TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025175589
公報種別
公開特許公報(A)
公開日
2025-12-03
出願番号
2024081768
出願日
2024-05-20
発明の名称
音声認識装置、音声認識方法、及びプログラム
出願人
本田技研工業株式会社
代理人
個人
,
個人
,
個人
主分類
G10L
15/065 20130101AFI20251126BHJP(楽器;音響)
要約
【課題】出現頻度の低い単語や句、文を簡易に登録することが可能なE2E-ASRモデルを利用することにより、音声認識の精度を更に向上させることができる音声認識装置、音声認識方法、及びプログラムを提供する。
【解決手段】音声認識装置は、発話のオーディオデータを取得する取得部と、自動音声認識モデルを用いて、前記オーディオデータからテキストを生成する音声認識部と、を備える。前記自動音声認識モデルは、オーディオデータを特徴に変換するオーディオエンコーダと、登録されたバイアストークンを特徴に変換するバイアスエンコーダと、バイアストークンに対応するように拡張されたバイアスデコーダであって、オーディオエンコーダによって出力された特徴と、バイアスエンコーダによって出力された特徴と、以前に推定されたトークン列とに基づいて、次のトークンを推定するバイアスデコーダと、を有する。
【選択図】図3
特許請求の範囲
【請求項1】
発話のオーディオデータを取得する取得部と、
自動音声認識モデルを用いて、前記オーディオデータからテキストを生成する音声認識部と、を備え、
前記自動音声認識モデルは、
前記オーディオデータの特徴を並べた第1特徴列を、第2特徴列に変換する第1エンコーダと、
予め登録されたワード、フレーズ、及びセンテンスのいずれか又は組み合わせを第1トークンとして登録し、前記第1トークンを並べた第1トークン列を、第3特徴列に変換する第2エンコーダと、
前記第1トークンに対応するように拡張されたデコーダであって、前記第2特徴列と、前記第3特徴列と、前記テキストとして以前に推定された前記第1トークンと異なる第2トークン及び/又は前記第1トークンを並べた第2トークン列とに基づいて、前記第2トークン列の後に続く前記第2トークン又は前記第1トークンを推定するデコーダと、を有する、
音声認識装置。
続きを表示(約 1,700 文字)
【請求項2】
前記デコーダは、前記第1トークンに対応するように拡張された埋め込み層を有し、
前記埋め込み層は、
前記第2トークン列のなかに前記第1トークンが含まれるか否かを判定し、
前記第2トークン列のなかに前記第1トークンが含まれない場合、前記第2トークン列を第4特徴列に変換し、
前記第2トークン列のなかに前記第1トークンが含まれる場合、前記第1トークンを除いた残りの前記第2トークン列を前記第4特徴列に変換し、前記第3特徴列に含まれる複数の第3特徴のうち、前記第2トークン列のなかに含まれる前記第1トークンに対応する前記第3特徴と、前記第1トークンを除いた残りの前記第2トークン列から変換された前記第4特徴列とを結合させた第5特徴列を生成する、
請求項1に記載の音声認識装置。
【請求項3】
前記デコーダは、前記第1トークンに対応するように拡張された出力層を有し、
前記出力層は、
前記第4特徴列又は前記第5特徴列を、第6特徴列に変換し、
