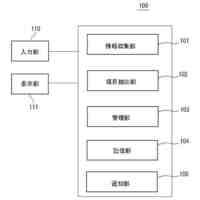
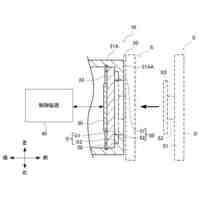
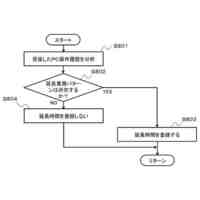
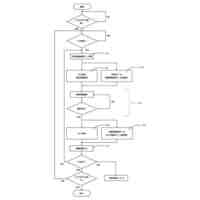
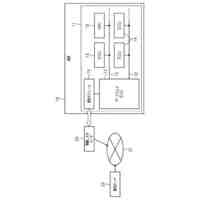
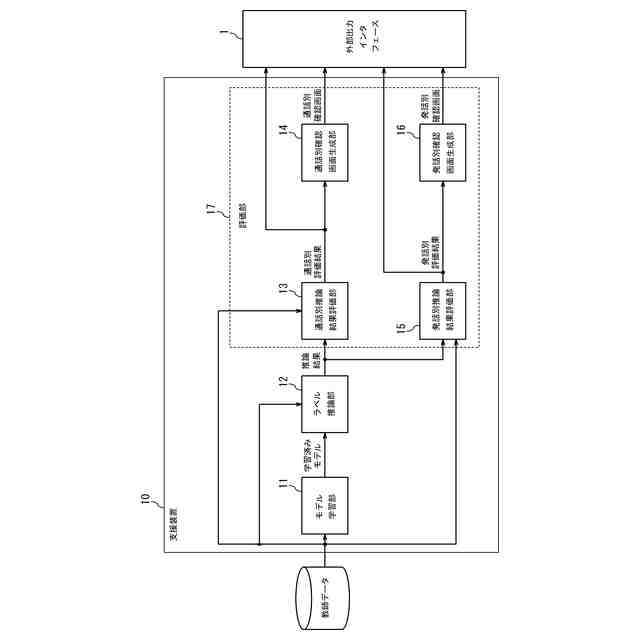
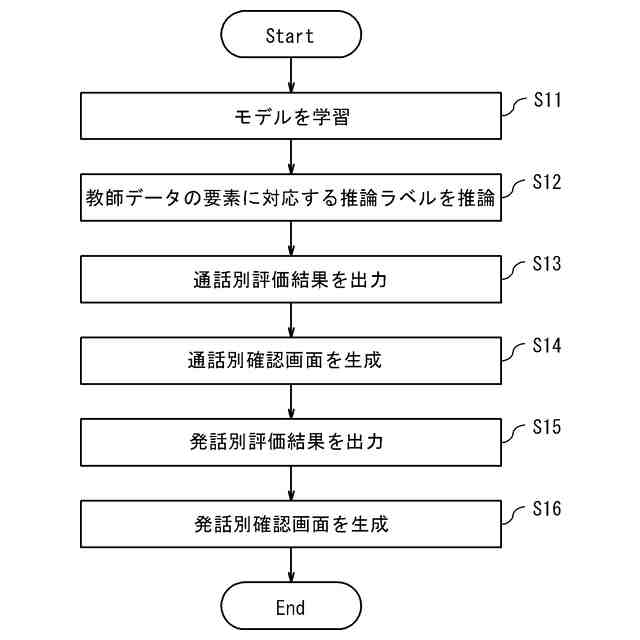
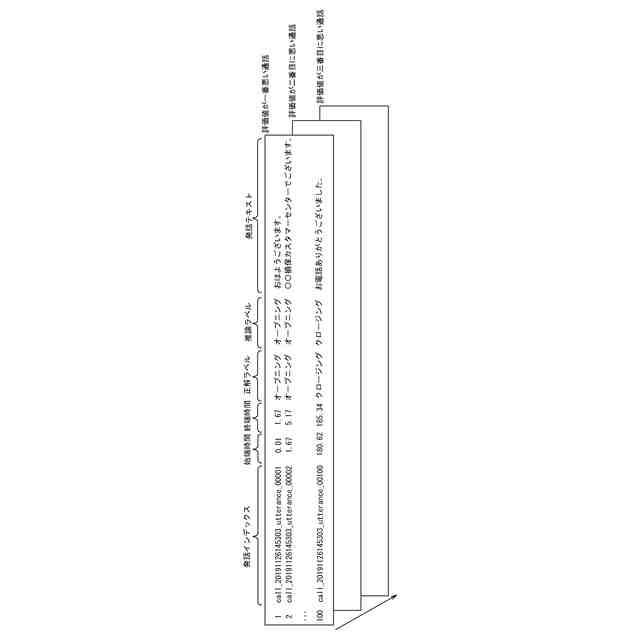
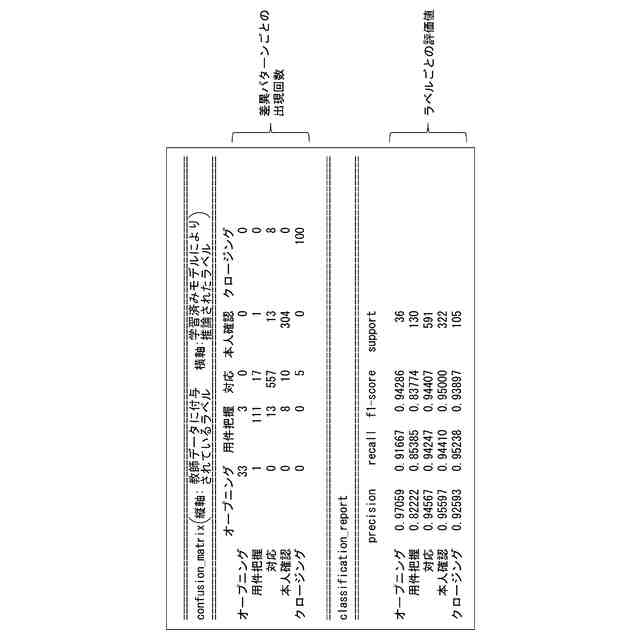
発明の詳細な説明【技術分野】 【0001】 本開示は、支援装置、支援方法およびプログラムに関する。 続きを表示(約 2,500 文字)【背景技術】 【0002】 近年、コンタクトセンタにおける応対品質の向上を目的として、通話内容をリアルタイムに音声認識し、自然言語処理技術を駆使して応対中のオペレータに適切な情報を自動的に提示するシステムが提案されている。 【0003】 例えば、非特許文献1には、オペレータとカスタマとの対話において、予め想定される質問事項とその質問事項に対する回答(FAQ)とをオペレータに提示する技術が開示されている。この技術では、オペレータとカスタマとの対話が音声認識され、話者が話し終わったかを判定する「話し終わり判定」により、意味的なまとまりのある発話テキストに変換される。次に、発話テキストに対応する発話が、オペレータによる挨拶、カスタマの用件の確認、用件への対応あるいは対話のクロージングといった、対話におけるどの応対シーンでの発話であるかを推定する「応対シーン推定」が行われる。「応対シーン推定」により対話の構造化が行われる。「応対シーン推定」の結果から、カスタマの用件を含む発話あるいはオペレータがカスタマの用件を確認する発話を抽出する「FAQ検索発話判定」が行われる。予め用意されたFAQのデータベースに対して、「FAQ検索発話判定」により抽出された発話に基づく検索クエリを用いた検索が行われ、検索結果がオペレータに提示される。 【0004】 上述した「話し終わり判定」、「応対シーン推定」および「FAQ検索発話判定」には、発話テキストに対して、発話を区分するラベルが付与された教師データを、深層ニューラルネットワークなどを用いて学習することで構築されたモデルが用いられる。したがって、「話し終わり判定」、「応対シーン推定」および「FAQ検索発話判定」は、系列的な要素(対話における発話)にラベル付けする系列ラベリング問題として捉えることができる。非特許文献2には、系列的な発話に、その発話が含まれる応対シーンに対応するラベルを付与した大量の教師データを、長短期記憶を含む深層ニューラルネットワークにより学習することで、応対シーンを推定する技術が記載されている。 