TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025004019
公報種別
公開特許公報(A)
公開日
2025-01-14
出願番号
2024161113,2021555500
出願日
2024-09-18,2020-02-27
発明の名称
マルチビュービデオシーケンスをコード化および復号化するための方法およびデバイス
出願人
オランジュ
代理人
個人
,
個人
主分類
H04N
19/597 20140101AFI20250106BHJP(電気通信技術)
要約
【課題】マルチビュービデオを表すデータストリームを復号する方法及び符号化する方法を提供する。
【解決手段】データストリームを復号するための方法は、少なくとも1つのサブ画像を表す少なくともコード化されたデータを備え、テクスチャデータおよびテクスチャデータに関連付けられる深度データを備え、サブ画像が少なくとも1つのゾーンを備える。サブ画像が第1の方法または第2の方法に従ってコード化されているかどうかを示すインジケータが復号される。インジケータがサブ画像が第1の方法に従ってコード化されていることを示す場合、サブ画像の少なくとも1つのピクセルについて、ピクセルが有用なゾーンに属するかどうかを示すバイナリマップが復号される。インジケータが、サブ画像が第2の方法に従ってコード化されていることを示す場合、有用なゾーンの外側に位置するピクセルのサブ画像の深度データは復号された深度値を備える。
【選択図】なし
特許請求の範囲
【請求項1】
マルチビュービデオを表す少なくとも1つのデータストリームを復号化するための方法であって、前記少なくとも1つデータストリームが、少なくとも1つのサブ画像を表す少なくともコード化されたデータを備え、前記コード化されたデータが、テクスチャデータおよび前記テクスチャデータに関連付けられる深度データを備え、前記サブ画像が、有用なゾーンと呼ばれる少なくとも1つのゾーンと、有用でないゾーンと呼ばれる1つのゾーンとを備え、前記有用なゾーンが、前記データストリームにコード化されていない前記マルチビュービデオのビューから抽出されたゾーンに対応し、前記有用なゾーンが、少なくとも1つのビューの少なくとも1つの画像を生成するために使用されることが意図され、前記復号化方法が、
- 前記少なくとも1つのデータストリームから、前記サブ画像が第1の方法に従って、または第2の方法に従ってコード化されているかどうかを示すインジケータを復号化するステップと、
- 前記インジケータが、前記サブ画像が前記第1の方法に従ってコード化されていることを示す場合、前記サブ画像の少なくとも1つのピクセルについて、前記ピクセルが前記有用なゾーンに属するかどうかを示すバイナリマップを前記サブ画像に復号化するステップと、
- 前記サブ画像の前記テクスチャデータおよび前記深度データを復号化するステップであって、前記インジケータが、前記サブ画像が前記第2の方法に従ってコード化されていることを示す場合、前記有用なゾーンの外側に位置する前記ピクセルの前記サブ画像の前記深度データが、割当て深度値を備える、ステップと
を備える、方法。
続きを表示(約 2,200 文字)
【請求項2】
マルチビュービデオを表すデータストリームをコード化するための方法であって、テクスチャデータおよび前記テクスチャデータに関連付けられる深度データを備える少なくとも1つのサブ画像をコード化するステップを備え、前記サブ画像が、前記有用なゾーンと呼ばれるゾーンと有用でないゾーンと呼ばれるゾーンとを備え、前記有用なゾーンが、前記データストリームにコード化されていない前記マルチビュービデオのビューから抽出されたゾーンに対応し、前記有用なゾーンが、少なくとも1つのビューの少なくとも1つの画像を生成するために使用されることが意図され、前記少なくとも1つのサブ画像をコード化するステップが、