前記第6特徴列と前記第1トークン列との内積に基づいて、前記第1トークンのスコアである第1スコアを算出し、
前記第2トークン列に含まれるそれぞれの前記第2トークンのスコアである第2スコアを算出し、
前記第1スコアと前記第2スコアとに基づいて、前記第2トークン列の後に続く前記第2トークン又は前記第1トークンの確率を算出する、
請求項2に記載の音声認識装置。
【請求項4】
ユーザが操作可能な入力インターフェースを更に備え、
前記音声認識部は、前記入力インターフェースに対して前記ユーザが入力した前記ワード、前記フレーズ、及び前記センテンスのいずれか又は組み合わせを、前記第1トークンとして登録する、
請求項1又は2に記載の音声認識装置。
【請求項5】
コンピュータを用いた音声認識方法であって、
発話のオーディオデータを取得すること、
自動音声認識モデルを用いて、前記オーディオデータからテキストを生成すること、を含み、
前記自動音声認識モデルは、
前記オーディオデータの特徴を並べた第1特徴列を、第2特徴列に変換する第1エンコーダと、
予め登録されたワード、フレーズ、及びセンテンスのいずれか又は組み合わせを第1トークンとして登録し、前記第1トークンを並べた第1トークン列を、第3特徴列に変換する第2エンコーダと、
前記第1トークンに対応するように拡張されたデコーダであって、前記第2特徴列と、前記第3特徴列と、前記テキストとして以前に推定された前記第1トークンと異なる第2トークン及び/又は前記第1トークンを並べた第2トークン列とに基づいて、前記第2トークン列の後に続く前記第2トークン又は前記第1トークンを推定するデコーダと、を有する、
音声認識方法。
【請求項6】
コンピュータに実行させるためのプログラムであって、
発話のオーディオデータを取得すること、
自動音声認識モデルを用いて、前記オーディオデータからテキストを生成すること、を含み、
前記自動音声認識モデルは、
前記オーディオデータの特徴を並べた第1特徴列を、第2特徴列に変換する第1エンコーダと、
予め登録されたワード、フレーズ、及びセンテンスのいずれか又は組み合わせを第1トークンとして登録し、前記第1トークンを並べた第1トークン列を、第3特徴列に変換する第2エンコーダと、
前記第1トークンに対応するように拡張されたデコーダであって、前記第2特徴列と、前記第3特徴列と、前記テキストとして以前に推定された前記第1トークンと異なる第2トークン及び/又は前記第1トークンを並べた第2トークン列とに基づいて、前記第2トークン列の後に続く前記第2トークン又は前記第1トークンを推定するデコーダと、を有する、
プログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識装置、音声認識方法、及びプログラムに関する。
続きを表示(約 2,300 文字)
【背景技術】
【0002】
音声認識技術において、従来のDNN(Deep Neural Network)-HMM(Hidden Markov Model)モデルに代わり、End-to-End(E2E)モデルが注目されている。DNN-HMMモデルでは、音響モデルと言語モデルをカスケードに接続して処理を行うため、誤差が蓄積されるという課題があった。一方、E2Eモデルは、音声特徴量から直接テキストを出力するため、全体最適され、認識率が向上することが報告されている。
【先行技術文献】
【特許文献】
【0003】
