TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
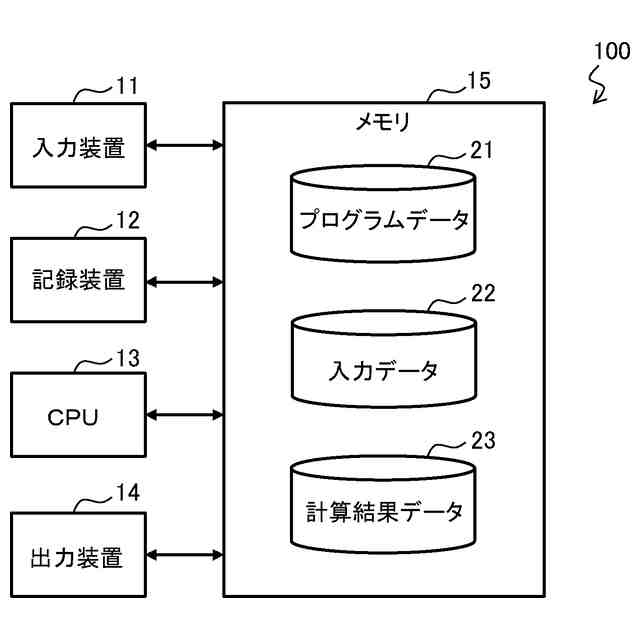
公開番号
2025008642
公報種別
公開特許公報(A)
公開日
2025-01-20
出願番号
2023110975
出願日
2023-07-05
発明の名称
クラスタ分析装置、および、クラスタ分析方法
出願人
株式会社日立製作所
代理人
弁理士法人磯野国際特許商標事務所
主分類
G06F
18/23213 20230101AFI20250109BHJP(計算;計数)
要約
【課題】入力条件の精度に影響されず、高い出力精度のクラスタを出力可能な非階層クラスタ分析を提供すること。
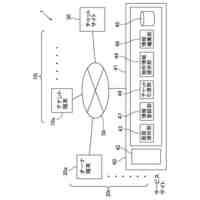
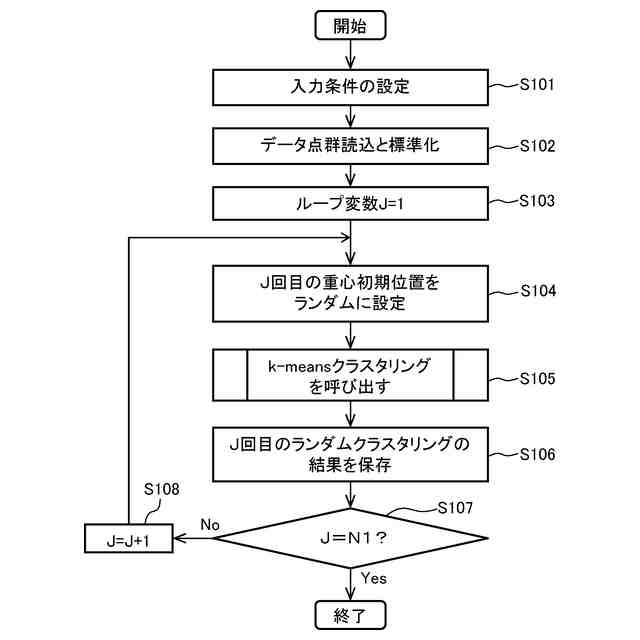
【解決手段】クラスタ分析装置100のCPU13は、各回ランダムに設定した重心初期位置を第1入力条件として、複数回の非階層クラスタ分析を実行することで、複数のランダムクラスタを取得し、複数のランダムクラスタに共通して所属するデータ点群をもとに共通クラスタを形成し、その共通クラスタの数と、各共通クラスタに所属するデータ点群の重心初期位置とを第2入力条件として作成し、作成した第2入力条件をもとに非階層クラスタ分析を実行することで取得した出力クラスタを出力する。
【選択図】 図1
特許請求の範囲
【請求項1】
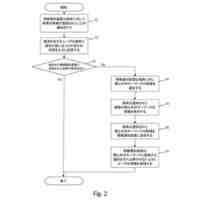
クラスタ分析装置は、データ点群をクラスタに分類する非階層クラスタ分析を実行する処理部を有しており、
前記処理部は、
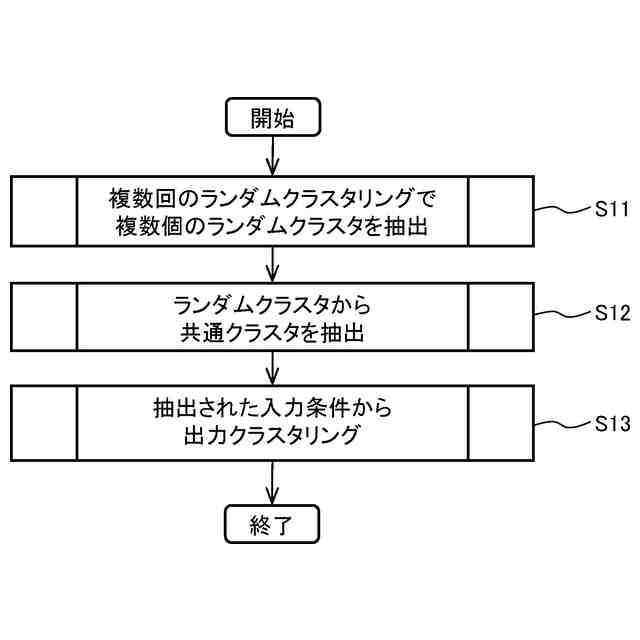
各回ランダムに設定した重心初期位置を第1入力条件として、複数回の前記非階層クラスタ分析を実行することで、複数の第1クラスタを取得し、
前記複数の第1クラスタに共通して所属する前記データ点群をもとに共通クラスタを形成し、その共通クラスタの数と、前記各共通クラスタに所属する前記データ点群の重心初期位置とを第2入力条件として作成し、
作成した前記第2入力条件をもとに前記非階層クラスタ分析を実行することで取得した第2クラスタを出力することを特徴とする
クラスタ分析装置。
続きを表示(約 690 文字)
【請求項2】
前記処理部は、前記非階層クラスタ分析として、k-means法を用いたクラスタリングを実行することを特徴とする
請求項1に記載のクラスタ分析装置。
