TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025011875
公報種別
公開特許公報(A)
公開日
2025-01-24
出願番号
2023114271
出願日
2023-07-12
発明の名称
医療の支援装置
出願人
医療法人社団梅華会
代理人
個人
,
個人
主分類
G16H
20/00 20180101AFI20250117BHJP(特定の用途分野に特に適合した情報通信技術)
要約
【課題】患者の状態を示す幅広い情報を最低限の種類の人工知能によって処理し、患者の治療に活用される情報を生成すること。
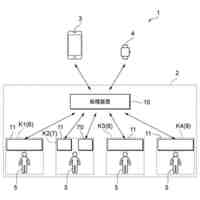
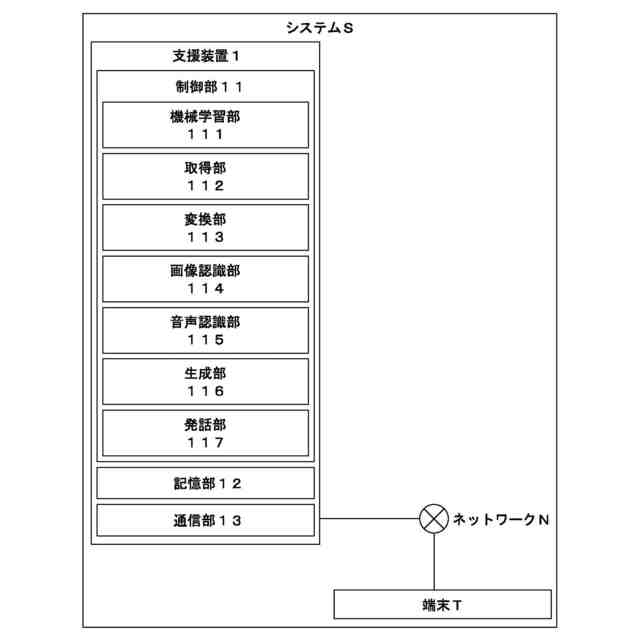
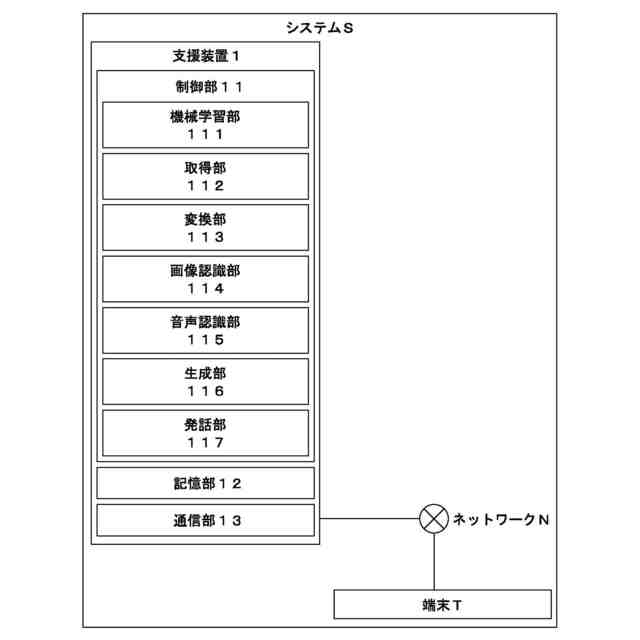
【解決手段】本発明の医療の支援装置1は、500GB以上のテキストによる事前学習が行われた大規模言語モデルに対し、患者の状態を示すテキスト及び患者の治療に活用される助言の組合せを学習データとした、当該助言の生成に係る機械学習を行う機械学習部111と、患者の状態を示すテキストを取得する取得部112と、上述の大規模言語モデルにテキストを入力し、当該大規模言語モデルに患者の治療に活用される助言を生成させる生成部116と、を備える。
【選択図】図1
特許請求の範囲
【請求項1】
500GB以上のテキストによる事前学習が行われた大規模言語モデルに対し、患者の状態を示すテキスト及び患者の治療に活用される助言の組合せを学習データとした、当該助言の生成に係る機械学習を行う機械学習部と、
患者の状態を示すテキスト(第1テキスト)を取得する取得部と、
前記大規模言語モデルに前記第1テキストを入力し、前記大規模言語モデルに前記患者の治療に活用される助言を生成させる生成部と、
を備える、医療の支援装置。
続きを表示(約 1,000 文字)
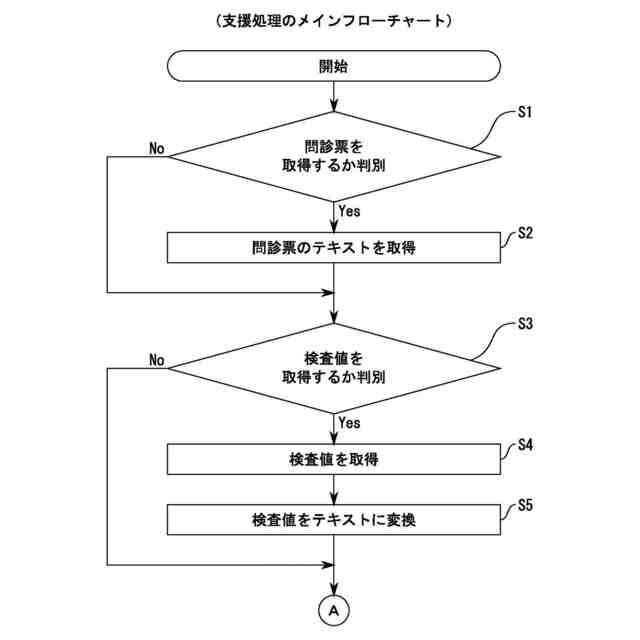
【請求項2】
前記患者が装着するウェアラブルデバイスから取得された検査値をテキスト(第2テキスト)に変換する変換部をさらに備え、
前記機械学習部は、検査値を示すテキストと前記検査値から想定される疾病を示す助言の組合せを学習データとした機械学習を行い、
前記取得部は、前記第2テキストを取得し、
前記生成部は、前記第2テキストを入力し、前記検査値から想定される疾病を示す助言を生成させる、
請求項1に記載の支援装置。
【請求項3】
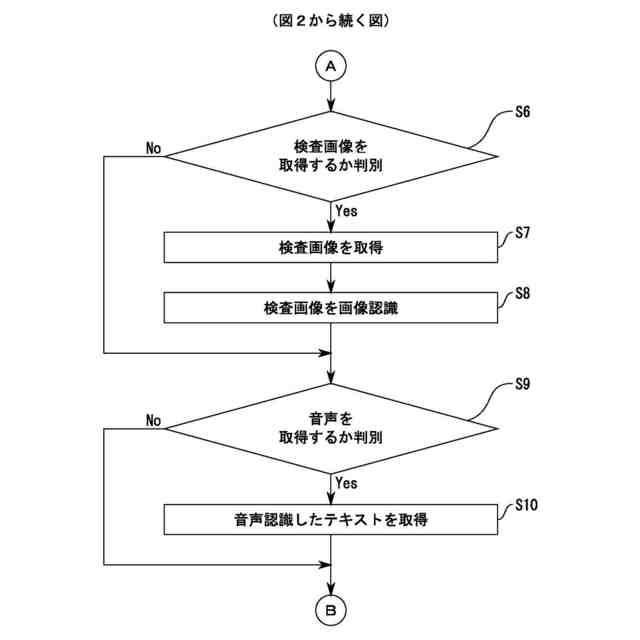
前記患者に係る検査画像を画像認識する画像認識部をさらに備え、
前記画像認識部は、画像認識の結果を示す第3テキストを生成し、
