TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024027087
公報種別
公開特許公報(A)
公開日
2024-02-29
出願番号
2023093632
出願日
2023-06-07
発明の名称
汎用モデルに基づく標準的な医学用語管理システム及び方法
出願人
個人
代理人
個人
主分類
G16H
70/00 20180101AFI20240221BHJP(特定の用途分野に特に適合した情報通信技術)
要約
【課題】異なる科学研究及び業務使用シーンを満たすことができ、異なるプラットフォーム及び権威機構の標準的な医学用語と互換的であるか又はそれに遡及することができ、設計された構造体が用語の各種類の組み合わせ拡張をサポートする汎用モデルに基づく標準的な医学用語管理システム及び方法を提供する。
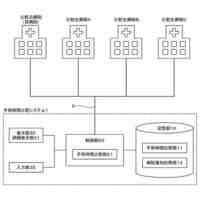
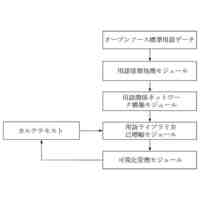
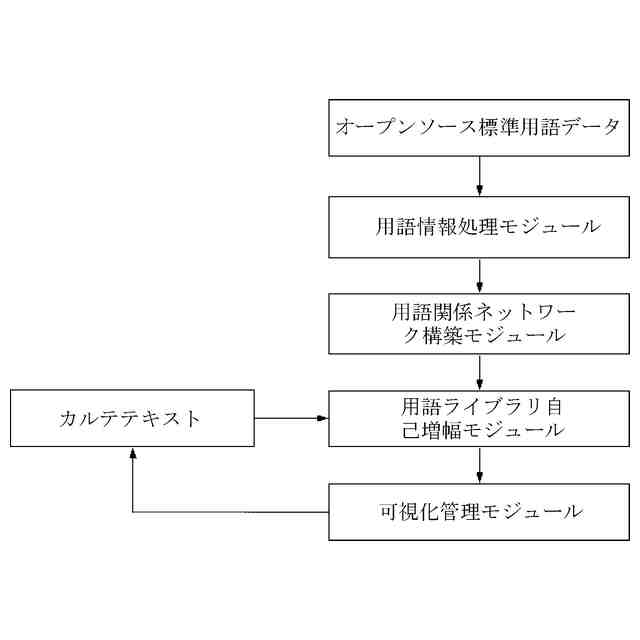
【解決手段】医学用語管理システムは、用語情報処理モジュール、用語関係ネットワーク構築モジュール、用語ライブラリ自己増幅モジュール及び可視化管理モジュールを備え、用語情報処理モジュールによってオープンソース標準用語データを整理統合し、用語カテゴリ及び用語カテゴリに対応する細分の属性名称を取得し、標準化マッピング関係を確立し、用語関係ネットワークの設立を完了し、用語関係ネットワークの拡張を完了し、完全な用語ライブラリを取得し、可視化管理モジュールによって用語ライブラリに対して可視化管理を行う。
【選択図】図1
特許請求の範囲
【請求項1】
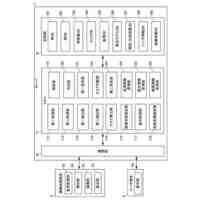
汎用モデルに基づく標準的な医学用語管理システムであって、用語情報処理モジュール、用語関係ネットワーク構築モジュール、用語ライブラリ自己増幅モジュール及び可視化管理モジュールを含み、
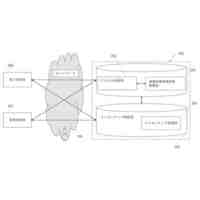
前記用語情報処理モジュールは、オープンソース標準用語データを整理統合し、前記オープンソース標準用語データの定義及び用語の意味に対して用語の分類を行って、用語カテゴリ及び用語カテゴリに対応する細分の属性名称を取得し、且つ構築されたシーケンスラベリングモデルによってカルテテキストを分割してカルテテキストの細分の属性名称に対応する細分の属性内容を取得することに用いられ、各種類の前記用語カテゴリがいずれも1種類の主要な細分の属性名称及び複数種類の副次的な細分の属性名称を含み、
前記用語関係ネットワーク構築モジュールは、前記細分の属性内容から語義類似度が最も高い標準的な語義単語を検索して標準化マッピング関係を確立して、前記標準化マッピング関係を補正及び追加し、用語関係ネットワークの設立を完了することに用いられ、
前記用語関係ネットワーク構築モジュールによる具体的な過程は、
前記シーケンスラベリングモデルによってカルテテキストを分割してカルテテキストの細分の属性を取得し、用語関係ネットワーク構築モジュールによって前記標準的な単語から任意の標準的な語義単語を検索し、アルゴリズムによってカルテテキストの細分の属性と前記任意の標準的な語義単語との語義類似度を取得し、語義類似度が最も高い標準的な単語を選択して標準化マッピング関係を確立するステップと、
アルゴリズムによって分割して副次的な細分の属性を取得し、現在のカルテテキストには説明タイプを定義できる親ノードが存在し、且つ分割して取得された主要な細分の属性にはタイプ情報が含まれない場合、主要な細分の属性を情報追加して情報に対応する細粒度サブノードに補正し、標準化マッピング関係の補正を完了するステップと、
