TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2024163549
公報種別
公開特許公報(A)
公開日
2024-11-22
出願番号
2023079271
出願日
2023-05-12
発明の名称
情報処理デバイス、情報処理システムおよび情報処理方法
出願人
株式会社日立製作所
代理人
弁理士法人第一国際特許事務所
主分類
G06N
20/00 20190101AFI20241115BHJP(計算;計数)
要約
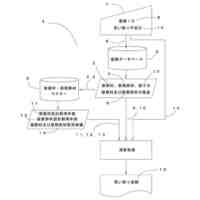
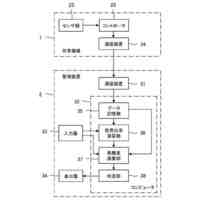
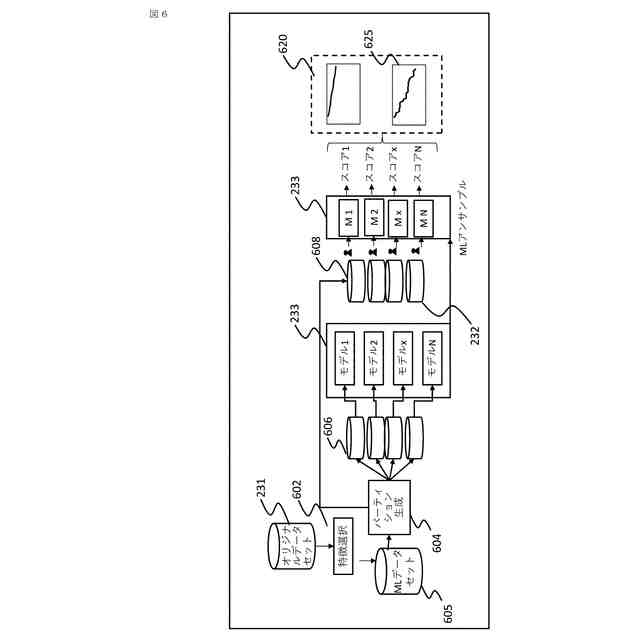
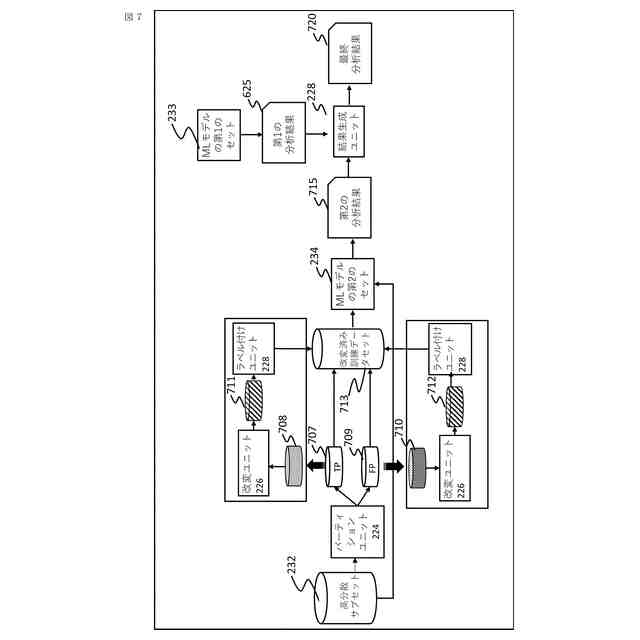
【課題】小さいサンプルサイズを有するデータセットで高信頼性の結果を生成可能な高堅牢度を有する機械学習モデルを生成する情報処理デバイスを提供する。
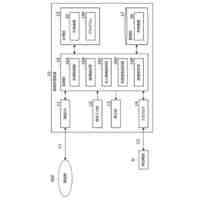
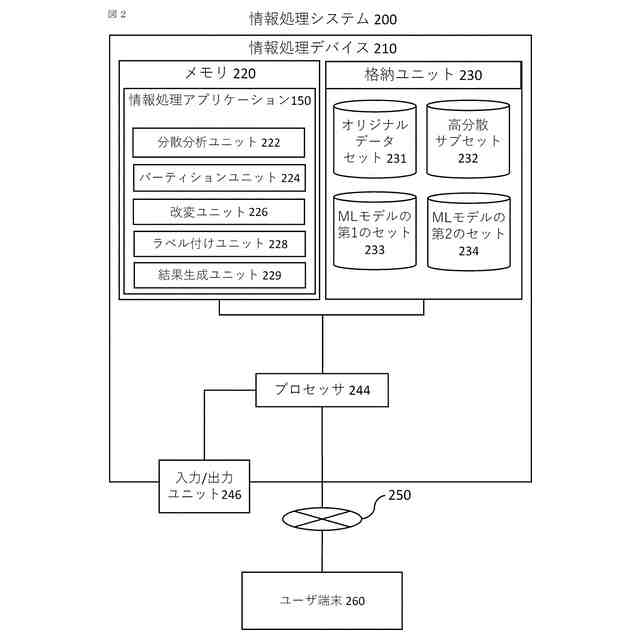
【解決手段】情報処理デバイスは、オリジナルデータセットについての分析結果を生成し、分散閾値に達する第1の分析結果と関連付けられたオリジナルデータセットの内から主体(患者や機械部品など)の第1のセットを識別する分散分析ユニットと、主体の第1のセットをオリジナルデータパーティションに分割し、コピー済みデータパーティションを生成するパーティションユニットと、改変済みコピーデータパーティションを生成する改変ユニットと、オリジナルデータパーティション及び改変済みコピーデータパーティションを使用して機械学習モデルを訓練し、その機械学習モデルを使用して第2の分析結果を生成し、各分析結果を集約することで最終分析結果を生成する結果生成ユニットと、を含む。
【選択図】図2
特許請求の範囲
【請求項1】
プロセッサと、
前記プロセッサによって実行可能なコンピュータ実施可能命令を含むメモリと、
を備える情報処理デバイスであって、
前記コンピュータ実施可能命令は、前記プロセッサに、
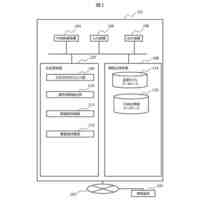
機械学習モデルの第1のセットを用いてオリジナルデータセットを処理することによって、分析結果のセットを生成することと、
分析結果の前記セットに基づいて、分散閾値に達する第1の分析結果と関連付けられた主体の第1のセットを含む前記オリジナルデータセットの高分散サブセットを識別することと、
を行うように構成される分散分析ユニットと、
前記高分散サブセットの主体の前記第1のセットを第1のデータパーティションおよび第2のデータパーティションに分割することと、
前記第1のデータパーティションのコピーである第3のデータパーティションと、前記第2のデータパーティションのコピーである第4のデータパーティションとを生成することと、
を行うように構成されるパーティションユニットと、
