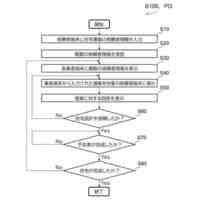
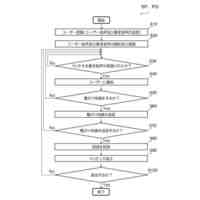
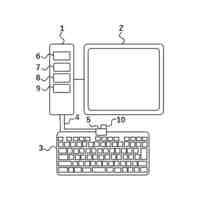
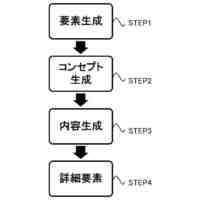
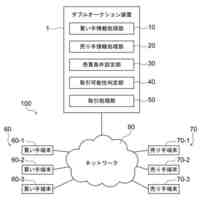
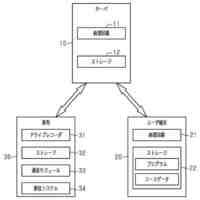
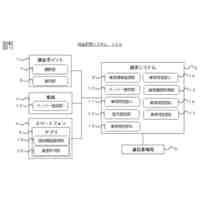
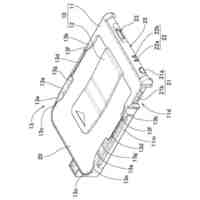
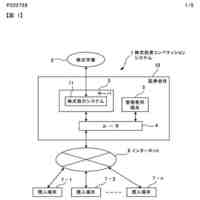
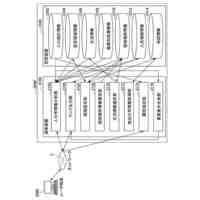
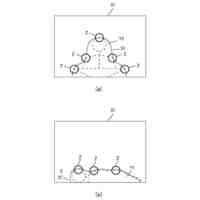
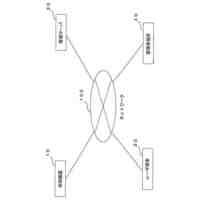
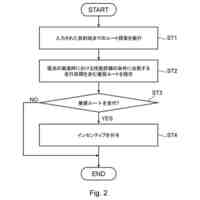
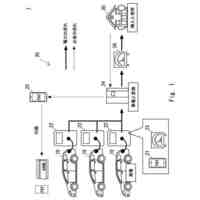
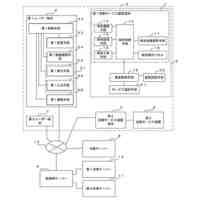
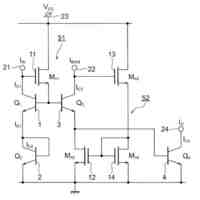
発明の詳細な説明【技術分野】 【0001】 本発明は、分散学習システムおよび学習データ評価方法に係り、特に、教師データあり機械学習に関して、分散型の計算機システムに適した学習データの学習に関する寄与度を評価するのに好適な分散学習システムおよび学習データ評価方法に関する。 続きを表示(約 2,400 文字)【背景技術】 【0002】 教師データあり機械学習は、大量の学習データを学習することにより、解決しようとする問題の推論のための学習モデルを最適なものに近づけていくことにより、計算機により最適な問題解決を図る手法である。 【0003】 そのときに、学習データとして最適なものを与えることで、ユーザに対して、より性能の高い学習モデルを与えることができる。そのために、学習データの学習に対する寄与度という概念を導入することが考えられる。 【0004】 機械学習システムに対して、寄与度という概念を用いた技術は、例えば、特許文献1がある。特許文献1の記載された技術では、機械学習システムでは、評価対象データは、初期データ群に対して追加又は除外するデータであり、寄与度計算部が、学習モデルによる出力値と、初期データ群に対して評価対象データを追加又は除外して学習した再学習モデルによる出力値とに基づいて、評価対象データが学習モデルの性能に与える影響を評価する寄与度を計算するとしている。 【0005】 これにより、学習データに対する評価対象データの除外及び追加が機械学習モデルの性能に与える影響の良否を知り得ることができるとしている。 【0006】 また、パラメータの予測に対する影響を影響関数(influence function)として評価する技術が、非特許文献1に開示されている。 【0007】 非特許文献1には、「影響関数が専門家に注意を惹起させて、実際に役立つ事項のみを検査することができることを説明する」(We show that influence functions can help human experts prioritize their attention, allowing them to inspect only the examples that actually matter)という記載と、「L up,loss (Z i ,Z i )により、Z i の影響を測定する。これにより、訓練データセットから、Z i を削除した場合のZ i に発生する誤差を近似する」(we measure the influence of Z i with L up,loss (Z i ,Z i ), which approximates the error incurred on Z i if we remove Z i from the training set)との記載がある(いずれも、5.4 Fixing mislabeled examples)。 【0008】 また、非特許文献2には、中央サーバーと複数の計算機間の通信を介して実行される機械学習において、ある計算機を除外することにより、機械学習で得られるモデルの性能に与える影響を推定する技術が記載されている。非特許文献2には、「広範な研究が、グローバルモデルのパフォーマンス保証について行われているが、個々のクライアントが共同トレーニングプロセスにどのような影響を与えるかは、いまだに明らかにされていない。この研究では、モデルパラメータに対するこの影響を定量化するために『Fed-Influence』と呼ばれる新しい概念を定義し、この指標を推定するための効果的かつ効率的なアルゴリズムを提案する。」(Extensive works have studied the performance guarantee of the global model however, it is still unclear how each individual client influences the collaborative training process. In this work, we defined a new notion, called Fed-Influence, to quantify this influence over the model parameters, and proposed an effective and efficient algorithm to estimate this metric.)との記載(Abstracts)と、「集中型の学習のサーバーは、影響を評価するものとして、考慮されるサンプリングデータを完全にコントロールできるが、一方、連合学習では、サーバーは、プライバシーの要請のために、クライアントのデータにアクセスできない。(The server in centralized learning, as the influence evaluator, has the full control over the considered sampling data, while in federated learning, the server would not be able to access clients’ raw data because of the privacy requirement)との記載(Introduction)がある。 【0009】 また、複数のエージェントによる分散最適化に関する技術については、非特許文献3に開示がある。 【先行技術文献】 【特許文献】 【0010】 特開2021-149842号公報 【非特許文献】 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する




 特許ウォッチ
特許ウォッチ