【請求項3】
前記処理部は、前記複数の第1クラスタから前記共通クラスタを形成する処理において、前記複数の第1クラスタ間の類似度が所定値よりも低い場合には、その複数の第1クラスタ間の前記共通クラスタを形成対象から除外することを特徴とする
請求項1に記載のクラスタ分析装置。
【請求項4】
前記処理部は、母集団の中心極限定理から母平均の信頼区間を用いることで、前記複数の第1クラスタ間の類似度を計算することを特徴とする
請求項3に記載のクラスタ分析装置。
【請求項5】
クラスタ分析装置は、データ点群をクラスタに分類する非階層クラスタ分析を実行する処理部を有しており、
前記処理部は、
各回ランダムに設定した重心初期位置を第1入力条件として、複数回の前記非階層クラスタ分析を実行することで、複数の第1クラスタを取得するステップと、
前記複数の第1クラスタに共通して所属する前記データ点群をもとに共通クラスタを形成し、その共通クラスタの数と、前記各共通クラスタに所属する前記データ点群の重心初期位置とを第2入力条件として作成するステップと、
作成した前記第2入力条件をもとに前記非階層クラスタ分析を実行することで取得した第2クラスタを出力するステップとを実行することを特徴とする
クラスタ分析方法。
発明の詳細な説明
【技術分野】
【0001】
本発明は、クラスタ分析装置、および、クラスタ分析方法に関する。
続きを表示(約 1,800 文字)
【背景技術】
【0002】
クラスタ分析は、複数のサンプル(データ点群)が与えられると、類似性を持った集合(クラスタ)に分類する手法であり、ビックデータの解析などに有用である。クラスタ分析の手法は、以下の2種類が代表的である。
・階層クラスタ分析は、データ点群から最も近いデータ同士でクラスタを形成し、徐々にクラスタの数を少なくしていく手法である。
・非階層クラスタ分析は、最終的なクラスタ数を決めてから、自動的にグルーピングを行う手法である。
【0003】
非階層クラスタ分析の1つであるk-means法を用いたクラスタリング(以下「k-meansクラスタリング」)を用いる場合は、分類後のクラスタ数と、各クラスタの重心初期位置(以下「重心初期位置」)とが入力条件(初期条件)として指定される。また、特許文献1には、クラスタを構成するデータ数の下限値のみを入力条件として指定するクラスタ分析装置が記載されている。
【先行技術文献】
【特許文献】
【0004】
特開2005-222138号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
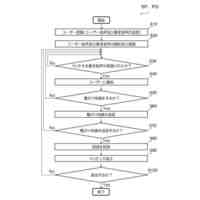
k-meansクラスタリングなどの非階層クラスタ分析は、入力条件の良し悪しによって、出力されるクラスタの精度が大きく変動する。よって、ユーザは、個別のデータ点群に適した入力条件を試行錯誤で設定する手間がかかっていた。
【0006】
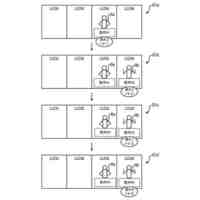
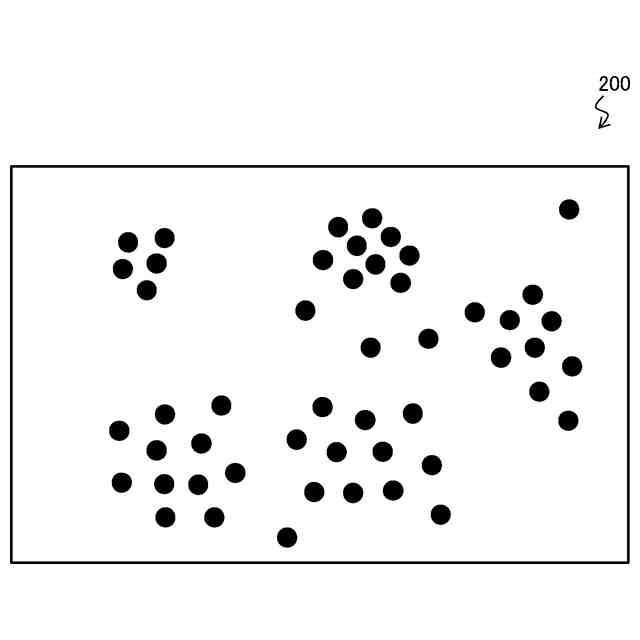
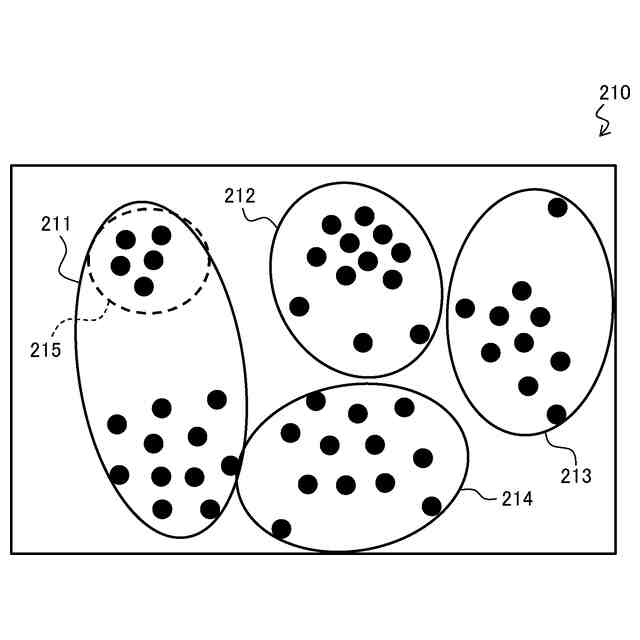
図13は、k-meansクラスタリングの対象となるデータ点群が配置されたデータ空間の説明図である。
データ点群300は、黒丸で図示する各データ点が、データ空間内に点在する集合体である。
【0007】
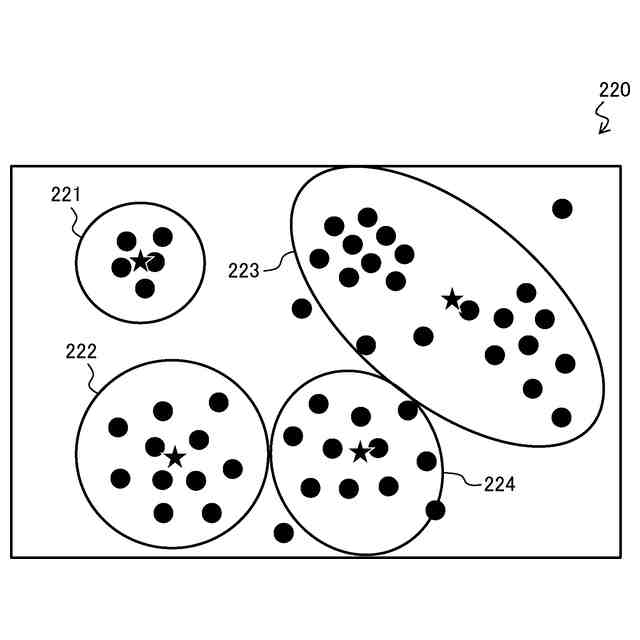
図14は、図13のデータ点群300に対するk-meansクラスタリングの結果の第1例を示す説明図である。
クラスタ数=3の入力条件に従い、クラスタリング結果310のデータ点群を構成する各データ点は、各クラスタ311,312,313のいずれかに含まれる。また、入力条件として指定された各クラスタ重心の重心初期位置311H,312H,313Hが、互いにほぼ等距離の間隔で適切な位置である。
よって、重心初期位置311Hから形成されるクラスタ311と、重心初期位置312Hから形成されるクラスタ312と、重心初期位置313Hから形成されるクラスタ313とは、それぞれクラスタ間でのデータ点数のバラツキが少なく、良好な結果と言える。
【0008】
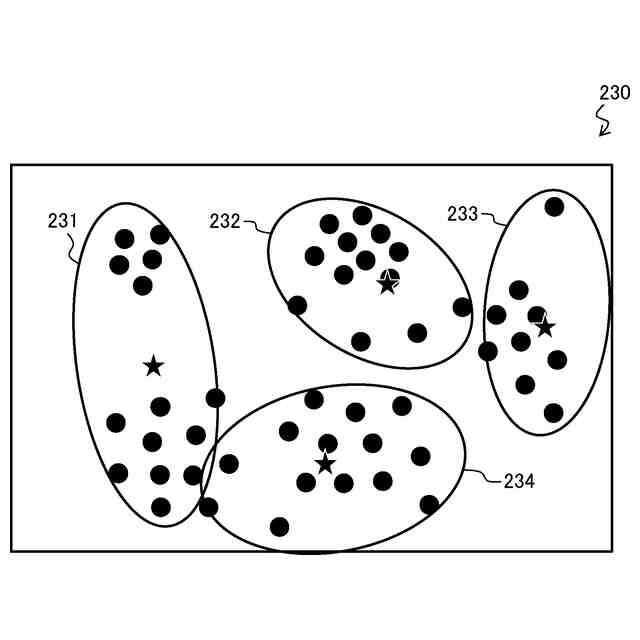
図15は、図13のデータ点群300に対するk-meansクラスタリングの結果の第2例を示す説明図である。
クラスタ数=3の入力条件に従い、クラスタリング結果320のデータ点群を構成する各データ点は、各クラスタ321,322,323のいずれかに含まれる。しかし、入力条件として指定された各クラスタ重心の重心初期位置321H,322H,323Hの配置に偏りがあり、重心初期位置322H,323H間の距離が短すぎる。
よって、クラスタ321はデータ数が多すぎる一方、クラスタ322はデータ数が少ないので、不良な結果と言える。
【0009】
このように、k-meansクラスタリングという同じ手法を用いても出力精度がばらつくので、その入力条件の精度に精度されないような非階層クラスタ分析の手法が求められる。しかし、従来のk-meansクラスタリングでは、各クラスタの重心初期位置を入力条件にする必要上、入力条件の精度に左右されてしまう。