前記機械学習部は、検査画像に対する画像認識の結果を示すテキストと前記検査画像から想定される疾病を示す助言との組合せを学習データとした機械学習を行い、
前記取得部は、前記第3テキストを取得し、
前記生成部は、前記第3テキストを入力し、前記検査画像から想定される疾病を示す助言を生成させる、
請求項1に記載の支援装置。
【請求項4】
音声合成によって前記助言を発話する発話部をさらに備え、
前記取得部は、前記患者が発話した患者音声を音声認識して得られた第4テキストを取得し、
前記生成部は、前記第4テキストを入力する、
請求項1に記載の支援装置。
【請求項5】
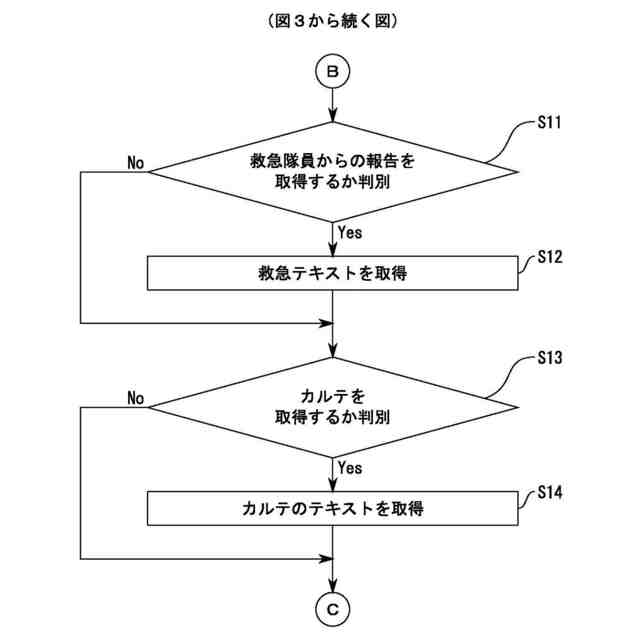
前記機械学習部は、救急隊員からの報告と当該報告から想定される疾病への対応に適した搬送先を示す助言との組合せを学習データとした機械学習を行い、
前記取得部は、前記患者を搬送する救急隊員により報告されたテキスト(第5テキスト)を取得し、
前記生成部は、前記第5テキストを入力し、前記搬送に係る疾病に適した搬送先を示す助言を生成させる、
請求項1に記載の支援装置。
【請求項6】
前記機械学習部は、臨床試験の被験者のカルテと当該臨床試験に求められる被験者数との組合せを学習データとした機械学習を行い、
前記取得部は、複数の前記カルテのテキスト(第6テキスト)を取得し、
前記生成部は、前記第6テキストを入力し、前記被験者数を示す助言を生成させる、
前記カルテに係る前記臨床試験に求められる被験者数を示す助言を生成させる、
請求項1に記載の支援装置。
発明の詳細な説明
【技術分野】
【0001】
本発明は、医療の支援装置に関する。
続きを表示(約 2,000 文字)
【背景技術】
【0002】
医療従事者において、問診票、カルテ、検査値、検査画像等によって例示される患者の状態を示す各種情報が患者の治療に活用されている。医療従事者の負担を低減すべく、これら各種情報を人工知能によって処理し、患者の治療に活用される情報を生成する技術が求められている。
【0003】
患者の治療に活用される情報を患者の状態を示す情報から生成することに関し、特許文献1は、データベースに基づいて医療情報を処理する人工知能エンジンを含む医療情報処理システムであって、医用画像を含む医療情報を受け付ける受付部と、前記データベースに基づいて、前記医用画像を予め設定された2以上のカテゴリのいずれかに分類する第1分類処理部と、前記医療情報に基づいて、前記2以上のカテゴリのいずれかを選択する選択処理部と、前記第1分類処理部により特定されたカテゴリと前記選択処理部により選択されたカテゴリとが一致しない場合、前記医用画像を特異カテゴリに分類する第2分類処理部とを備える医療情報処理システムを開示している。特許文献1の技術は、医用画像を用いた人工知能の学習等の処理を効果的に行い得る。
【先行技術文献】
【特許文献】
【0004】