- 第1の方法と第2の方法との間で前記サブ画像をコード化するためのコード化方法を決定するステップと、
- 前記サブ画像が前記第1の方法に従って、または前記第2の方法に従ってコード化されているかどうかを示すインジケータをコード化するステップと、
- 前記インジケータが、前記サブ画像が前記第1の方法に従ってコード化されていることを示す場合、前記サブ画像の少なくとも1つのピクセルについて、前記ピクセルが前記有用なゾーンに属するかどうかを示すバイナリマップを前記サブ画像にコード化するステップと、
- 前記インジケータが、前記サブ画像が前記第2の方法に従ってコード化されていることを示す場合、割当て深度値を決定するステップと、前記有用なゾーンの外側に位置する前記サブ画像の前記ピクセルについて、前記サブ画像の前記深度データに前記割当て深度値を割り当てるステップと、
- 前記サブ画像の前記テクスチャデータおよび前記深度データをコード化するステップとを備える、方法。
【請求項3】
前記割当て深度値が、少なくとも前記サブ画像の前記有用なゾーンにわたって決定され、あらかじめ定められた値だけ減少された最小深度値から決定される、請求項2に記載のコード化方法。
【請求項4】
前記インジケータが、前記サブ画像が前記第2の方法に従ってコード化されていることを示す場合、前記割当て深度値を表す情報の項目を復号化またはコード化するステップをさらに備え、前記割当て深度値0が、前記有用なゾーンの外側に位置する前記ピクセルについて、前記復号化またはコード化された深度値に対応する、請求項1に記載の復号化方法または請求項2もしくは3に記載のコード化方法。
【請求項5】
前記データストリームにコード化された前記サブ画像の前記深度データが、前記サブ画像の少なくとも1つのピクセルについて、前記ピクセルの前記深度値と前記割当て深度値との間の差によって決定される残差を備える、請求項4に記載の方法。
【請求項6】
前記データストリームにおいて、前記少なくとも1つのサブ画像に対して、前記深度データが、前記ピクセルの前記深度値と前記割当て深度値との間の差によって決定される残差によってコード化されるかどうかを示すインジケータを復号化またはコード化するステップを備える、請求項5に記載の方法。
【請求項7】
- 前記インジケータが、前記サブ画像が前記第2の方法に従ってコード化されていることを示す場合、前記再構築された深度データと、前記復号化された割当て深度値を表す情報の前記項目とから、または、前記インジケータが、前記サブ画像が前記第1の方法に従ってコード化されていることを示す場合、前記復号化されたバイナリマップから、前記有用なゾーンを決定するステップと、
- 前記有用なゾーンの外側に位置する前記ピクセルに無限の値が割り当てられる前記サブ画像の深度マップを構築するステップと、
- 前記深度マップを合成モジュールに送信するステップと
をさらに備える、請求項4から6のいずれか一項に記載の復号化方法。
【請求項8】
前記サブ画像が前記第2の方法に従ってコード化されていることを前記インジケータが示す場合、
- 前記再構築された深度データと、前記復号化された割当て深度値を表す情報の前記項目とから、前記有用なゾーンを決定するステップと、
- 前記サブ画像の少なくとも1つのピクセルについて、前記ピクセルが前記有用なゾーンに属するかどうかを示すバイナリマップを構築するステップと、