単一の用語カテゴリが複数のタイプの副次的な細分の属性を含むことに起因して補正後の主要な細分の属性が複数ある場合、最も多く存在する主要な細分の属性のカルテテキストにおける親ノードを最後の主要な細分の属性として選択するステップと、
アルゴリズムによって分割して取得された結果は各次元の情報に欠損があって、データソース自身に階層構造が存在することである場合、前記用語カテゴリの親ノード分割結果によって情報補完を行い、用語関係ネットワークの設立を完了するステップと、を含み、
前記用語ライブラリ自己増幅モジュールは、異なる前記用語カテゴリに対してインクリメント推奨を行い、用語関係ネットワークの拡張を完了し、完全な用語ライブラリを取得することに用いられ、
前記用語ライブラリ自己増幅モジュールは具体的に、語義類似度によって標準化マッピングの有効性を判断し、標準化マッピングが有効である場合、直接にマッピング結果とし、標準化マッピングが無効である場合、前記カルテテキストの細分の属性から前記標準的な単語における他の可能な細分の属性カテゴリ及び標準的な語義単語への標準化マッピングを、アルゴリズムが推奨する、手動で監査する必要があるマッピング結果として改めて計算し、異なる用語カテゴリに対してインクリメント推奨を行い、用語関係ネットワークの拡張を完了し、完全な用語ライブラリを取得し、
前記可視化管理モジュールは、前記用語ライブラリに対して可視化管理を行うことに用いられる
ことを特徴とする汎用モデルに基づく標準的な医学用語管理システム。
続きを表示(約 4,400 文字)
【請求項2】
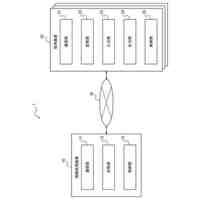
前記可視化管理モジュールは、標準的な医学用語クエリユニット、用語編集ユニット、用語監査ユニット及び用語マッピングユニットを含み、
前記標準的な医学用語クエリユニットは、ユーザーのプレビューデータを提供し、標準的な用語の可視化クエリを行い、異なる次元の選別条件に応じて対応する用語を選別するとともに、ユーザーログインインターフェース入口及び用語管理インターフェース入口を提供し、標準的な用語のトップレベルカテゴリ、同義語、親ノード用語、サブノード用語及び/又は属性情報を含む次元の標準的な用語情報を表示し、それと同時に関連用語詳細インターフェースに入る入口を提供することに用いられ、
前記用語編集ユニットは、ユーザーが可視化インターフェースを介して標準的な用語の追加、削除及び/又は補正、標準的な用語の同義語の追加及び/又は削除、標準的な用語の属性情報の補正を含む用語エンティティの編集を行うことに用いられ、
前記用語監査ユニットは、用語監査者が第二者監査を行い、監査者が用語監査結果の判定を行うことに用いられ、
前記用語マッピングユニットは、ユーザーが異なるソースの医学データに対して標準化マッピングを行い、マッピング不可能なデータに対して推奨キューを構築し、用語管理者による用語のワンクリックマッピング及び推奨キューの形成を確保することに用いられる
ことを特徴とする請求項1に記載の汎用モデルに基づく標準的な医学用語管理システム。
【請求項3】
汎用モデルに基づく標準的な医学用語管理方法であって、ステップS1~ステップS4を含み、
前記ステップS1では、用語情報処理モジュールによってオープンソース標準用語データを整理統合し、前記オープンソース標準用語データの定義及び用語の意味に対して用語の分類を行って、用語カテゴリ及び用語カテゴリに対応する細分の属性名称を取得し、且つ構築されたシーケンスラベリングモデルによって分割して前記細分の属性名称に対応する細分の属性内容を取得し、前記細分の属性内容が標準的な単語であり、各種類の前記用語カテゴリがいずれも1種類の主要な細分の属性名称及び複数種類の副次的な細分の属性名称を含み、
前記ステップS2では、前記シーケンスラベリングモデルによってカルテテキストを分割してカルテテキストの細分の属性を取得し、用語関係ネットワーク構築モジュールによって前記標準的な単語から語義類似度が最も高い標準的な語義単語を検索して標準化マッピング関係を確立して、前記標準化マッピング関係を補正及び追加し、用語関係ネットワークの設立を完了し、