特開2018-014059号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、特許文献1の技術は、医用画像を用いた人工知能の学習等の処理を効果的に行い得るにとどまり、問診票、カルテ、検査値、検査画像等によって例示される画像に限定されない幅広い情報を最低限の種類の人工知能によって処理し、患者の治療に活用される情報を生成する点において、さらなる改良の余地がある。
【0006】
本発明は係る事情にかんがみてなされたものであり、その目的は、患者の状態を示す幅広い情報を最低限の種類の人工知能によって処理し、患者の治療に活用される情報を生成することである。
【課題を解決するための手段】
【0007】
本発明者らは、上記課題を解決するために鋭意検討した結果、患者の状態を示す情報をテキストの態様で取得し、当該テキストを機械学習が予め行われた大規模言語モデルにおいて処理することによって、上記の目的を達成できることを見いだした。そして、本発明者らは、本発明を完成させるに至った。具体的に、本発明は以下のものを提供する。
【0008】
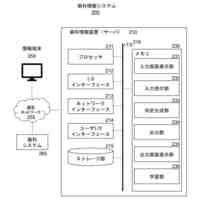
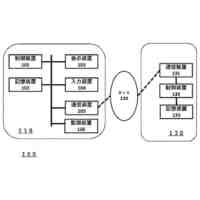
本発明は、500GB以上のテキストによる事前学習が行われた大規模言語モデルに対し、患者の状態を示すテキスト及び患者の治療に活用される助言の組合せを学習データとした、当該助言の生成に係る機械学習を行う機械学習部と、患者の状態を示すテキスト(第1テキスト)を取得する取得部と、前記大規模言語モデルに前記第1テキストを入力し、前記大規模言語モデルに前記患者の治療に活用される助言を生成させる生成部と、を備える、医療の支援装置を提供する。
【0009】
本発明は、取得部により、患者の状態を示す情報をテキストの態様で取得できる。しかしながら、自然言語で記述された問診票及びカルテ、検査値のテキスト等の各種テキスト情報は、記載スタイルがそれぞれ異なる。そのため、例えば、Mircosoft Azure(登録商標)のLUIS(Language Understanding)等の自然言語解析処理を行う人工知能によってこれら各種のテキスト情報を構造化すると、記載スタイルごとに異なる各種構造化情報が得られると考えられる。そのような各種構造化情報を扱う装置は、各種構造化情報に合わせた多種類の人工知能を用いる複雑な構成となることが懸念される。
【0010】
