険報知システム
27日前
本田技研工業株式会社
路面評価装置
今日
本田技研工業株式会社
路面評価装置
今日
株式会社豊田自動織機
運行表示装置
1か月前
戸田建設株式会社
検知システム
2か月前
日本信号株式会社
信号システム及び信号灯器
1か月前
トヨタ自動車株式会社
情報提供システム
2か月前
株式会社小糸製作所
情報提供装置及び制御装置
27日前
株式会社知財事業研究所
運行計画作成システム
今日
株式会社JR西日本テクシア
接触防止システム
1か月前
株式会社JVCケンウッド
報知装置及び報知方法
1か月前
株式会社JVCケンウッド
報知装置及び報知方法
1か月前
トヨタ自動車株式会社
車両の情報処理装置
24日前
シャープ株式会社
通信装置および通信方法
2か月前
株式会社京三製作所
交通信号制御システム
1か月前
続きを見る
他の特許を見る










 特許ウォッチ
特許ウォッチ