TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025051621
公報種別
公開特許公報(A)
公開日
2025-04-04
出願番号
2024154542
出願日
2024-09-09
発明の名称
画像生成方法
出願人
富士通株式会社
代理人
弁理士法人ITOH
主分類
G06N
3/0475 20230101AFI20250327BHJP(計算;計数)
要約
【課題】 画像生成方法を提供する。
【解決手段】 方法は、入力テキスト及びレイアウト情報を受信し、前記入力テキストを1つ以上のグローバル特徴及び1つ以上のローカル特徴に分解し、前記1つ以上のグローバル特徴をグローバルベクトルに、前記1つ以上のローカル特徴をローカルベクトルに符号化し、トレーニング済みニューラルネットワーク(NN)を使用して前記グローバルベクトル及び初期画像表現からグローバルノイズを予測し、トレーニング済みNNを使用して各ローカル特徴について、前記1つ以上のローカルベクトル及び前記初期画像表現から初期ローカルノイズを予測し、前記初期ローカルノイズ及び前記グローバルノイズを使用して各ローカル特徴について最終ローカルノイズを決定し、前記レイアウト情報を使用して前記予測グローバルノイズ及び前記最終ローカルノイズを合成ノイズに合成し、前記合成ノイズを使用して前記初期画像表現をノイズ除去して次の画像表現を提供する。
【選択図】 図10
特許請求の範囲
【請求項1】
画像を生成するコンピュータ実施方法であって、
入力テキスト及びレイアウト情報を受信するステップと、
前記入力テキストを1つ以上のグローバル特徴及び1つ以上のローカル特徴に分解するステップと、
前記1つ以上のグローバル特徴をグローバルベクトルに、前記1つ以上のローカル特徴を各々ローカルベクトルに符号化するステップと、
初期画像表現を初期化するステップと、
トレーニング済みニューラルネットワークを使用して、前記グローバルベクトル及び前記初期画像表現からグローバルノイズを予測するステップと、
トレーニング済みニューラルネットワークを使用して、前記1つ以上のローカル特徴の各々について、前記1つ以上のローカルベクトル及び前記初期画像表現から初期ローカルノイズを予測するステップと、
前記初期ローカルノイズ及び前記予測されたグローバルノイズを使用して、前記1つ以上のローカル特徴の各々について最終ローカルノイズを決定するステップと、
前記レイアウト情報を使用して、前記予測されたグローバルノイズ及び前記最終ローカルノイズを結合ノイズに合成するステップと、
前記結合ノイズを使用して前記初期画像表現をノイズ除去し、前記画像を生成するための次の画像表現を提供するステップと、
を含むコンピュータ実施方法。
続きを表示(約 2,700 文字)
【請求項2】
前記レイアウト情報は、前記入力テキストで記述された1つ以上のオブジェクトの位置及びサイズ情報を含み、及び/又は、前記入力テキスト及び前記レイアウト情報は、グラフィカルユーザインタフェース(GUI)上のユーザ入力から受信され、前記レイアウト情報は、各オブジェクトのキャンバス上の境界ボックスとして入力され、前記入力テキストは、前記オブジェクトに名前を付けるために各境界ボックスに追加される1つ以上のラベルとして入力される、請求項1に記載のコンピュータ実施方法。