前記ステップS2はサブステップS21~サブステップS24を含み、
前記サブステップS21では、前記シーケンスラベリングモデルによってカルテテキストを分割してカルテテキストの細分の属性を取得し、用語関係ネットワーク構築モジュールによって前記標準的な単語から任意の標準的な語義単語を検索し、アルゴリズムによってカルテテキストの細分の属性と前記任意の標準的な語義単語との語義類似度を取得し、語義類似度が最も高い標準的な単語を選択して標準化マッピング関係を確立し、
前記サブステップS22では、アルゴリズムによって分割して副次的な細分の属性を取得し、現在のカルテテキストには説明タイプを定義できる親ノードが存在し、且つ分割して取得された主要な細分の属性にはタイプ情報が含まれない場合、主要な細分の属性を情報追加して情報に対応する細粒度サブノードに補正し、標準化マッピング関係の補正を完了し、
前記サブステップS23では、単一の用語カテゴリが複数のタイプの副次的な細分の属性を含むことに起因して補正後の主要な細分の属性が複数ある場合、最も多く存在する主要な細分の属性のカルテテキストにおける親ノードを最後の主要な細分の属性として選択し、
前記サブステップS24では、アルゴリズムによって分割して取得された結果は各次元の情報に欠損があって、データソース自身に階層構造が存在することである場合、前記用語カテゴリの親ノード分割結果によって情報補完を行い、用語関係ネットワークの設立を完了し、
前記ステップS3では、用語ライブラリ自己増幅モジュールによって異なる用語カテゴリに対してインクリメント推奨を行い、用語関係ネットワークの拡張を完了し、完全な用語ライブラリを取得し、
前記ステップS3は具体的に、語義類似度によって標準化マッピングの有効性を判断し、標準化マッピングが有効である場合、直接にマッピング結果とし、標準化マッピングが無効である場合、前記カルテテキストの細分の属性から前記標準的な単語における他の可能な細分の属性カテゴリ及び標準的な語義単語への標準化マッピングを、アルゴリズムが推奨する、手動で監査する必要があるマッピング結果として改めて計算し、異なる用語カテゴリに対してインクリメント推奨を行い、用語関係ネットワークの拡張を完了し、完全な用語ライブラリを取得し、
前記ステップS4では、可視化管理モジュールによって前記用語ライブラリに対して可視化管理を行い、前記可視化管理が標準的な医学用語クエリユニット、用語編集ユニット、用語監査ユニット及び用語マッピングユニットを備える
ことを特徴とする汎用モデルに基づく標準的な医学用語管理方法。
【請求項4】
前記ステップS1は具体的に、サブステップS11~サブステップS12を含み、
前記サブステップS11では、用語情報処理モジュールによってオープンソース標準用語データを整理統合し、前記オープンソース標準用語データの定義及び用語の意味に対して用語の分類を行って、元の用語の階層関係、関連関係及び/又は符号化情報を保持してソースタグを付けて、用語カテゴリ及び用語カテゴリに対応する細分の属性名称を取得し、
前記サブステップS12では、事前訓練言語モデルによってシーケンスラベリングモデルを構築して、前記シーケンスラベリングモデルによってオープンソース標準用語データを分割して細分の属性内容を取得する
ことを特徴とする請求項3に記載の汎用モデルに基づく標準的な医学用語管理方法。
【請求項5】
前記サブステップS12は具体的に、サブステップS121~サブステップS124を含み、
前記サブステップS121では、事前訓練言語モデルによってオープンソース標準用語データにおける各文字/単語のベクトル表現を計算し、
前記サブステップS122では、前記ベクトル表現に対して自己注意メカニズムによって各文字/単語の出力状態を計算し、