- 前記バイナリマップを合成モジュールに送信するステップと
をさらに備える、請求項4から6のいずれか一項に記載の復号化方法。
【請求項9】
少なくとも2つの有用なゾーンがそれぞれ少なくとも2つのサブ画像に属し、前記少なくとも1つのビューの前記少なくとも1つの画像を生成するために使用されることが意図された前記少なくとも2つの有用なゾーンが、前記データストリームにコード化され、前記最小深度値が、前記少なくとも2つの有用なゾーンの各有用なゾーンから決定される、請求項3に記載の方法。
【請求項10】
前記少なくとも1つのデータストリームが、前記ビデオの少なくとも1つのビューのコード化されたデータを備え、前記少なくとも1つのビューが、少なくとも1つのソースビューからのコード化において決定されたビューに対応する、請求項1から9のいずれか一項に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、1つまたは複数のカメラによってキャプチャされたシーンを表す没入型ビデオに関する。より詳細には、本発明は、そのようなビデオのコード化および復号化に関する。
続きを表示(約 1,500 文字)
【背景技術】
【0002】
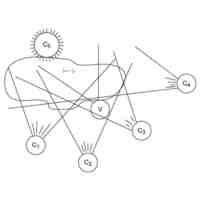
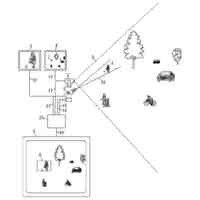
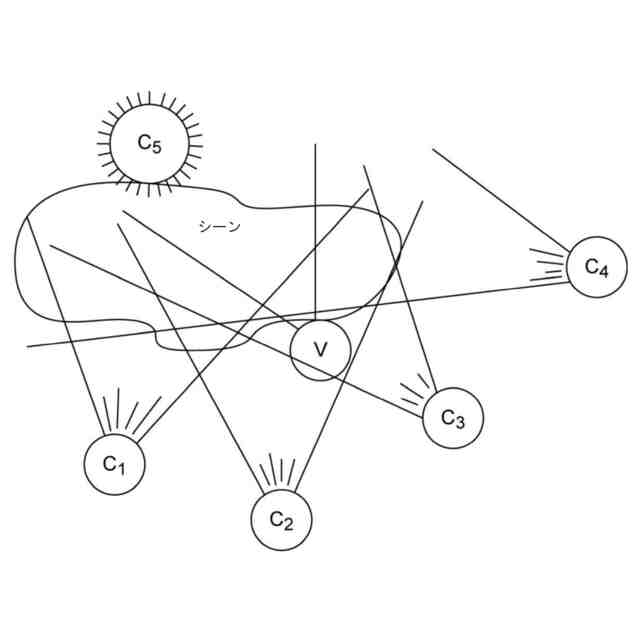
没入型ビデオのコンテキスト、すなわち、視聴者がシーンに没頭しているような感覚の場合、シーンは通常、図1に示されるように、カメラのセットによってキャプチャされる。これらのカメラはタイプ2D(図1におけるカメラC1、C2、C3、C4)であってもよく、タイプ360、すなわち、カメラの周囲360度のシーン全体をキャプチャするもの(図1におけるカメラC5)であってもよい。
【0003】
これらのキャプチャされたビューはすべて、従来、視聴者の端末によってコード化され、次いで復号化される。しかしながら、十分な品質の体験を提供し、したがって、視聴者に表示されるシーンにおける視覚的品質および良好な没入感を提供するためには、キャプチャされたビューのみを表示することは不十分である。
【0004】
シーンへの没入感を向上させるために、通常、中間ビューと呼ばれる1つまたは複数のビューが、復号化されたビューから計算される。
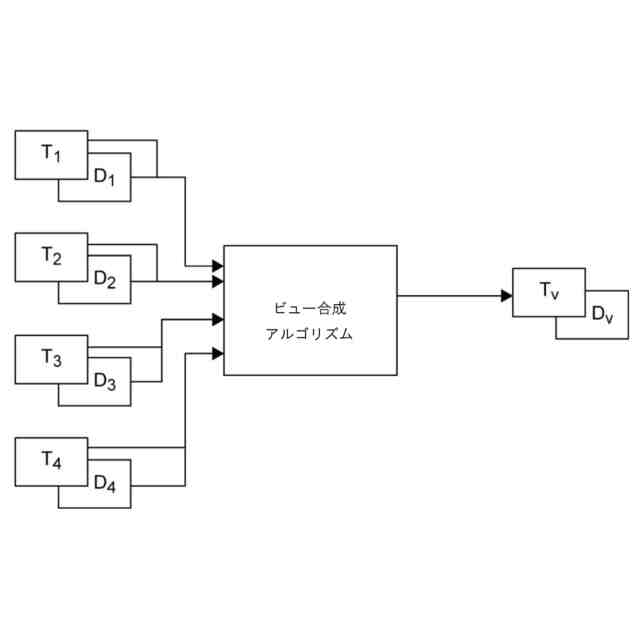
【0005】
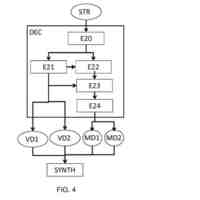
これらの中間ビューは、ビューの「合成」アルゴリズムによって計算することができる。合成アルゴリズムの例が図2に示されており、これは、主にビュー合成アルゴリズムの入力/出力を示している。この例によれば、n個のビュー(ここでは1~4)から、合成アルゴリズムは、カメラの位置に応じて、ビューイングボリュームと呼ばれる所与のボリュームに位置する視点「v」を合成することができる。n個のビューおよび合成されたビューは、カメラに対するシーンの要素間の距離を表すテクスチャデータ(T
1
~T
4
、T
v
)と深度データ(D
1
~D
4
、D
v
)の両方で構成される。深度データは通常、深度マップ、すなわち、画像の各ポイントにおいて、そのポイントにおいて表されるオブジェクトに関連付けられる深度を示す画像の形態で表される。
【0006】
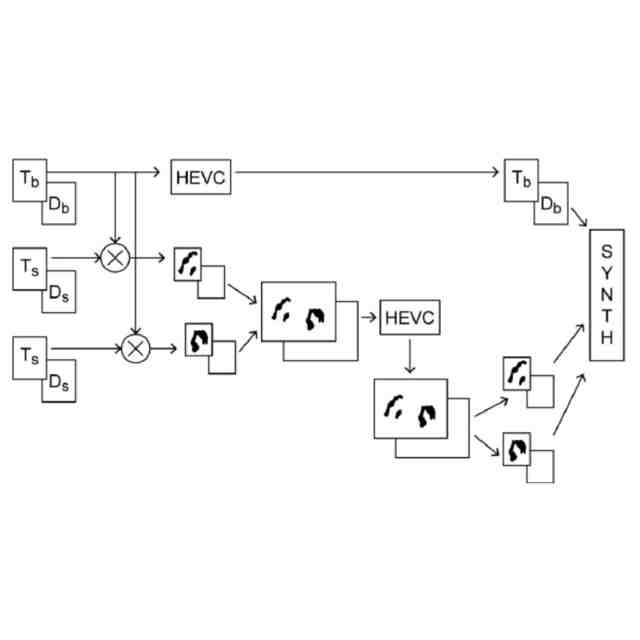
