TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025157347
公報種別
公開特許公報(A)
公開日
2025-10-15
出願番号
2025116671,2024520749
出願日
2025-07-10,2022-10-05
発明の名称
ベクトル量子化した画像モデリング
出願人
グーグル エルエルシー
,
Google LLC
代理人
個人
,
個人
,
個人
主分類
G06T
5/60 20240101AFI20251007BHJP(計算;計数)
要約
【課題】ビジョントランスフォーマおよび改善したコードブック取扱いを使用するベクトル量子化した画像モデリング方法を提供する。
【解決手段】ビジョントランスフォーマ及び改善したコードブック取扱いを使用するベクトル量子化した画像モデリングのためのベクトル量子化画像モデリング(VIM)方法であって、ラスタライズした画像トークンを自己回帰的に予測するため、機械学習モデル(トランスフォーマモデル)を事前訓練するステップを含む。個別の画像トークンは、学習したビジョントランスフォーマベースVQGANから符号化する。アーキテクチャからコードブック学習まで、バニラVQGANにわたる複数の改善を提案する。改善された実装形態であるViT-VQGANは、無条件画像生成、条件付き画像生成(クラス条件付き画像生成)および教師なし表現学習を含むベクトル量子化画像モデリングタスクをさらに改善する。
【選択図】図5
特許請求の範囲
【請求項1】
画像のベクトル量子化を実施するコンピュータ実装される方法であって、
1つまたは複数のコンピューティングデバイスを備えるコンピューティングシステムによって、画像の複数の入力画像パッチを得るステップと、
前記コンピューティングシステムによって、前記複数の入力画像パッチを機械学習した画像エンコーダで処理し、複数の画像トークンを潜在空間中に生成するステップであって、前記複数の画像トークンが前記複数の入力画像パッチに対応し、前記機械学習した画像エンコーダが、1つまたは複数の自己アテンション動作を実施して前記複数の入力画像パッチを処理し、前記複数の画像トークンを前記潜在空間中に生成する、ステップと、
前記コンピューティングシステムによって、複数の候補コードを含む量子化コードブックに含まれる複数の量子化コードに、前記複数の画像トークンをマッピングするステップと、
前記コンピューティングシステムによって、前記画像の符号化バージョンとして前記複数の量子化コードを提供するステップと
を含む、コンピュータ実装される方法。
続きを表示(約 1,700 文字)
【請求項2】
前記機械学習した画像エンコーダがビジョントランスフォーマモデルを備える、請求項1に記載のコンピュータ実装される方法。
【請求項3】
前記機械学習した画像エンコーダが前記複数の入力画像パッチに前記1つまたは複数の自己アテンション動作のうちの1つを実施する、請求項1または2に記載のコンピュータ実装される方法。
【請求項4】
前記コンピューティングシステムによって、前記複数の量子化コードを機械学習した画像デコーダで処理して、合成画像を形成する複数の合成画像パッチを生成するステップと、
前記コンピューティングシステムによって、少なくとも部分的に前記合成画像に基づいて損失値を提供する損失関数を評価するステップと、
前記コンピューティングシステムによって、少なくとも部分的に前記損失関数に基づいて、前記機械学習した画像エンコーダ、前記機械学習した画像デコーダ、および、前記複数の候補コードのうちの1つまたは複数を変更するステップと
をさらに含む、請求項1から3のいずれか一項に記載のコンピュータ実装される方法。
【請求項5】
前記機械学習した画像デコーダがビジョントランスフォーマモデルを備える、請求項4に記載のコンピュータ実装される方法。
【請求項6】
前記損失関数が、
ロジットラプラス損失項、
L2損失項、
知覚損失項、および
敵対的生成ネットワーク損失項
を含む、請求項4または5に記載のコンピュータ実装される方法。
【請求項7】
前記コンピューティングシステムによって、前記複数の候補コードを含む前記量子化コードブックに含まれる前記複数の量子化コードに、前記複数の画像トークンをマッピングするステップが、
前記コンピューティングシステムによって、前記複数の画像トークンを下位次元空間に投影するステップと、
前記画像トークンを前記下位次元空間に投影するステップの後に、前記コンピューティングシステムによって、前記量子化コードブックに含まれる前記複数の量子化コードに、前記複数の画像トークンをマッピングするステップと