前記サブステップS123では、前記出力状態に対して完全接続ニューラルネットワークにより計算を行って各文字/単語が各種類の細分の属性カテゴリに属する確率を取得し、シーケンスラベリングモデルの構築を完了し、
前記サブステップS124では、前記オープンソース標準用語データを前記シーケンスラベリングモデルによって分割して細分の属性内容を取得し、前記細分の属性内容が標準的な単語であり、前記細分の属性内容が主要な細分の属性内容及び副次的な細分の属性内容を含む
ことを特徴とする請求項4に記載の汎用モデルに基づく標準的な医学用語管理方法。
【請求項6】
前記サブステップS21は具体的に、サブステップS211~サブステップS212を含み、
前記サブステップS211では、前記カルテテキストの細分の属性及び前記標準的な単語から前記カルテテキストの細分の属性と前記標準的な単語を含む文セット、前記カルテテキストの細分の属性及び前記標準的な単語の左側に位置する文セット、並びに前記カルテテキストの細分の属性及び前記標準的な単語の右側に位置する文セットを取得し、
前記サブステップS212では、いずれか1対の文セットの平均値を計算して、最終的な平均値の組み合わせによって語義類似度を取得し、語義類似度が最も高い標準的な単語を選択して標準化マッピング関係を確立する
ことを特徴とする請求項3に記載の汎用モデルに基づく標準的な医学用語管理方法。
【請求項7】
前記ステップS3は具体的に、サブステップS31~サブステップS35を含み、
前記サブステップS31では、語義類似度によって標準化マッピングの有効性を判断し、標準化マッピングが無効である場合、カルテテキストを分割して取得したカルテテキストの細分の属性と標準的な語義単語との距離を計算し、
前記サブステップS32では、標準的な語義単語を距離に応じて降順で配列し、上位K個の標準的な単語を取って細分の属性との距離が最も近い標準的な単語セットを構成し、
前記サブステップS33では、細分の属性カテゴリにおける標準的な語義単語の推奨スコアを計算し、すべての細分の属性カテゴリを推奨スコアに応じて降順で配列し、上位k1個の細分の属性カテゴリを取ってアルゴリズムが推奨する細分の属性から標準的な用語システムにおける細分の属性カテゴリへマッピングするアルゴリズム推奨キューを構成し、
前記サブステップS34では、すべての標準的な単語を語義類似度に応じて降順で配列し、上位k2個の標準的な単語を取って細分の属性から細分の属性カテゴリにおける標準的な単語へマッピングするアルゴリズム推奨キューを構成し、
前記サブステップS35では、すべてのアルゴリズム推奨キューを組み合わせて、用語関係ネットワークの拡張を完了し、完全な用語ライブラリを取得する
ことを特徴とする請求項3に記載の汎用モデルに基づく標準的な医学用語管理方法。
【請求項8】
前記ステップS4は具体的に、ユーザーが異なる選別条件に応じて、標準的な医学用語クエリユニットによって対応する用語を選別することと、ユーザーが用語編集ユニットによって標準的な用語の追加、削除及び/又は補正、標準的な用語の同義語の追加及び/又は削除、標準的な用語の属性情報の補正を含む用語エンティティの編集を行うことと、用語監査者が用語監査ユニットによって用語監査結果の判定を行うことと、ユーザーが用語マッピングユニットによって異なるソースの医学データに対して標準化マッピングを行い、マッピング不可能なデータに対して推奨キューを構築し、用語管理者による用語のワンクリックマッピング及び推奨キューの形成を確保することと、を含む
ことを特徴とする請求項3に記載の汎用モデルに基づく標準的な医学用語管理方法。
発明の詳細な説明
【技術分野】
【0001】
本発明は医学分野の技術分野に関し、特に汎用モデルに基づく標準的な医学用語管理システム及び方法に関する。
続きを表示(約 2,500 文字)
【背景技術】
【0002】
ビッグデータ時代の到来に伴い、医療ビッグデータの医学分野での応用価値も徐々に掘り起こして利用されるようになる。ところが、この過程において、マルチソースの医学データは統一された標準を有せず、過去に規範的な制約がないため、各業界において既存の医療データを最大限に合理的に利用できず、これも医学情報化構築及び医学研究発展の妨害要素となる。