前記第3のデータパーティションを改変することによって改変済み第3のデータパーティション、および前記第4のデータパーティションを改変することによって改変済み第4のデータパーティションを生成することを行うように構成される改変ユニットと、
前記第1のデータパーティション、前記第2のデータパーティション、前記改変済み第3のデータパーティション、および前記改変済み第4のデータパーティションを使用して、機械学習モデルの第2のセットを訓練することと、
機械学習モデルの前記第2のセットを用いて前記オリジナルデータセットを処理することによって、第2の分析結果を生成することと、
前記第1の分析結果と前記第2の分析結果とを集約して分類することによって前記高分散サブセットの主体の前記第1のセットについての最終分析結果を生成することと、
を行うように構成される結果生成ユニットと、
として機能させる、情報処理デバイス。
続きを表示(約 3,400 文字)
【請求項2】
前記改変ユニットは、
ノイズレベル基準に基づいて、第1のノイズ量を前記第3のデータパーティションの特徴の第3のセットに付加することによって前記改変済み第3のデータパーティションを生成することと、
前記ノイズレベル基準に基づいて、第2のノイズ量を前記第4のデータパーティションの特徴の第4のセットに付加することによって前記改変済み第4のデータパーティションを生成することと、
を行うように構成される、請求項1に記載の情報処理デバイス。
【請求項3】
前記改変ユニットは、
機械学習モデルの前記第2のセットを使用して、増加するノイズ量が付加された改変済みサンプルデータセットを繰り返し処理することによって、サンプル予測結果のセットを生成することと、
サンプル予測結果の前記セットから、所定の正確率閾値を満たすサンプル予測結果のサブセットを識別することと、
前記ノイズレベル基準として、前記所定の正確率閾値を満たすサンプル予測結果の前記サブセットと関連付けられた前記改変済みサンプルデータセットに対して付加された最大ノイズ量を決定することと、
を行うように構成される、請求項2に記載の情報処理デバイス。
【請求項4】
前記パーティションユニットは、
前記第1の分析結果を、前記オリジナルデータセットについてのグラウンドトゥルース結果に対して比較することによって前記第1の分析結果の正確率を評価することと、
真陽性結果と関連付けられた主体の前記第1のセットの第1のサブセットを前記第1のデータパーティションに分割することと、
偽陽性結果と関連付けられた主体の前記第1のセットの第2のサブセットを前記第2のデータパーティションに分割することと、
を行うように構成される、請求項1に記載の情報処理デバイス。
【請求項5】
前記改変済み第3のデータパーティションおよび前記改変済み第4のデータパーティションに対して真陽性または偽陽性のアウトカムラベルを割り当てるためのラベル付けユニット
をさらに備える、請求項1に記載の情報処理デバイス。
【請求項6】
前記ラベル付けユニットは、
前記第1のデータパーティションの主体の第1のサブセットと前記改変済み第3のデータパーティションの主体の第3のサブセットとの間の第1の類似度を計算し、
前記第1の類似度が類似度閾値に達する場合、真陽性結果ラベルを主体の前記第3のサブセットに割り当て、
