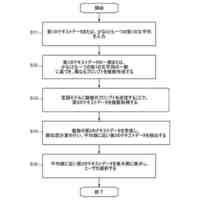
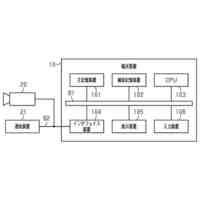
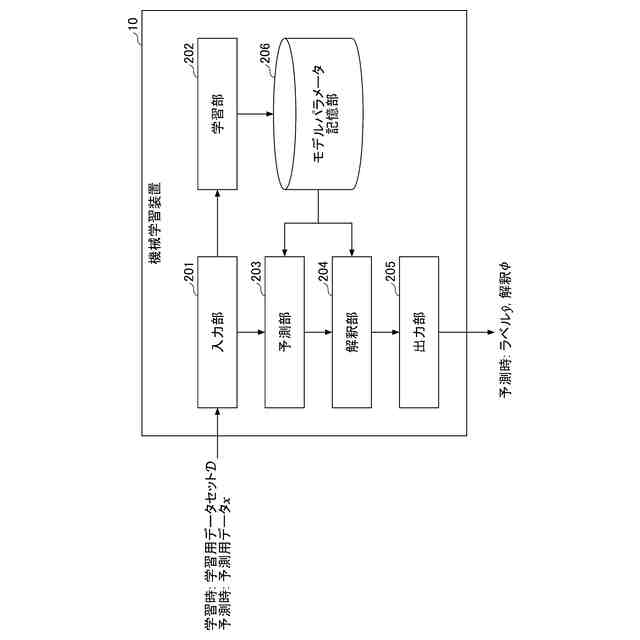
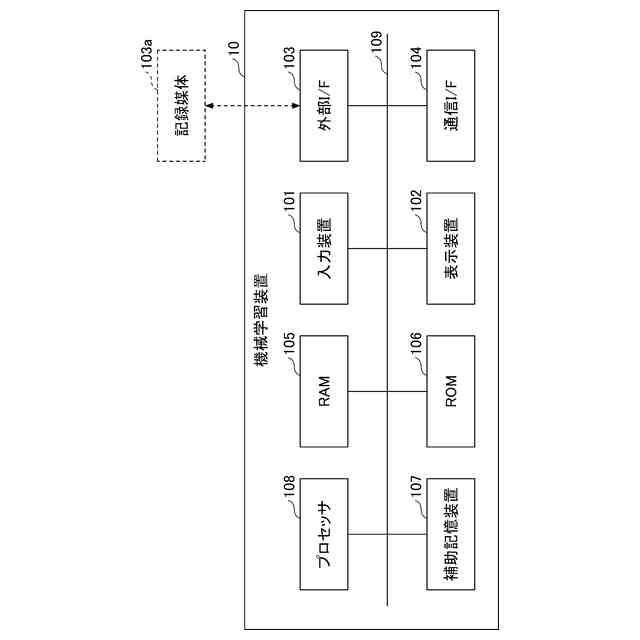
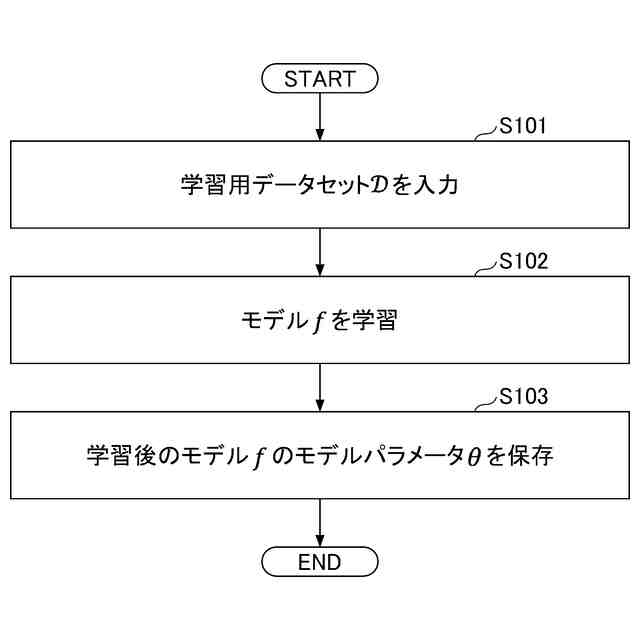
発明の詳細な説明【技術分野】 【0001】 本開示は、機械学習装置、機械学習方法、及びプログラムに関する。 続きを表示(約 1,300 文字)【背景技術】 【0002】 深層学習モデルをはじめとする機械学習モデルは高い性能を達成することができる一方で、その予測結果の解釈性が低いという問題がある。機械学習モデルによる予測結果の解釈性を高めることにより、その機械学習モデルを利用するシステムの信頼性を高めることが可能となる。 【0003】 上記の問題に対して、機械学習モデルの予測結果を解釈するための説明手法が提案されている(例えば、非特許文献1等)。 【先行技術文献】 【非特許文献】 【0004】 Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. "Why Should I Trust You?": Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD '16). 