【0003】
現在、各大国内外の権威機構が発表した標準的な医学用語集は既に異なる分野に広く応用及び認可されているが、複数のニーズシーンに対応できて異なるサービスプラットフォーム間の壁を突破できる中国語の標準的な医学用語システムがまだない。このため、今の段階において、中国語の標準的な用語の現実の世界におけるカバー率が40%よりも低いだけであり、医療人工知能の応用ニーズを満たすことができない。
【0004】
既存の中国語医学用語管理方法において、第1としては、snowflakeアルゴリズムによって同義の医学用語をマーキングし、概念を中心として統合した後、単一分類におけるツリーデータ構造医学辞書を構築し、第2としては、英語の医学用語リソース例えばSNOMED CTに対して機械翻訳及び大量の手動補正を行う。
【0005】
第1形態においては、異なるソースから取得された医学用語を分類して、異なる意味の医学用語を取得し、概念を中心として同義の集まり及び語義の分類を実現し、更に異なる意味の医学概念をsnowflakeアルゴリズムによってマーキングし、異なる概念識別子に基づいて統合して医学概念リストを取得するとともに、正確な分類を満たすようにJaccard類似度アルゴリズムによって同じソースの医学用語に対して類似度の計算を行う。このような方法によってインクリメントIDを実現し、IDの一意性及びインデックス性能を確保する。その構築された用語システムは構造が単一で、拡張性が低く、多様なデータソース及び絶えず更新している応用シーンニーズを満たすための汎化能力及び柔軟性がない。用語内部及び用語間の関連情報を効果的に利用しないため、用語集の後続のメンテナンス及び拡張のために依然として多くの人件費を要する必要がある。1つの標準的な用語概念を追加する場合を例とし、従来の技術案は元の用語リストに同義の概念が存在するかどうかを判断することにより概念の分類又は追加を行うことができるだけである。追加した概念と元の用語リストにおける用語との間に階層関係がある場合、新たな概念を有効なノードの位置に自動的に追加できず、追加概念と既存概念との間に情報の関連がある場合、それも識別できず、従って関連情報を記憶するのであり、従来技術は用語自身の既存情報を効果的に利用して同類用語の集まりを行うことができず、手動で管理及びメンテナンスする必要があり、標準化された用語管理システム及び反復閉ループを効果的に形成することができない。
【0006】
第2形態においては、大量の手動補正を行わずに機械翻訳のみを行う条件において、翻訳結果が専門概念から大きく外れることを回避できず、中国国内外言語の使用習慣の相違も無視しやすく、用語をマッピングする際に取得したリコール率が極めて低いことが多い。リコール率を向上させる必要がある場合、管理及びメンテナンスのために倍になる人件費及び資金コスト、並びに長い時間サイクルを要する。
【0007】
現在、構築された用語システムは構造が単一で、拡張性が低く、多様なデータソース及び業務ニーズを満たすための汎化能力がなく、用語ライブラリを持続的且つ効率的に管理及び最適化するための柔軟性がない。主な表現は以下のとおりである。第(1)として、ソース情報を保留せず、標準的な用語と非標準的な用語とのマッピング関係を確立・記憶しない。第(2)として、用語内部及び用語間の関連関係を合理的に利用せず、標準的な用語概念の追加の場合には、元の用語リストに同義の概念が存在するかどうかを判断することにより概念の分類又は追加を行うことができるだけであり、追加する必要がある概念と元の用語リストにおける用語との間に階層関係がある場合、新たな概念を有効なノードの位置に自動的に追加できず、追加する必要がある概念は特定の応用ニーズを満たす必要があって、より高い階層に位置する場合、その中の関連情報を効果的に利用してそのサブクラスの同類用語の集まりを行い、第(3)として、用語ライブラリの後続の反復は多くの人件費を要し、効率的で標準化された用語管理システム及び反復閉ループを形成できない。