を含む、請求項1から6のいずれか一項に記載のコンピュータ実装される方法。
【請求項8】
前記コンピューティングシステムによって、前記複数の候補コードを含む前記量子化コードブックに含まれる前記複数の量子化コードに、前記複数の画像トークンをマッピングするステップが、
前記コンピューティングシステムによって、前記複数の画像トークンと前記複数の候補コードの一方または両方にL2正則化を適用するステップと、
前記L2正則化を適用するステップの後に、前記コンピューティングシステムによって、前記量子化コードブックに含まれる前記複数の量子化コードに、前記複数の画像トークンをマッピングするステップと
を含む、請求項1から7のいずれか一項に記載のコンピュータ実装される方法。
【請求項9】
機械学習したコード予測モデルを使用する前記コンピューティングシステムによって、少なくとも部分的に前記複数の量子化コードのうちの1つまたは複数に基づいて前記量子化コードブックから複数の予測されるコードを自己回帰的に予測するステップと、
前記コンピューティングシステムによって、機械学習した画像デコーダで前記複数の予測されるコードを処理して、合成画像を形成する複数の合成画像パッチを生成するステップと
をさらに含む、請求項1から8のいずれか一項に記載のコンピュータ実装される方法。
【請求項10】
前記コンピューティングシステムによって、前記複数の予測されるコードに基づいて負の対数尤度を評価するコード予測損失関数を評価するステップと、
前記コンピューティングシステムによって、前記コード予測損失関数に基づいて前記機械学習したコード予測モデルの1つまたは複数のパラメータを変更するステップと
をさらに含む、請求項9に記載のコンピュータ実装される方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
関連出願の相互参照
本出願は、2022年6月10日に出願された米国仮特許出願第63/351,131号および2021年10月5日に出願された米国仮特許出願第63/252,452号への優先権および利益を主張する。上述の出願の各々は、ここにその全体が参照によって組み込まれる。
続きを表示(約 2,200 文字)
【0002】
本開示は、一般的に、画像合成および/または画像生成などといった画像モデリングに関する。より具体的には、本開示は、ビジョントランスフォーマおよび改善したコードブック取扱いを使用するベクトル量子化した画像モデリングに関する。
【背景技術】
【0003】
コンピュータビジョンでは、最近の教師なしまたは自己教師あり学習技法の大部分は、画像インスタンスを区別する目的で事前訓練で画像に異なるランダムな拡張を施すことに焦点が合っており、学習した表現の品質は、ランダムな輝度、クロッピング、ぼけなどのような、手動で取り上げた拡張に依拠する。
【0004】
ある種の他の手法は、2D構造の知識を組み込むことなく、画素を自己回帰的に予測するために、画像にGPTスタイルの生成事前訓練を施す。ここで、画素は、k=512でのk平均を使用する(R,G,B)画素値をクラスタ化することによって、生成された9ビット値である。しかし、言語モデルのものよりも、はるかに長いシーケンス長(たとえば、224x224の解像度によって、画像毎に50176トークンとなる)ならびにはるかに大きいメモリ消費およびより多い訓練計算に起因して、色符号化は典型的な画像解像度にスケーリングされない。結果として、これらの制作物は、規模において、画像認識用に比較的小さい最大解像度(たとえば、64x64)に適用することが可能なだけであり、このことによって表現能力が著しく限定される。
【0005】
他方で、VQVAE(Oordら、2017)、DALL-E(Rameshら、2021)およびVQGAN(Esserら2021)を含む、顕著な画像生成結果が、画像を個別潜在変数へと予め量子化すること、およびそれらを自己回帰的にモデリングすることによって達成されている。これらの手法では、畳込みニューラルネットワーク(CNN)が学習して画像を自動符号化し、第2ステージCNNまたはトランスフォーマが学習して入力データの密度をモデル化する。これらは、画像生成には有効であることが証明されているが、特徴的なタスクにおける学習した表現を研究で評価していない。
【0006】