特表2021-501376号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら従来のE2Eモデルでは、辞書を用いていないため、人名などの出現頻度の低い語を認識させるためにはモデル全体を再学習させる必要があり、簡易に人名や用語などを登録することができなかった。
【0005】
本発明は、このような事情を考慮してなされたものであり、出現頻度の低い単語や句、文を簡易に登録することが可能なE2E-ASRモデルを利用することにより、音声認識の精度を更に向上させることができる音声認識装置、音声認識方法、及びプログラムを提供することを目的の一つとする。
【課題を解決するための手段】
【0006】
本発明に係る音声認識装置、音声認識方法、及びプログラムは以下の構成を採用した。
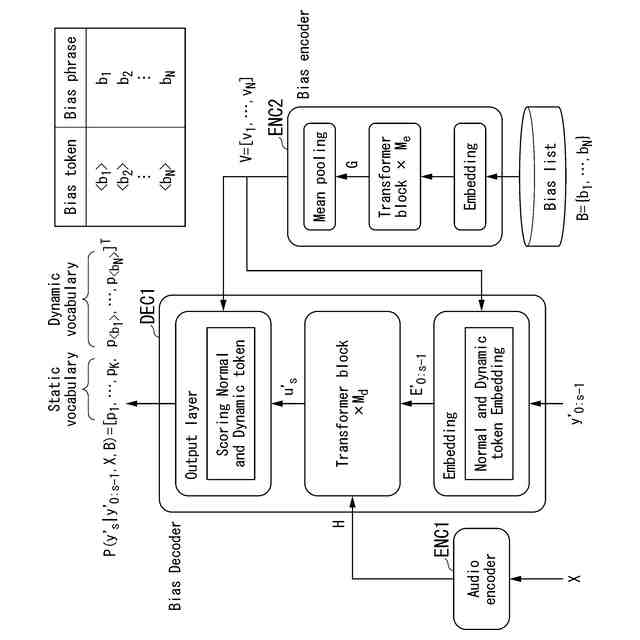
(1)本発明の第1の例は、発話のオーディオデータを取得する取得部と、自動音声認識モデルを用いて、前記オーディオデータからテキストを生成する音声認識部と、を備え、前記自動音声認識モデルは、前記オーディオデータの特徴を並べた第1特徴列を、第2特徴列に変換する第1エンコーダと、予め登録されたワード、フレーズ、及びセンテンスのいずれか又は組み合わせを第1トークンとして登録し、前記第1トークンを並べた第1トークン列を、第3特徴列に変換する第2エンコーダと、前記第1トークンに対応するように拡張されたデコーダであって、前記第2特徴列と、前記第3特徴列と、前記テキストとして以前に推定された前記第1トークンと異なる第2トークン及び/又は前記第1トークンを並べた第2トークン列とに基づいて、前記第2トークン列の後に続く前記第2トークン又は前記第1トークンを推定するデコーダと、を有する音声認識装置である。
【0007】
(2)本発明の第2の例は、第1の例において、前記デコーダは、前記第1トークンに対応するように拡張された埋め込み層を有し、前記埋め込み層は、前記第2トークン列のなかに前記第1トークンが含まれるか否かを判定し、前記第2トークン列のなかに前記第1トークンが含まれない場合、前記第2トークン列を第4特徴列に変換し、前記第2トークン列のなかに前記第1トークンが含まれる場合、前記第1トークンを除いた残りの前記第2トークン列を前記第4特徴列に変換し、前記第3特徴列に含まれる複数の第3特徴のうち、前記第2トークン列のなかに含まれる前記第1トークンに対応する前記第3特徴と、前記第1トークンを除いた残りの前記第2トークン列から変換された前記第4特徴列とを結合させた第5特徴列を生成するものである。
【0008】
(3)本発明の第3の例は、第2の例において、前記デコーダは、前記第1トークンに対応するように拡張された出力層を有し、前記出力層は、前記第4特徴列又は前記第5特徴列を、第6特徴列に変換し、前記第6特徴列と前記第1トークン列との内積に基づいて、前記第1トークンのスコアである第1スコアを算出し、前記第2トークン列に含まれるそれぞれの前記第2トークンのスコアである第2スコアを算出し、前記第1スコアと前記第2スコアとに基づいて、前記第2トークン列の後に続く前記第2トークン又は前記第1トークンの確率を算出するものである。
【0009】