前記第1の類似度が類似度閾値に達しない場合、偽陽性結果ラベルを主体の前記第3のサブセットに割り当て、
前記第2のデータパーティションの主体の第2のサブセットと前記改変済み第4のデータパーティションの主体の第4のサブセットとの間の第2の類似度を計算し、
前記第2の類似度が類似度閾値に達する場合、偽陽性結果ラベルを主体の前記第4のサブセットに割り当て、
前記第2の類似度が類似度閾値に達しない場合、真陽性結果ラベルを主体の前記第4のサブセットに割り当てる、
請求項5に記載の情報処理デバイス。
【請求項7】
情報処理デバイスと、
ユーザ端末と、
を備える情報処理システムであって、
前記情報処理デバイスは、
プロセッサと、
前記プロセッサによって実行可能なコンピュータ実施可能命令を含むメモリとを含み、前記コンピュータ実施可能命令は、前記プロセッサに、
機械学習モデルの第1のセットを用いてオリジナルデータセットを処理することによって、分析結果のセットを生成することと、
分析結果の前記セットに基づいて、分散閾値に達する第1の分析結果と関連付けられた主体の第1のセットを含む前記オリジナルデータセットの高分散サブセットを識別することと、
を行うように構成される分散分析ユニットと、
前記高分散サブセットの主体の前記第1のセットを第1のデータパーティションおよび第2のデータパーティションに分割することと、
前記第1のデータパーティションのコピーである第3のデータパーティションと、前記第2のデータパーティションのコピーである第4のデータパーティションとを生成することと、
を行うように構成されるパーティションユニットと、
前記第3のデータパーティションを改変することによって改変済み第3のデータパーティション、および前記第4のデータパーティションを改変することによって改変済み第4のデータパーティションを生成することを行うように構成される改変ユニットと、
前記第1のデータパーティション、前記第2のデータパーティション、前記改変済み第3のデータパーティション、および前記改変済み第4のデータパーティションを使用して、機械学習モデルの第2のセットを訓練することと、
機械学習モデルの前記第2のセットを用いて前記オリジナルデータセットを処理することによって、第2の分析結果を生成することと、
前記第1の分析結果と前記第2の分析結果とを集約して分類することによって前記高分散サブセットの主体の前記第1のセットについての最終分析結果を生成することと、
前記最終分析結果を前記ユーザ端末に出力することと、
を行うように構成される結果生成ユニットと、
として機能させる、情報処理システム。
【請求項8】
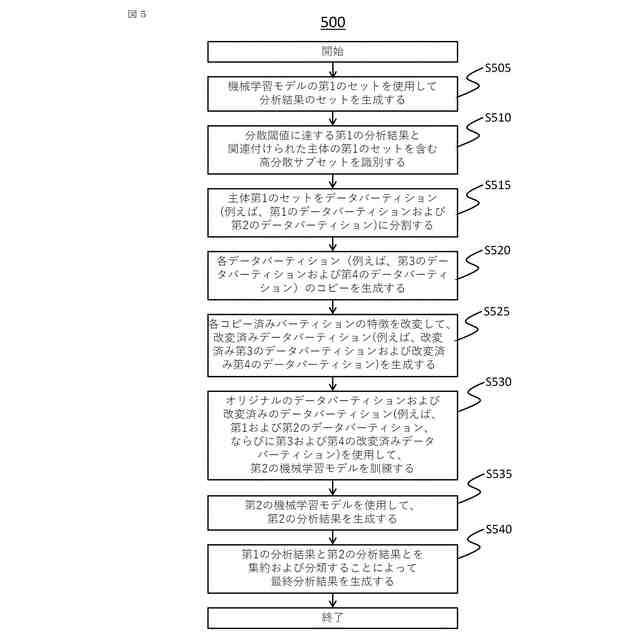
コンピュータによって実行される情報処理方法であって、前記情報処理方法は、
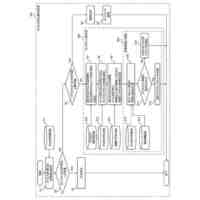
機械学習モデルの第1のセットを用いてオリジナルデータセットを処理することによって、分析結果のセットを生成するステップと、
分析結果の前記セットに基づいて、分散閾値に達する第1の分析結果と関連付けられた主体の第1のセットを含む前記オリジナルデータセットの高分散サブセットを識別するステップと、