画像生成の1つの下位の分野は、テキストからの画像の生成である。ここでは、画像は入力テキストに基づいて合成され、合成された画像は、入力テキストによって記載されたコンテンツを描く。言語を通して画像を生成する能力は魅力的である。というのは、言語は意思疎通の最も自然な形式であり、そのような生成能力によって、芸術、デザイン、およびマルチメディアコンテンツ作成など多くの分野での創作的用途を潜在的に解放することができる。テキストから画像を生成する空間で最近勢いを得た研究の1つの系統は、より高い忠実度の画像を生成する能力を有する、拡散ベースのテキストからの画像モデルを活用する技法である。これらのモデルは、画像静止のための核となるモデリング手法として、個別の画像トークンの使用を避け、代わりに、拡散モデルを使用して、MS-COCOについてより良好なゼロショットフレシェ開始距離(FID)スコアおよび審美的に美しい視覚出力を達成する。こうした進歩にかかわらず、より多くのモダリティに容易に適用可能な、大規模言語モデルおよび個別のトークンの汎用インターフェースについて、従来の制作物に豊かな本体があることを仮定すると、テキストから画像を生成するタスクへの自己回帰モデリングを適用することができることは、実際には魅力的なままである。
【発明の概要】
【課題を解決するための手段】
【0007】
本開示の実施形態の態様および利点は、以下の記載に部分的に記述され、または、記載から学習することができ、または、実施形態の実施を通して学習することができる。
【0008】
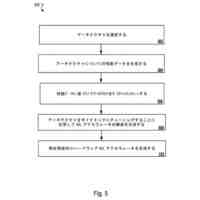
本開示に1つの例示的な態様は、画像のベクトル量子化を実施するコンピュータ実装される方法に向けられる。方法は、1つまたは複数のコンピューティングデバイスを備えるコンピューティングシステムによって、画像の複数の入力画像パッチを得るステップを含む。方法は、コンピューティングシステムによって、複数の入力画像パッチを機械学習した画像エンコーダで処理し、複数の画像トークンを潜在空間中に生成するステップを含み、ここで、複数の画像トークンが複数の入力画像パッチに対応し、機械学習した画像エンコーダが1つまたは複数の自己アテンション(self-attention)動作を実施して複数の入力画像パッチを処理し、複数の画像トークンを潜在空間中に生成する。方法は、コンピューティングシステムによって、複数の候補コードを含む量子化コードブックに含まれる複数の量子化コードに、複数の画像トークンをマッピングするステップを含む。方法は、コンピューティングシステムによって、画像の符号化バージョンとして複数の量子化コードを提供するステップを含む。
【0009】
いくつかの実装形態では、機械学習した画像エンコーダは、ビジョントランスフォーマモデルを備える。
【0010】
いくつかの実装形態では、機械学習した画像エンコーダは、複数の入力画像パッチに1つまたは複数の自己アテンション動作のうちの1つを実施する。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
グーグル エルエルシー
特定用途向け機械学習アクセラレータの生成およびグローバルなチューニング
1日前
個人
詐欺保険
1か月前
個人
縁伊達ポイン
1か月前
個人
5掛けポイント
27日前
個人
RFタグシート
1か月前
個人
職業自動販売機
20日前
個人
地球保全システム
2か月前
個人
ペルソナ認証方式
1か月前
個人
QRコードの彩色
1か月前
個人
情報処理装置
1か月前
個人
自動調理装置
1か月前
個人
農作物用途分配システム
1か月前
個人
残土処理システム
1か月前
個人
サービス情報提供システム
22日前
個人
タッチパネル操作指代替具
1か月前
個人
インターネットの利用構造
1か月前
個人
知的財産出願支援システム
1か月前
NISSHA株式会社
入力装置
今日
個人
学習用データ生成装置
1日前
個人
スケジュール調整プログラム
1か月前
個人
携帯端末障害問合せシステム
1か月前
株式会社キーエンス
受発注システム
2か月前
株式会社キーエンス
受発注システム
2か月前
株式会社キーエンス
受発注システム
2か月前
個人
エリアガイドナビAIシステム
1か月前
個人
食品レシピ生成システム
2か月前
株式会社ケアコム
項目選択装置
1か月前
株式会社ケアコム
項目選択装置
1か月前
個人
帳票自動生成型SaaSシステム
1か月前
キヤノン株式会社
画像認識装置
14日前
個人
音声・通知・再配達UX制御構造
1か月前
キヤノン株式会社
情報処理装置
14日前
キラル株式会社
顧客体験提供システム
2日前
キヤノン株式会社
情報処理装置
14日前
大同特殊鋼株式会社
疵判定方法
2か月前
トヨタ自動車株式会社
通知装置
1か月前
続きを見る
他の特許を見る

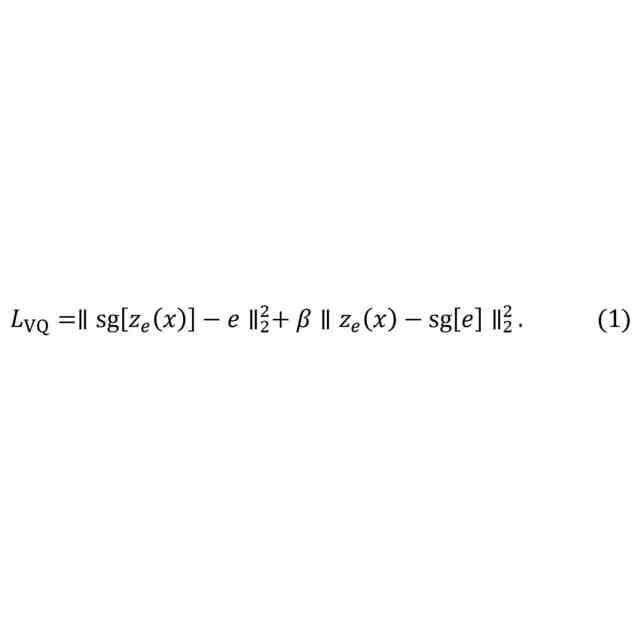






 特許ウォッチ
特許ウォッチ