(4)本発明の第4の例は、第1の例又は第2の例において、ユーザが操作可能な入力インターフェースを更に備え、前記音声認識部は、前記入力インターフェースに対して前記ユーザが入力した前記ワード、前記フレーズ、及び前記センテンスのいずれか又は組み合わせを、前記第1トークンとして登録するものである。
【0010】
(5)本発明の第5の例は、コンピュータを用いた音声認識方法であって、発話のオーディオデータを取得すること、自動音声認識モデルを用いて、前記オーディオデータからテキストを生成すること、を含み、前記自動音声認識モデルは、前記オーディオデータの特徴を並べた第1特徴列を、第2特徴列に変換する第1エンコーダと、予め登録されたワード、フレーズ、及びセンテンスのいずれか又は組み合わせを第1トークンとして登録し、前記第1トークンを並べた第1トークン列を、第3特徴列に変換する第2エンコーダと、前記第1トークンに対応するように拡張されたデコーダであって、前記第2特徴列と、前記第3特徴列と、前記テキストとして以前に推定された前記第1トークンと異なる第2トークン及び/又は前記第1トークンを並べた第2トークン列とに基づいて、前記第2トークン列の後に続く前記第2トークン又は前記第1トークンを推定するデコーダと、を有する、音声認識方法である。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
本田技研工業株式会社
車両
1か月前
本田技研工業株式会社
車両
1か月前
本田技研工業株式会社
車両
1か月前
本田技研工業株式会社
固体電池
1か月前
本田技研工業株式会社
排気装置
1か月前
本田技研工業株式会社
除草装置
1か月前
本田技研工業株式会社
排気装置
1か月前
本田技研工業株式会社
制御装置
1か月前
本田技研工業株式会社
排気装置
1か月前
本田技研工業株式会社
内燃機関
1か月前
本田技研工業株式会社
触媒装置
1か月前
本田技研工業株式会社
二次電池
1か月前
本田技研工業株式会社
固体電池
1か月前
本田技研工業株式会社
発電セル
1か月前
本田技研工業株式会社
回転電機
1日前
本田技研工業株式会社
電気機器
1か月前
本田技研工業株式会社
全固体電池
1か月前
本田技研工業株式会社
電動船外機
1か月前
本田技研工業株式会社
鞍乗型車両
1か月前
本田技研工業株式会社
鞍乗型車両
1か月前
本田技研工業株式会社
リアクトル
1か月前
本田技研工業株式会社
全固体電池
1か月前
本田技研工業株式会社
鞍乗型車両
1か月前
本田技研工業株式会社
電極積層体
1か月前
本田技研工業株式会社
鞍乗り型車両
1か月前
本田技研工業株式会社
電池製造装置
1か月前
本田技研工業株式会社
燃料電池構造
1か月前
本田技研工業株式会社
始動制御装置
1か月前
本田技研工業株式会社
燃料電池装置
1か月前
本田技研工業株式会社
始動制御装置
1か月前
本田技研工業株式会社
車両制御装置
1か月前
本田技研工業株式会社
作業システム
1か月前
本田技研工業株式会社
冷却液タンク
6日前
本田技研工業株式会社
移動システム
1か月前
本田技研工業株式会社
蓄電システム
8日前
本田技研工業株式会社
遊戯システム
1か月前
続きを見る
他の特許を見る
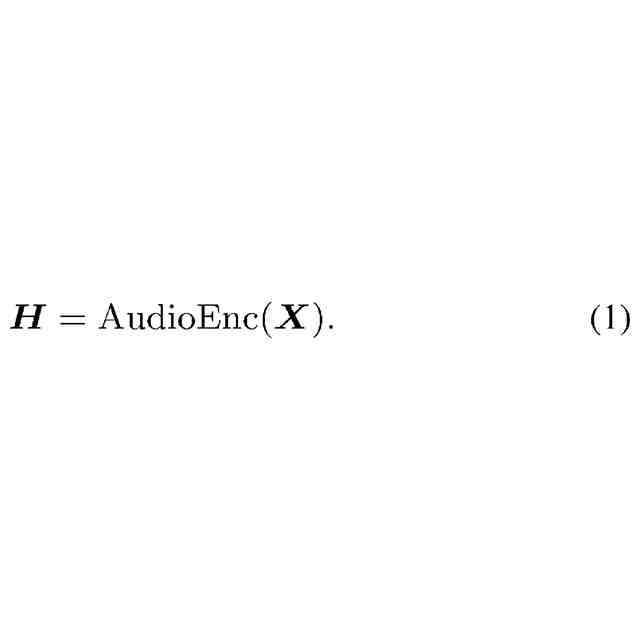
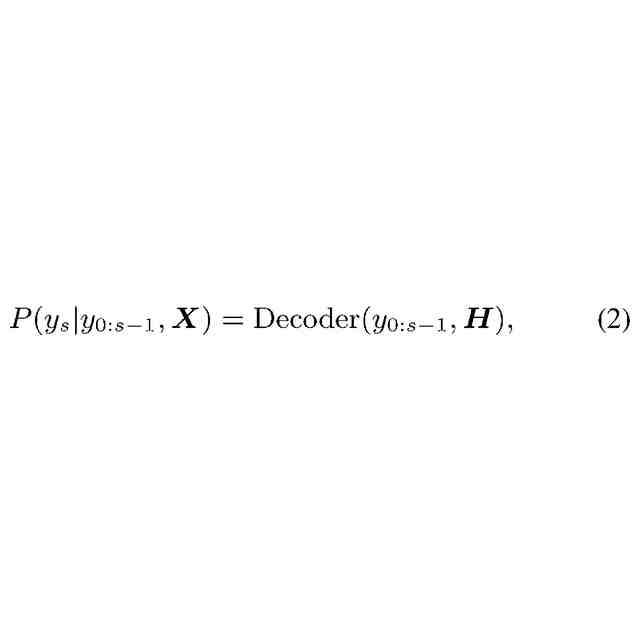


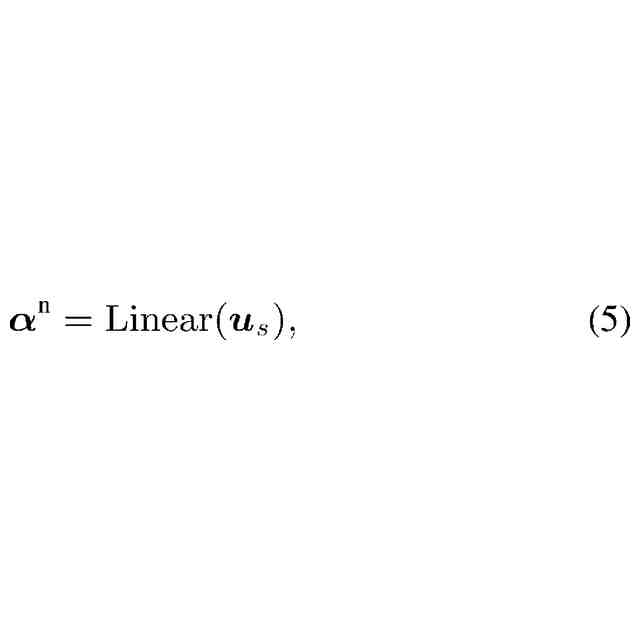


 特許ウォッチ
特許ウォッチ