前記高分散サブセットの主体の前記第1のセットを第1のデータパーティションおよび第2のデータパーティションに分割するステップと、
前記第1のデータパーティションのコピーである第3のデータパーティションと、前記第2のデータパーティションのコピーである第4のデータパーティションとを生成するステップと、
機械学習モデルのテストセットを使用して、増加するノイズ量が付加された改変済みサンプルデータセットを繰り返し処理することによって、サンプル予測結果のセットを生成するステップと、
サンプル予測結果の前記セットから、所定の正確率閾値を満たすサンプル予測結果のサブセットを識別するステップと、
ノイズレベル基準として、前記所定の正確率閾値を満たすサンプル予測結果の前記サブセットと関連付けられた前記改変済みサンプルデータセットに対して付加された最大ノイズ量を決定するステップと、
前記ノイズレベル基準に基づいて、第1のノイズ量を前記第3のデータパーティションの特徴の第3のセットに付加することによって改変済み第3のデータパーティションを生成するステップと、
前記ノイズレベル基準に基づいて、第2のノイズ量を前記第4のデータパーティションの特徴の第4のセットに付加することによって改変済み第4のデータパーティションを生成するステップと、
前記第1のデータパーティション、前記第2のデータパーティション、前記改変済み第3のデータパーティション、および前記改変済み第4のデータパーティションを使用して、機械学習モデルの第2のセットを訓練するステップと、
機械学習モデルの前記第2のセットを用いて前記オリジナルデータセットを処理することによって、第2の分析結果を生成するステップと、
前記第1の分析結果と前記第2の分析結果とを集約して分類することによって前記高分散サブセットの主体の前記第1のセットについての最終分析結果を生成するステップと、
を含む情報処理方法。
発明の詳細な説明
【技術分野】
【0001】
本開示は、情報処理デバイス、情報処理方法、および情報処理システムに関する。
続きを表示(約 2,400 文字)
【背景技術】
【0002】
近年、機械学習技術は、幅広い分野への適用のために開発されている。機械学習では、既知のケースに基づく訓練データがコンピュータに入力される。コンピュータは、訓練データを解析して、因子(説明変数または独立変数と呼ばれる場合がある)とアウトカム(目的変数または従属変数と呼ばれる場合がある)との間の関係を汎化するモデルを学習する。このモデルは、次いで、未知のケースに対する結果を予測するために使用され得る。一例として、類似患者についての過去の医学的介入履歴および患者特性を含むデータに基づいて異なる医学的介入を受ける患者の生存性を予測するモデルを生成することが可能である。
【0003】
従来、機械学習技術の性能を改善する技法が考えられてきた。