【請求項3】
入力テキストは、1つ以上のオブジェクトの述語を形成するためにリンクと共にラベルとして追加的に入力され、前記述語は、前記オブジェクト間の関係を与える2つのオブジェクト間のラベル付きリンク又はオブジェクトの属性に対するラベル付きリンクを含む、請求項2に記載のコンピュータ実施方法。
【請求項4】
グローバル特徴は、2つのオブジェクトを接続するグローバル述語又はオブジェクトを含み、前記グローバル述語は、前記2つのオブジェクト間の関係を定義し、ローカル特徴は、オブジェクトとそのオブジェクトの属性を定義するローカル述語とを含む、請求項1~3のいずれかに記載のコンピュータ実施方法。
【請求項5】
前記入力テキスト及びリンクはシーングラフを形成し、前記シーングラフは、すべてのオブジェクトノード及びそれらの接続をグローバル特徴を含むグローバルグラフとして抽出し、1つ以上のオブジェクトノード及び抽出された前記1つ以上のオブジェクトノードに接続される1つ以上の属性を各々ローカル特徴を含むローカルグラフとして抽出することによって、グラフ分解ユニットを使用して分解される、請求項1に記載のコンピュータ実施方法。
【請求項6】
各ローカル特徴に対する前記最終ローカルノイズは、前記ローカルベクトルの予測ノイズから前記グローバルベクトルの予測ノイズを減算し、次にローカルノイズハイパーパラメータを乗算し、前記ローカル特徴に関連する前記オブジェクトのレイアウト情報を使用して前記最終ローカルノイズを抽出することによって決定される、及び/又は、
最終グローバルノイズは、予測された前記グローバルノイズから無条件ノイズを減算し、その差をグローバルノイズハイパーパラメータで乗算し、前記無条件ノイズを加算することによって決定され、前記無条件ノイズは、前記トレーニング済みニューラルネットワークにブランクベクトル及び前記初期画像表現を入力することによって予測され、及び/又は、
前記結合ノイズは、前記最終グローバルノイズ及び前記最終ローカルノイズを加算することによって合成される、請求項1に記載のコンピュータ実施方法。
【請求項7】
前記グローバル特徴及び前記ローカル特徴は各々別のレイヤを占有し、ローカル特徴の更なる特徴は、前記ローカル特徴のレイヤに重畳される追加のレイヤを占有し、前記追加のレイヤは、前記追加のレイヤ上のノイズを決定する際に、前記ローカル特徴のレイヤ内のノイズを使用する、請求項1に記載のコンピュータ実施方法。
【請求項8】
前記入力テキストは、更に、グローバル背景に分解され、前記グローバル背景は、グローバル背景ベクトルに符号化され、グローバル背景ノイズは、トレーニング済みニューラルネットワークを使用して、前記グローバル背景ベクトル及び前記初期画像表現から予測され、結合ノイズを合成することは、予測された前記グローバル背景ノイズを合成することを更に含む、請求項1に記載のコンピュータ実施方法。
【請求項9】
コンピュータプログラムであって、コンピュータ上で実行されると、前記コンピュータに方法を実行させ、前記方法は、
入力テキスト及びレイアウト情報を受信するステップと、
前記入力テキストを1つ以上のグローバル特徴及び1つ以上のローカル特徴に分解するステップと、