ところで、大量のテキストデータで事前訓練された言語モデルである大規模言語モデルは、入力として与えられた自然言語に対して、適切な応答を出力として生成し得ることが知られている。本発明は、500GB(ギガバイト)以上のテキストによる事前学習が行われた大規模言語モデルを用いる。言語モデルは、学習データ量が増大すると、その性能が「壊れたニューラルスケーリング則」(Broken Neural Scaling Laws、BNSL)に沿って増大し、BNSLにおいてセグメント間を遷移するときに創発的能力を獲得すると考えられる。そのため、当該大規模言語モデルは、事前学習に用いられたテキスト量に応じて獲得される、テキストの意味の特定に係る創発的能力を得ている。しかしながら、大規模言語モデルは、このような創発的能力を得ていても、患者の状態を示すテキストが入力された場合に患者の治療に活用される適切な助言を生成するか不明である。
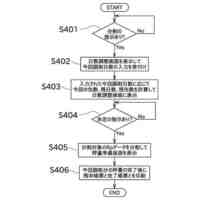
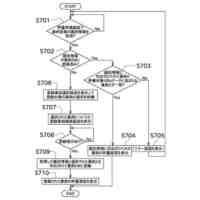
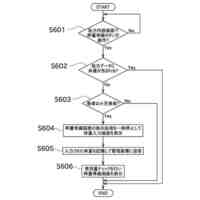
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
医療のAI化
1か月前
個人
支援システム
5か月前
個人
管理装置
4か月前
個人
対話システム
4か月前
個人
通知ぬいぐるみAIシステム
1か月前
個人
情報システムおよび方法
6か月前
キラル株式会社
ヘルスケアシステム
7日前
キラル株式会社
ヘルスケアシステム
7日前
株式会社タカゾノ
薬剤秤量装置
3か月前
株式会社タカゾノ
薬剤秤量装置
3か月前
株式会社タカゾノ
薬剤秤量装置
4か月前
株式会社タカゾノ
薬剤秤量装置
3か月前
株式会社タカゾノ
薬剤秤量装置
3か月前
株式会社タカゾノ
薬剤秤量装置
3か月前
株式会社リコー
投薬管理システム
1か月前
TOTO株式会社
健康管理システム
20日前
個人
診療の管理装置及び診療システム
3か月前
株式会社M-INT
情報処理システム
6か月前
ゾーン株式会社
コンピュータシステム
6か月前
大王製紙株式会社
作業管理システム
6か月前
株式会社CureApp
プログラム
3か月前
富士電機株式会社
食事管理システム
7か月前
株式会社サンクスネット
情報提供システム
5か月前
株式会社イシダ
受付端末装置
今日
株式会社 137
健康観察管理システム
5か月前
株式会社ミラボ
情報処理装置、及びプログラム
3か月前
西川株式会社
サービス出力システム
5か月前
合同会社フォース
オンライン診療システム
6か月前
株式会社タカゾノ
薬剤秤量装置及び調剤システム
4か月前
歯っぴー株式会社
口内状態の画像診断方法
2か月前
大和ハウス工業株式会社
服薬推定システム
20日前
キラル株式会社
プログラムの提供システムおよびその方法
23日前
二九精密機械工業株式会社
健康管理要素評価支援システム
4か月前
株式会社サンクスネット
健康医療情報管理システム
2か月前
HITOTSU株式会社
手術管理システム1
6か月前
株式会社エフアンドエフ
在宅健康チェックシステム
5か月前
続きを見る
他の特許を見る
 特許ウォッチ
特許ウォッチ