これらの深度マップは、特定のカメラによってキャプチャされるか、テクスチャビューから計算される。大量のデータが考慮されるため、シーンを表すためにキャプチャされたビューを圧縮することは困難である。
【0007】
さらに、キャプチャされたビューは中間ビューを合成するために必要であるため、ビューのコード化効率と中間ビュー合成の品質との間の妥協が必要である。
【0008】
MV-HEVCおよび3D-HEVCエンコーダは、マルチビュービデオのコード化に適合した2D HEVCエンコーダの2つの拡張機能である(「High Efficiency Video Coding, Coding Tools and Specification」、Matthias Wien、Signals and Communication Technology、2015年)。
【0009】
そのようなエンコーダは、ビューのセットと、任意で関連付けられる深度マップを入力として受け取る。MV-HEVCエンコーダは、ブロックレベルで任意の特定のコード化ツールを適用しない。現在のビューの画像をコード化する場合、現在のビューの以前にコード化/復号化された画像に加えて、別のビューの画像を参照画像として単に使用する。
【0010】
3D-HEVCエンコーダは、深度マップコード化に特定のツールを追加し、より高度なビュー間冗長性とコンポーネント間冗長性を使用し、深度マップコード化はテクスチャコード化を利用する。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
オランジュ
マルチビュービデオシーケンスをコード化および復号化するための方法およびデバイス
19日前
オランジュ
少なくとも1つの画像を表すデータストリームを符号化および復号するための方法およびデバイス
26日前
オランジュ
少なくとも1つの画像を表すデータストリームをコーディングおよび復号するための方法およびデバイス
26日前
オランジュ
マルチビュービデオのデコードの方法及び装置、並びに画像合成の方法、コンピュータプログラム及び装置
5日前
個人
環境音制御方法
2か月前
日本無線株式会社
秘匿通信
2か月前
日本精機株式会社
表示装置
2か月前
個人
押しボタン式側圧調整器
2か月前
個人
ヘッドホンカバー
24日前
キヤノン株式会社
撮像装置
1か月前
BoCo株式会社
聴音装置
1か月前
BoCo株式会社
聴音装置
1か月前
日本精機株式会社
車両用の撮像装置
17日前
キヤノン電子株式会社
画像読取装置
1か月前
日本放送協会
無線伝送システム
3日前
個人
テレビ画面の立体画像の表示方法
2か月前
株式会社ベアリッジ
携帯無線機
1か月前
リオン株式会社
聴取装置
16日前
キヤノン株式会社
映像表示装置
25日前
キヤノン電子株式会社
画像読取システム
16日前
日本セラミック株式会社
超音波送受信器
2か月前
株式会社アーク
情報処理システム
25日前
株式会社小糸製作所
画像照射装置
3日前
シャープ株式会社
表示装置
1か月前
株式会社Move
イヤホン
9日前
株式会社国際電気
無線通信システム
16日前
株式会社ミチヒロ
SoTモジュール
2か月前
個人
テレビ画面の注視する画像の表示方法
19日前
キヤノン株式会社
画像形成システム
1か月前
株式会社JVCケンウッド
撮像装置
25日前
株式会社日立国際電気
試験システム
26日前
リオン株式会社
マイクロホン
2か月前
シャープ株式会社
転倒防止器具
2か月前
リオン株式会社
補聴器システム
9日前
シャープ株式会社
転倒防止器具
2か月前
デュプロ精工株式会社
シート撮影装置
2か月前
続きを見る
他の特許を見る
 特許ウォッチ
特許ウォッチ