前記1つ以上のグローバル特徴をグローバルベクトルに、前記1つ以上のローカル特徴を各々ローカルベクトルに符号化するステップと、
初期画像表現を初期化するステップと、
トレーニング済みニューラルネットワークを使用して、前記グローバルベクトル及び前記初期画像表現からグローバルノイズを予測するステップと、
トレーニング済みニューラルネットワークを使用して、前記1つ以上のローカル特徴の各々について、前記1つ以上のローカルベクトル及び前記初期画像表現から初期ローカルノイズを予測するステップと、
前記初期ローカルノイズ及び前記予測されたグローバルノイズを使用して、前記1つ以上のローカル特徴の各々について最終ローカルノイズを決定するステップと、
前記レイアウト情報を使用して、前記予測されたグローバルノイズ及び前記最終ローカルノイズを結合ノイズに合成するステップと、
前記結合ノイズを使用して前記初期画像表現をノイズ除去し、画像を生成するための次の画像表現を提供するステップと、
を含む、コンピュータプログラム。
【請求項10】
画像を生成する情報処理機器であって、メモリと前記メモリに結合されたプロセッサとを含み、前記プロセッサは、
入力テキスト及びレイアウト情報を受信し、
前記入力テキストを1つ以上のグローバル特徴及び1つ以上のローカル特徴に分解し、
前記1つ以上のグローバル特徴をグローバルベクトルに、前記1つ以上のローカル特徴を各々ローカルベクトルに符号化し、
初期画像表現を初期化し、
トレーニング済みニューラルネットワークを使用して、前記グローバルベクトル及び前記初期画像表現からグローバルノイズを予測し、
トレーニング済みニューラルネットワークを使用して、前記1つ以上のローカル特徴の各々について、前記1つ以上のローカルベクトル及び前記初期画像表現から初期ローカルノイズを予測し、
前記初期ローカルノイズ及び前記予測されたグローバルノイズを使用して、前記1つ以上のローカル特徴の各々について最終ローカルノイズを決定し、
前記予測されたグローバルノイズ及び前記最終ローカルノイズを結合ノイズに合成し、
前記結合ノイズを使用して前記初期画像表現をノイズ除去し、前記画像を生成するための次の画像表現を提供する、
情報処理機器。
発明の詳細な説明
【技術分野】
【0001】
本発明は、ニューラルネットワークを用いて入力テキストとレイアウト情報から画像を生成する方法に関し、更に、ニューラルネットワークを用いて入力テキストとレイアウト情報から画像を生成する機器に関する。
続きを表示(約 3,400 文字)
【背景技術】
【0002】
様々な業界の多くの企業が、広告、プレゼンテーション、ウェブコンテンツなどに使用するために、ビジネスに特定の画像を必要としている。コンピュータビジョンの分野では、画像合成は近年信じられないほどの発展を遂げているが、大きな計算要求がないわけではない。特に、ニューラルネットワークは、与えられたテキスト記述から画像を生成するために一般的になっている。
【0003】