また、特許文献1の手法では、各クラスタの重心初期位置は入力条件として求められないが、代わりにクラスタを構成するデータ数の下限値を入力条件にする必要上、入力条件の精度に左右されてしまう。例えば、入力条件であるデータ数の下限値よりも1つ少ないクラスタの個数が多く形成できるようなデータ点群では、うまくクラスタを形成できない。
【0010】
そこで、本発明は、入力条件の精度に影響されず、高い出力精度のクラスタを出力可能な非階層クラスタ分析を提供することを、主な課題とする。
【課題を解決するための手段】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
情報提示方法
10日前
個人
プログラム
2日前
個人
プログラム
9日前
個人
アカウントマップ
3日前
個人
自動精算システム
18日前
個人
売買システム
24日前
個人
市場受発注システム
16日前
個人
発想支援方法及びシステム
13日前
日本精機株式会社
車両用表示装置
26日前
個人
分類処理プログラム及び方法
13日前
個人
学習装置及び推論装置
2日前
日本精機株式会社
車両用表示装置
26日前
井関農機株式会社
ロボット作業車両
18日前
富士通株式会社
金融システム
10日前
株式会社プレニーズ
仲介システム
3日前
トヨタ自動車株式会社
作業評価装置
25日前
トヨタ自動車株式会社
作業管理装置
16日前
村田機械株式会社
人員配置システム
13日前
トヨタ自動車株式会社
情報通知方法
16日前
ブラザー工業株式会社
無線通信装置
16日前
個人
販売支援システム
18日前
トヨタ自動車株式会社
生成装置
10日前
AICRO株式会社
情報処理システム
16日前
NISSHA株式会社
入力装置
13日前
株式会社mov
情報処理システム
26日前
株式会社半導体エネルギー研究所
検索システム
16日前
斎久工業株式会社
衛生設備管理システム
17日前
中国電力株式会社
業務依頼支援システム
18日前
中国電力株式会社
要領書作成支援システム
13日前
株式会社野村総合研究所
寄付支援システム
9日前
東京瓦斯株式会社
環境教育システム
9日前
トヨタ自動車株式会社
文字認識装置
16日前
ミサワホーム株式会社
リフォーム支援装置
25日前
トヨタ自動車株式会社
情報処理装置
13日前
株式会社Starl
ポイント管理システム
9日前
株式会社パークアシスト
情報伝送システム
13日前
続きを見る
他の特許を見る
 特許ウォッチ
特許ウォッチ