例えば、特許文献1は、「改訂されたサポートベクタマシン(SVM)クラシファイアは、音声認識システムのキーワードスポッティングコンポーネントからの出力に基づいて真のキーワードと偽陽性とを区別するように提供される。SVMは、特徴次元の縮小セットに対して動作し、この特徴次元は、真のキーワードと偽陽性とを区別するそれらの能力に基づいて選択される。さらに、サポートベクタ対は、再重みづけサポートベクタの縮小セットを作成するために統合される。これらの技法は、結果として、縮小されたコンピューティングリソースを使用して動作され得るSVMをもたらし、したがってシステム性能を向上させる」という技法を開示している。
【先行技術文献】
【特許文献】
【0004】
米国特許第9600231号明細書
【発明の概要】
【発明が解決しようとする課題】
【0005】
機械学習では、生成されたモデルの正確性、すなわち未知のケースの結果を正確に予測する能力(予測性能と呼ばれる場合がある)が高いことが好ましい。因子間の関係を汎化するモデルのデータセットにおける学習可能な情報コンテンツの増加に伴って、予測性能は高まるが、比較的大きなサンプルサイズを用いて実現可能な場合が多い。従来、小さいサンプルサイズに基づくデータセットは、それぞれの結果がアウトカムおいて大きなばらつきを有するなど、予測性能の低下につながり得る。異なるアウトカム間の高分散に起因して、そのような結果は信頼性が低い場合があり、結論または洞察を引き出すには適していない。
【0006】
特許文献1は、キーワード認識のためにSVMクラシファイアを使用するための技法を提案する。より詳しくは、特許文献1の技法は、コンピューティングリソースが限られた環境におけるSVMの動作を容易にするために、特徴セットのサイズを減少させることに関する。しかしながら、特許文献1は、小さいサンプルサイズを有するデータセットにおける機械学習モデルの予測性能を改善することには関しない。
【0007】
したがって、本開示の目的は、小さいサンプルサイズを有するデータセットで高信頼性の結果を生成可能な高堅牢度を有する機械学習モデルを生成するための情報処理技法を提供することである。
【課題を解決するための手段】
【0008】
本開示の代表的な一例は、プロセッサと、プロセッサによって実行可能なコンピュータ実施可能命令を含むメモリとを含む情報処理デバイスであって、命令は、プロセッサに、機械学習モデルの第1のセットを用いてオリジナルデータセットを処理することによって、分析結果のセットを生成することと、分析結果のセットに基づいて、分散閾値に達する第1の分析結果と関連付けられた主体(例えば、患者や機械部品など)の第1のセットを含むオリジナルデータセットの高分散サブセットを識別することと、を行うように構成される分散分析ユニットと、高分散サブセットの主体の第1のセットを第1のデータパーティションおよび第2のデータパーティションに分割することと、第1のデータパーティションのコピーである第3のデータパーティションと、第2のデータパーティションのコピーである第4のデータパーティションとを生成することと、を行うように構成されるパーティションユニットと、第3のデータパーティションを改変する(例えば、ノイズを付加する)ことによって改変済み第3のデータパーティション、および第4のデータパーティションを改変することによって改変済み第4のデータパーティションを生成することを行うように構成される改変ユニットと、第1のデータパーティション、第2のデータパーティション、改変済み第3のデータパーティション、および改変済み第4のデータパーティションを使用して、機械学習モデルの第2のセットを訓練することと、機械学習モデルの第2のセットを用いてオリジナルデータセットを処理することによって、第2の分析結果を生成することと、第1の分析結果と第2の分析結果とを集約して分類することによって高分散サブセットの主体の第1のセットについての最終分析結果を生成することと、を行うように構成される結果生成ユニットと、として機能させる、情報処理デバイスに関する。
【発明の効果】
【0009】
本開示によれば、小さいサンプルサイズを有するデータセットで高信頼性の結果を生成可能な高堅牢度を有する機械学習モデルを生成するための情報処理技法を提供することが可能である。
【0010】
上述した以外の問題、構成、および効果は、本発明を実行するための実施形態における以下の記載によって明確となるであろう。
【図面の簡単な説明】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社ザメディア
出席管理システム
今日
トヨタ自動車株式会社
工程計画装置
今日
トヨタ自動車株式会社
作業判定方法
1日前
トヨタ自動車株式会社
情報処理システム
1日前
ゼネラル株式会社
RFIDタグ付き物品
2日前
個人
公益寄付インタラクティブシステム
6日前
トヨタ自動車株式会社
情報処理方法
1日前
株式会社国際電気
支援システム
2日前
ブラザー工業株式会社
ラベルプリンタ
1日前
富士通株式会社
画像生成方法
5日前
甍エンジニアリング株式会社
屋根材買い取りシステム
5日前
日立建機株式会社
作業機械の管理装置
2日前
日立建機株式会社
潤滑油診断システム
今日
株式会社日立製作所
設計支援装置
今日
トヨタ自動車株式会社
車両用の情報処理装置
今日
株式会社アイシン
情報提供システム
5日前
トヨタ自動車株式会社
車両用の情報処理装置
1日前
アルプスアルパイン株式会社
入力装置
5日前
サクサ株式会社
画像処理装置、方法、およびシステム
1日前
個人
情報処理システム、情報処理方法及びプログラム
5日前
株式会社カプコン
システム、サーバおよびプログラム
今日
キヤノン株式会社
情報処理装置
5日前
ブラザー工業株式会社
印刷装置
今日
ブラザー工業株式会社
画像形成システム
今日
株式会社アイシン
投稿感情予測システム
5日前
株式会社セルズ
情報処理システム
5日前
株式会社 ミックウェア
情報処理装置及び情報処理方法
今日
日本電気株式会社
管理装置、管理方法、及びプログラム
5日前
トヨタ自動車株式会社
姿勢検出システム及び姿勢検出方法
5日前
株式会社アイシン
物体検出装置
5日前
カシオ計算機株式会社
表示装置、表示方法及びプログラム
5日前
大和ハウス工業株式会社
プログラム、及び計測装置
1日前
KDDI株式会社
話し掛け判断装置及びプログラム
今日
株式会社JVCケンウッド
表示対象抽出装置
1日前
株式会社NTTドコモ
情報処理装置
1日前
株式会社JVCケンウッド
認識処理装置およびプログラム
1日前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