ユーザは、生成された画像内のオブジェクトのレイアウトとオブジェクトの視覚属性(色、形、姿勢、動作)を特定の目的に合わせて制御したいと考えている。尤度ベースのモデルは、高解像度で複雑なシーンを作成するためによく使用されるが、自己回帰(autoregressive (AR))トランスフォーマで数十億ものパラメータを必要とする可能性がある。敵対的生成ネットワーク(Generative Adversarial Network (GAN))を使用しても有望な結果が得られている。しかし、GANの敵対的学習手順は、複雑なマルチモデル分布のモデリングに容易に拡張できない。更に、ARモデルもGANも、目的の画像に到達するために多くの試行錯誤を必要とする。
【0004】
最近、拡散モデルがテキスト入力に対して高品質の画像を生成することが示されている。人気のある拡散モデルには、OpenAIのDall-E2、GoogleのImagen、StabilityAIのStableDiffusionなどがある。拡散モデルは、ARモデルのように数十億ものパラメータを必要とせずに自然画像の複雑な分布を生成でき、GANで示されるモード崩壊の問題に悩まされることはない。ただし、拡散モデルは、画像データ内の知覚できない詳細をモデル化するために過剰な処理を使用する傾向があるため、依然として計算量が多い。
【0005】
更に、拡散モデルは有望な高品質の画像合成を示しているが、本発明者は、モデルがテキスト入力を正しく解釈するのに苦労することが多いことを発見した。従来の方法は、複数のテキスト記述間の関係を考慮できず、ローカルな特徴(視覚属性)をレイアウトに合わせることができない可能性がある。例えば、従来の方法は、画像に関する複数の記述を要件として構成し、それらを使用して画像生成をガイドし、レイアウトロスを使用して画像内のオブジェクトの位置を所望の位置にガイドする。しかし、これらの方法を使用すると、同じオブジェクトの2つが入力として与えられた場合、拡散モデルは、各オブジェクトに正しい記述を割り当てるのに苦労することが多く、出力画像内のオブジェクトのうちの1つを完全に無視することさえある。更に、2つの異なるオブジェクトが入力として与えられた場合、拡散モデルは2つのオブジェクトを1つのハイブリッドオブジェクトに不適当に結合することが示されている。
【0006】
従って、入力から所望の画像を生成する際の拡散モデルなどのニューラルネットワークの精度を向上させることが望ましい。また、ニューラルネットワークの試行錯誤コストを削減することも望ましい。
【発明の概要】
【0007】
本発明は、独立請求項に定義されており、ここで参照すべきである。更なる特徴は、従属請求項に記載されている。
【0008】
本発明の態様によれば、画像を生成するコンピュータ実施方法が提供される。前記方法は、
入力テキスト及びレイアウト情報を受信するステップと、
前記入力テキストを1つ以上のグローバル特徴及び1つ以上のローカル特徴に分解するステップと、
前記1つ以上のグローバル特徴をグローバルベクトルに、前記1つ以上のローカル特徴を各々ローカルベクトルに符号化するステップと、
初期画像表現を初期化するステップと、
トレーニング済みニューラルネットワークを使用して、前記グローバルベクトル及び前記初期画像表現からグローバルノイズを予測するステップと、
トレーニング済みニューラルネットワークを使用して、前記1つ以上のローカル特徴の各々について、前記1つ以上のローカルベクトル及び前記初期画像表現から初期ローカルノイズを予測するステップと、