【0008】
実際のニーズシーンを例とし、用語ライブラリがDRG又はDIPシステムの業務ニーズを満たす必要がある場合、用語を関連する標準データベース例えばICD-10医療保険バージョン、ICD-9-CM-3医療保険バージョンにマッピング又は遡及できるように確保する必要があり、1つの標準概念を例とし、臨床所見概念「下肢痛」は現在確立された標準的な用語ライブラリに存在せず且つ追加される必要がある場合、それを「四肢痛」及び「下肢臨床所見」のノードに自動的に追加して上記2つの用語概念のサブノードとする必要があるとともに、元に「四肢痛」ノードにある「下腿痛」、「足部痛」、「左下肢痛」を「下肢痛」のサブノードに一括で補正する必要があり、そして、身体部位情報「下肢」を発病部位に自動的に関連付けする必要がある。明らかに、従来技術はまだ上記用語の自動化管理プロセスを完了できない。
【0009】
このために、上記技術的問題を解決するように汎用モデルに基づく標準的な医学用語管理システム及び方法を提供する。
【発明の概要】
【発明が解決しようとする課題】
【0010】
上記技術的問題を解決するために、本発明は汎用モデルに基づく標準的な医学用語管理システム及び方法を提供する。
【課題を解決するための手段】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
医療情報システム
3か月前
TOTO株式会社
排泄情報管理システム
1か月前
TOTO株式会社
生体情報管理システム
1か月前
小林クリエイト株式会社
被搬送物識別システム
2か月前
個人
看取り医師マッチングシステム
1か月前
学校法人近畿大学
腫瘍の分類推定システム
23日前
国立研究開発法人物質・材料研究機構
閾値算出方法
1か月前
TRIBAWL株式会社
情報処理装置
3か月前
小林製薬株式会社
漢方生薬製剤の決定支援装置
3か月前
株式会社Xenlon
紹介支援システム
3か月前
トヨタ自動車株式会社
方法
3日前
株式会社ラフール
情報処理システム
3か月前
株式会社日立製作所
情報処理装置
2か月前
株式会社レイヤード
情報処理システム
26日前
個人
情報処理装置、情報処理方法およびプログラム
1か月前
株式会社医用工学研究所
手術時間比較システム
16日前
株式会社サンクスネット
健康医療情報一元管理システム
3か月前
タカラベルモント株式会社
リハビリ支援装置
16日前
株式会社ヴェルト
ヘルスケア用データ解析システム
2か月前
ライオン株式会社
提案システム及び提案方法
2か月前
富士フイルム株式会社
プログラム
26日前
富士フイルム株式会社
プログラム
1か月前
株式会社トマーレ
医療情報共有システム
2か月前
TOTO株式会社
排泄情報処理装置、プログラム及びシステム
23日前
株式会社医療情報技術研究所
モジュール型電子カルテシステム
2か月前
TOTO株式会社
排泄情報処理装置、プログラム及びシステム
23日前
大日本印刷株式会社
情報処理装置及びプログラム
17日前
エニシア株式会社
情報処理装置、投与履歴提示方法およびプログラム
1か月前
株式会社メドレー
プログラム、システム及び方法
1か月前
株式会社竹中工務店
運営施策計画方法
1か月前
個人
汎用モデルに基づく標準的な医学用語管理システム及び方法
2か月前
個人
フレイル推定装置、フレイル推定方法及びプログラム
3か月前
株式会社医療情報技術研究所
電子カルテ記録集約/参照システム
1か月前
ニプロ株式会社
医療システムおよび医療装置
1か月前
日本電気株式会社
体液量推定装置、体液量推定方法及びプログラム
3か月前
花王株式会社
免疫機能活性の予測方法
3か月前
続きを見る
他の特許を見る







 特許ウォッチ
特許ウォッチ