【発明の概要】 【発明が解決しようとする課題】 【0005】 しかしながら、従来、機械学習モデルは予測性能を高めるように学習されており、必ずしも解釈しやすいように学習されていないという問題がある。 【0006】 本開示は、上記の点に鑑みてなされたもので、予測性能と解釈性の高い機械学習モデルを学習できる技術を提供する。 【課題を解決するための手段】 【0007】 本開示の一態様による機械学習装置は、機械学習モデルを学習するための学習用データを入力する入力部と、前記学習用データを用いて、前記機械学習モデルの予測性能と、前記機械学習モデルの予測結果を所定の説明手法により解釈したときの解釈性とが高くなるように、前記機械学習モデルを学習する学習部と、を有する。 【発明の効果】 【0008】 予測性能と解釈性の高い機械学習モデルを学習できる技術が提供される。 【図面の簡単な説明】 【0009】 本実施形態に係る機械学習装置のハードウェア構成の一例を示す図である。 本実施形態に係る機械学習装置の機能構成の一例を示す図である。 本実施形態に係る学習処理の一例を示すフローチャートである。 本実施形態に係る予測処理の一例を示すフローチャートである。 挿入尺度による解釈性と正答率とを用いた評価結果の一例を示す図である。 削除尺度による解釈性と正答率とを用いた評価結果の一例を示す図である。 【発明を実施するための形態】 【0010】 以下、本発明の一実施形態について説明する。以下の実施形態では、予測性能と解釈性の高い機械学習モデルを学習できる機械学習装置10について説明する。また、学習済みの機械学習モデルによる予測とその予測結果の解釈とを機械学習装置10が計算及び出力する場合についても説明する。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する
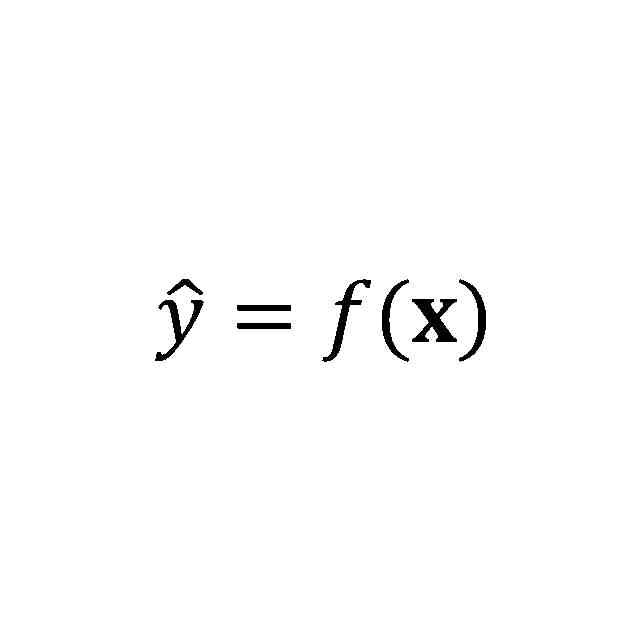
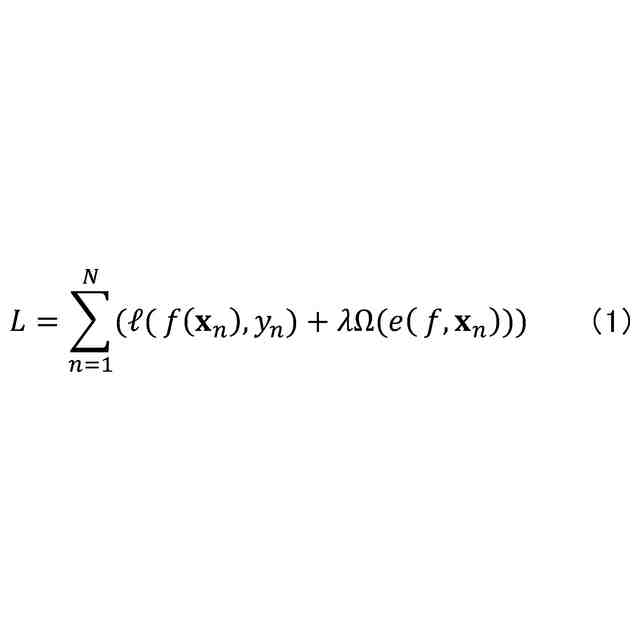
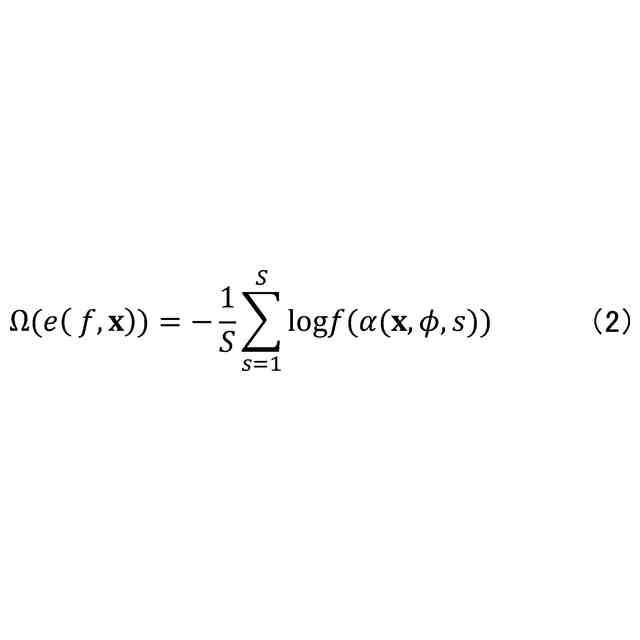
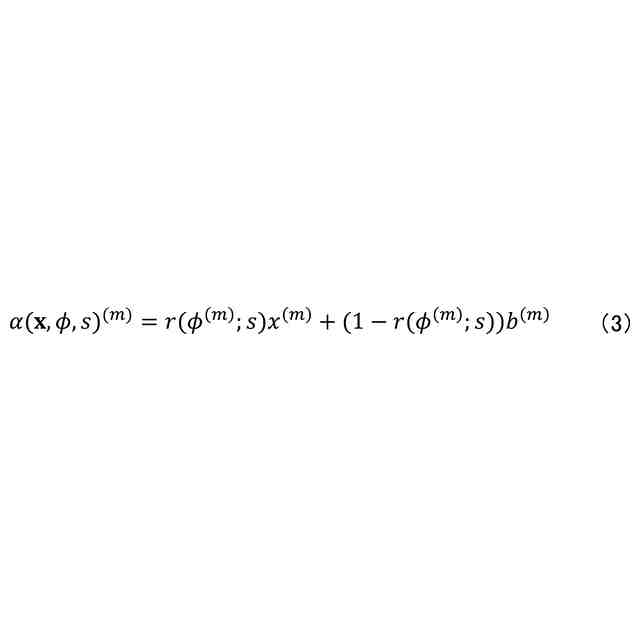
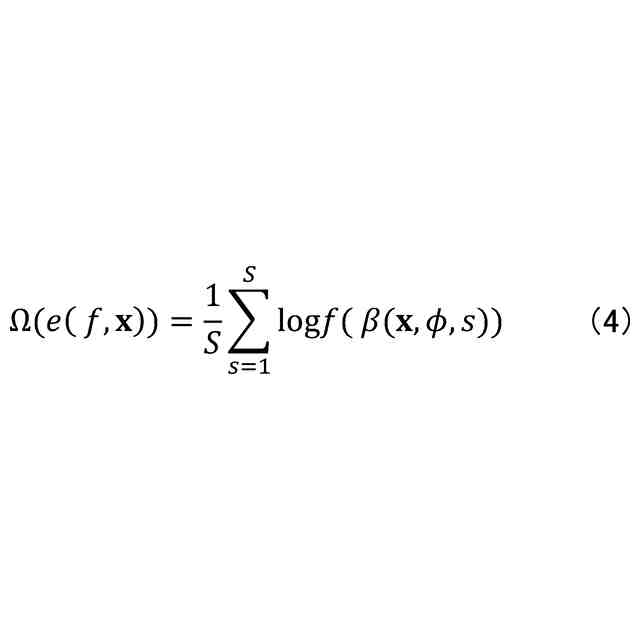
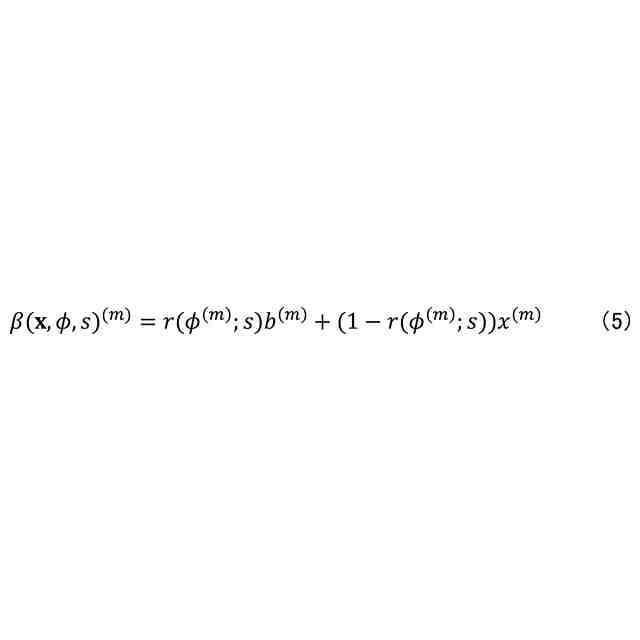

 特許ウォッチ
特許ウォッチ