前記初期ローカルノイズ及び前記(予測された)グローバルノイズを使用して、前記1つ以上のローカル特徴の各々について最終ローカルノイズを決定するステップと、
前記レイアウト情報を使用して、前記予測されたグローバルノイズ及び前記最終ローカルノイズを合成ノイズに合成するステップと(場合によっては、前のステップで予測されたグローバルノイズから決定された最終グローバルノイズである、この合成のために前記予測されたグローバルノイズの精緻化ベクトルを使用する、例えば無条件ノイズを使用する)、
前記合成ノイズを使用して前記初期画像表現をノイズ除去し、前記画像を生成するための次の画像表現を提供するステップと、
を含む。
【図面の簡単な説明】
【0009】
例としてのみ、以下の添付の図面を参照する。
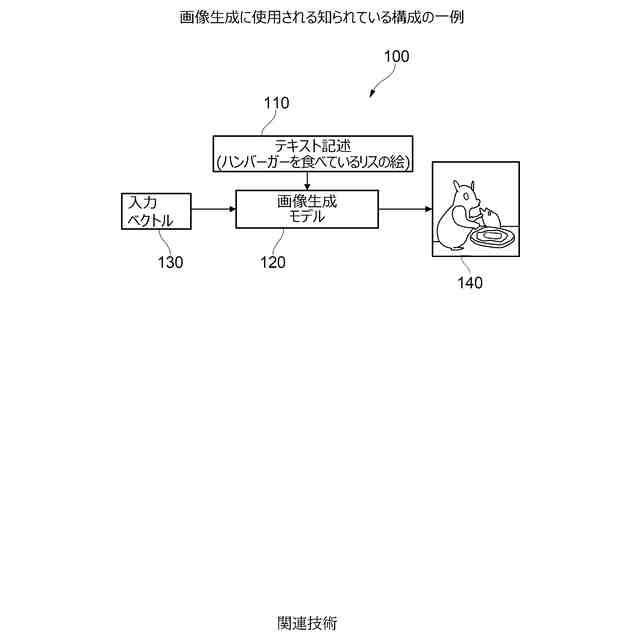
画像生成に使用される知られている構成の一例である。
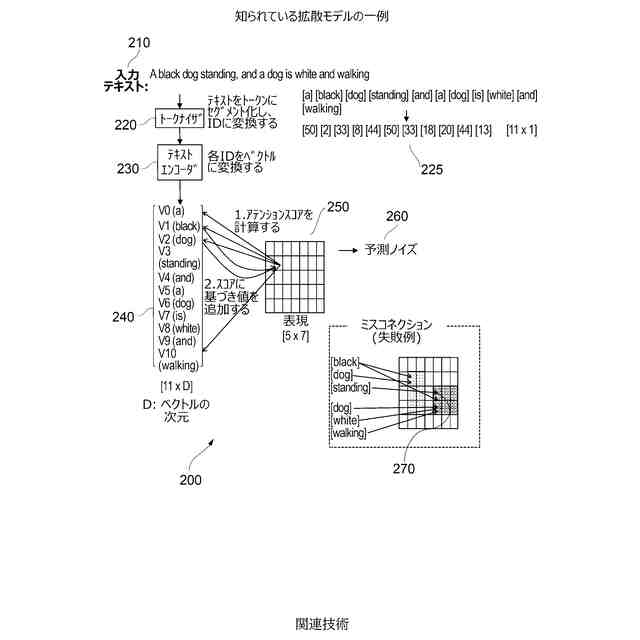
知られている拡散モデルの一例である。
拡散モデルを使用する知られている画像生成方法の一例である。
図3の画像生成方法の失敗例を示す。
図3の画像生成方法の失敗例を示す。
拡散モデルによって実行されるノイズ除去プロセスを示す。
拡散モデルを使用する知られている画像生成方法の第2例である。
図6の画像生成方法の失敗例を示す。
拡散モデルを使用する知られている画像生成方法の第3例である。
図8の画像生成方法の失敗例を示す。
拡散モデルを使用する知られている画像生成方法の第4例である。
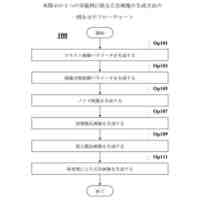
本明細書に開示される方法による、テキスト入力及びレイアウト情報から画像を生成する方法のステップを示す。
図10による方法を実行することができるユニットの機能ブロック図である。
本明細書に開示される方法による、入力シーングラフから画像を生成する別の例を示す。
シーングラフ分解方法の一例である。
入力シーングラフをシーングラフのグローバルグラフ及びローカルグラフを記述するテキスト出力に変換する例を示す。
グローバルテキスト入力及びローカルテキスト入力からノイズを予測するための機能図の例である。
グローバルグラフ入力及びローカルグラフ入力からノイズを予測するための機能図の例である。
予測されたグローバルノイズ及びローカルノイズを合成ノイズに合成する例である。
画像を生成するための図12による方法の実施例である。
本明細書に開示された方法を使用して生成された画像の例を示す。
入力テキスト、レイアウト情報、及びレイヤを使用する画像生成方法の更なる例である。
入力テキスト、レイアウト情報、及びレイヤの例を示す。
階層化された入力からノイズを決定する例を示す。
生成された画像に対するハイパーパラメータの変化の影響を示す。
情報処理機器又はコンピュータ装置のブロック図である。
テキスト及びレイアウト情報を入力するためのグラフィカルユーザインタフェースの例である。
【発明を実施するための形態】
【0010】