【先行技術文献】 【非特許文献】 【0005】 長谷川隆明, 関口裕一郎, 山田節夫, 田本真詞, “オペレータの応対を支援する自動知識支援システム,” NTT技術ジャーナル, vol.31, no.7, pp.16-19, Jul. 2019. R. Masumura, S. Yamada, T. Tanaka, A. Ando, H. Kamiyama, and Y. Aono, “Online Call Scene Segmentation of Contact Center Dialogues based on Role Aware Hierarchical LSTM-RNNs,” Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Nov. 2018. 【発明の概要】 【発明が解決しようとする課題】 【0006】 上述した非特許文献1,2に記載の技術では、推定精度を実用に耐えうる水準にするためには、大量の教師データが必要となる。例えば、非特許文献1によれば、1000通話程度のコールセンタの対話ログから教師データを作成してモデルを学習することで、高い推定精度を得ることができる。教師データは、作業者(教師データ作成者)が、発話音声の音声認識により得られた発話テキストを参照しながら、各発話テキストにラベルを付与することで作成される。 【0007】 教師データは、その教師データを用いて学習されるモデルの適用先(例えば、コンタクトセンタの業界ごと)に合わせて作成する必要がある。上述したように、高い推定精度を得るためには、大量の教師データが必要となることから、ラベルを付与する教師データの作成作業は、複数の作業者により行われることが多い。ここで、作業者ごとに、経験あるいはラベル付与の細かなポリシーが異なることから、同じ内容の発話であっても、異なるラベルが付与されてしまうという、ラベル付与のブレが生じることがある。教師データにラベルのブレが生じると、その教師データを用いて学習したモデルの推定精度の低下を招いてしまうため、近い内容の発話に対しては同じラベルが一貫して付与されているかを確認する必要がある。しかしながら、効率的に教師データの確認が可能な技術は確立されておらず、有識者の暗黙知による分析あるいはトライアンドエラーの繰り返しが必要となってしまう。 【0008】 したがって、発話テキストなどの要素にラベルを付与する教師データの作成において、教師データの確認作業をより効率的に行うことができる技術が求められている。 【0009】 上記のような問題点に鑑みてなされた本開示の目的は、教師データの確認作業をより効率的に行うことができる支援装置、支援方法およびプログラムを提供することにある。 【課題を解決するための手段】 【0010】 上記課題を解決するため、本開示に係る支援装置は、要素と、前記要素に対応する正解ラベルとの組からなる教師データの確認を支援する支援装置であって、前記教師データを用いて学習された、前記要素に対応するラベルを推論するモデルを用いて、前記教師データを構成する要素に対応するラベルである推論ラベルを推論するラベル推論部と、前記教師データを構成する要素と、前記要素の正解ラベルと、前記要素の推論ラベルとを含む、教師データ確認画面を、前記教師データを作成した教師データ作成者ごとに生成する評価部と、を備える。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する


 特許ウォッチ
特許ウォッチ