図1は、単純な画像生成方法100の知られている構成を示す。この方法は、画像生成の推論又は実装段階を示す。ユーザは、テキスト記述110を画像生成モデル120に入力する。例えば、ユーザは「ハンバーガーを食べているリスの絵」を望むかもしれない。画像生成モデル120は、例えば、拡散モデルのようなニューラルネットワークであってもよい。具体的には、拡散モデルは、潜在拡散モデルのような拡散確率モデルであってもよい。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
富士通株式会社
信号相関量の確定装置と方法
10日前
富士通株式会社
データセット特徴タイプ推論
10日前
富士通株式会社
光伝送装置および光伝送システム
11日前
富士通株式会社
双方向光リンクの異常モニタリング
13日前
富士通株式会社
バイアスのための生成人工知能の検査
3日前
富士通株式会社
情報処理プログラムおよび情報処理方法
10日前
富士通株式会社
大規模言語モデルを使用したデータ調整
10日前
富士通株式会社
制御プログラム、制御方法及び決済装置
6日前
富士通株式会社
選択プログラム、選択装置、及び選択方法
13日前
富士通株式会社
広告画像を生成する方法、装置及び記憶媒体
17日前
富士通株式会社
赤外線センサ、及び赤外線センサの製造方法
19日前
富士通株式会社
無線アクセスネットワークプロビジョニング
10日前
富士通株式会社
光送信機サブ信号光位相差の確定装置と方法
10日前
富士通株式会社
演算プログラム、演算方法、および情報処理装置
10日前
富士通株式会社
情報処理プログラム、情報処理方法、及び情報処理装置
11日前
富士通株式会社
量子ビットデバイス及び量子ビットデバイスの製造方法
17日前
富士通株式会社
情報処理プログラム、情報処理装置、および情報処理方法
6日前
富士通株式会社
光送信機のサブ信号の遅延差のリアルタイム監視装置及び方法
10日前
富士通株式会社
ブロックチェーンに基づくエスクローされたマーケットプレイス
10日前
富士通株式会社
共有メモリ制御プログラム、共有メモリ制御方法および情報処理装置
10日前
富士通株式会社
光伝送路特性推定装置、光伝送システム、及び光伝送路特性推定方法
11日前
富士通株式会社
スタート支援装置、スタート支援方法、およびスタート支援プログラム
11日前
富士通株式会社
棄却なしの並列試行マルコフ連鎖モンテカルロ法を用いた統計的サンプリング
3日前
富士通株式会社
依存情報を列に集約したマトリクススケジューラ及びマトリクススケジューリング方法
18日前
富士通株式会社
量子回路シミュレーションプログラム、量子回路シミュレーション方法および情報処理装置
19日前
富士通株式会社
機械学習プログラム、判定プログラム、機械学習方法、判定方法、機械学習装置、および判定装置
3日前
個人
対話装置
1か月前
個人
情報処理装置
1か月前
個人
政治のAI化
1か月前
個人
情報処理システム
3日前
個人
情報処理装置
27日前
個人
記入設定プラグイン
19日前
個人
検査システム
5日前
個人
プラグインホームページ
1か月前
株式会社サタケ
籾摺・調製設備
4日前
個人
不動産売買システム
11日前
続きを見る
他の特許を見る



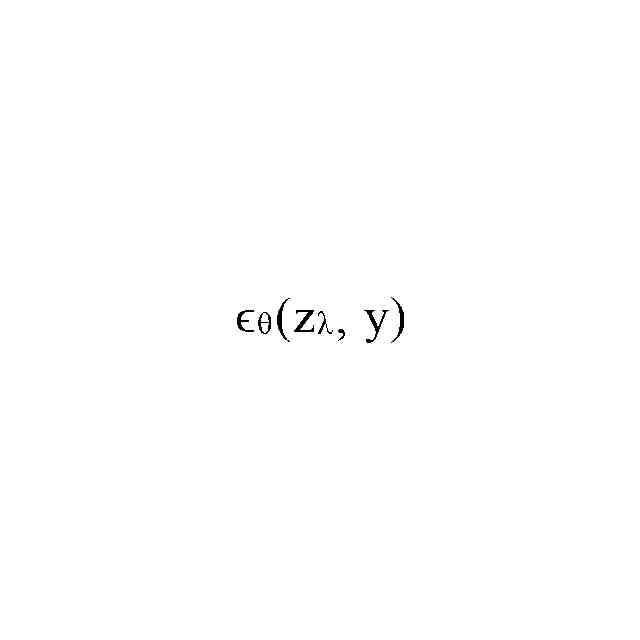

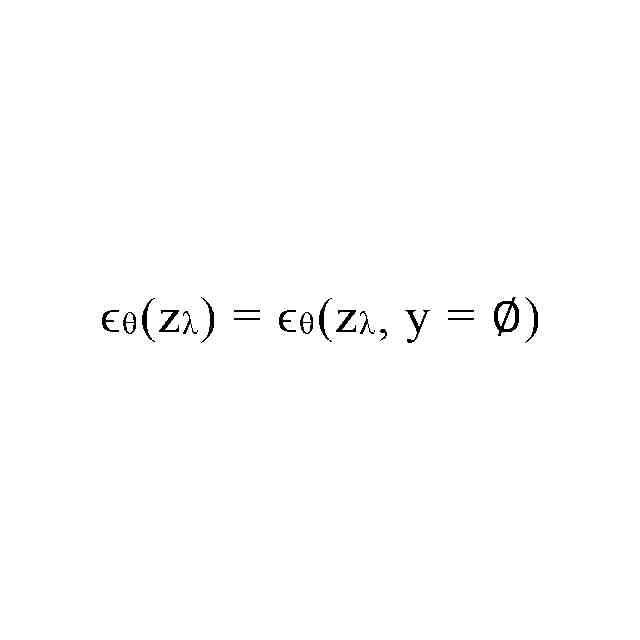

 特許ウォッチ
特許ウォッチ