TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025010993
公報種別
公開特許公報(A)
公開日
2025-01-23
出願番号
2023113350
出願日
2023-07-10
発明の名称
言語モデル生成装置および言語モデル生成方法
出願人
Spiral.AI株式会社
代理人
個人
主分類
G06F
40/216 20200101AFI20250116BHJP(計算;計数)
要約
【課題】大規模な計算資源を要することなく領域特化の言語モデルの学習を実現できるようにする。
【解決手段】特定領域に限定しない文章データセットを用いて学習済みの大規模言語モデル(LLM)に対して追加される小規模言語モデル(SLM)を学習するSLM学習部10は、SLMからの出力文章が特定領域の知識を反映したものとなるように、特定領域に限定した文章データセットを用いて領域特化のための学習を行う第1のモデル学習部11を備え、汎用的に学習されたLLMより規模の小さいSLMを領域特化のために学習し、学習されたSLMをLLMと共に使用して推論可能な構成を提供することにより、大規模な計算資源を要することなく領域特化の言語モデルの学習を実現する。
【選択図】図1
特許請求の範囲
【請求項1】
特定領域に限定しない文章データセットを用いて学習済みの大規模言語モデルに対して追加される言語モデルであって、上記大規模言語モデルより規模の小さい小規模言語モデルを学習する小規模言語モデル学習部を備え、
上記小規模言語モデル学習部は、上記小規模言語モデルからの出力文章が特定領域の知識を反映したものとなるように、上記特定領域に限定した文章データセットを用いて領域特化のための学習を行うとともに、上記小規模言語モデルからの出力文章が所望の表現形態となるように、入出力対の文章から成る文章データセットを用いて表現形態調整に関するタスク特化のための学習を行う
ことを特徴とする言語モデル生成装置。
続きを表示(約 1,500 文字)
【請求項2】
上記小規模言語モデル学習部は、上記特定領域に限定した文章データセットを用いて上記領域特化のための学習を行った後に、上記入出力対の文章から成る文章データセットを用いて上記タスク特化のための追加学習を行うことを特徴とする請求項1に記載の言語モデル生成装置。
【請求項3】
上記領域特化のための学習を自己教師あり学習により行い、上記タスク特化のための学習を教師あり学習により行うことを特徴とする請求項1または2に記載の言語モデル生成装置。
【請求項4】
上記小規模言語モデル学習部は、
上記特定領域に限定した文章データセットを用いて上記領域特化のための自己教師あり学習を行うことにより、上記大規模言語モデルより規模の小さい領域特化型の小規模言語モデルを生成する第1のモデル学習部と、
上記入出力対の文章から成る文章データセットを用いて上記タスク特化のための教師あり学習を行うことにより、上記領域特化型の小規模言語モデルより規模の小さいタスク特化型の小規模言語モデルを生成する第2のモデル学習部とを備えた
ことを特徴とする請求項1に記載の言語モデル生成装置。
【請求項5】
上記第1のモデル学習部により生成された上記領域特化型の小規模言語モデルと上記第2のモデル学習部により生成された上記タスク特化型の小規模言語モデルとを統合するモデル統合部を更に備えたことを特徴とする請求項4に記載の言語モデル生成装置。
【請求項6】
上記大規模言語モデルと、上記第1のモデル学習部により生成された上記領域特化型の小規模言語モデルおよび上記第2のモデル学習部により生成された上記タスク特化型の小規模言語モデルの少なくとも一方とを統合するモデル統合部を更に備えたことを特徴とする請求項4に記載の言語モデル生成装置。
【請求項7】
上記第1のモデル学習部が上記領域特化型の小規模言語モデルを生成する際に用いた上記特定領域に限定した文章データセットを用いて、上記特定領域の知識を反映した入出力対の文章から成る文章データセットを生成するデータセット生成部を更に備え、
上記第2のモデル学習部は、上記データセット生成部により生成された文章データセットを用いて上記タスク特化のための教師あり学習を行う
ことを特徴とする請求項4に記載の言語モデル生成装置。
【請求項8】
上記小規模言語モデルはランクを設定可能なモデルであり、上記領域特化型の小規模言語モデルのランクよりも、上記タスク特化型の小規模言語モデルのランクを小さく設定することを特徴とする請求項4~7の何れか1項に記載の言語モデル生成装置。
【請求項9】
上記第1のモデル学習部は、上記領域特化型の小規模言語モデルとして、ランクを64より大きい何れかの値に設定したLoRAの学習を行うことを特徴とする請求項4~7の何れか1項に記載の言語モデル生成装置。
【請求項10】
特定領域に限定しない文章データセットを用いて学習済みの大規模言語モデルに対して追加される言語モデルであって、上記大規模言語モデルより規模の小さい小規模言語モデルを生成する言語モデル生成装置において、
上記特定領域に限定した文章データセットを用いて、上記小規模言語モデルからの出力文章が特定領域の知識を反映したものとなるように、ランクを64より大きい何れかの値に設定したLoRAの学習を行う小規模言語モデル学習部を備えたことを特徴とする言語モデル生成装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、言語モデル生成装置および言語モデル生成方法に関し、特に、特定領域に限定しない文章データセットを用いて学習済みの大規模言語モデルに対して追加される小規模言語モデルを生成する技術に関するものである。
続きを表示(約 2,200 文字)
【背景技術】
【0002】
従来、大規模言語モデル(LLM:Large Language Models)を用いて質疑応答などの自然言語処理を行うシステムが提供されている。LLMは、大量のテキストデータを使ってトレーニングされた自然言語処理のモデルのことであり、文章を入力とし、文章を出力する。質疑応答を行うシステムにLLMを適用した場合、LLMに質問文を入力すると、LLMから回答文が出力される。
【0003】
近年、LLMの利活用は進んでいるが、巨大な言語モデルを学習させるには、数百台を超える高価なGPU計算資源が要求される。そのため、幅広いデータを学習させて何にでも使い回せる「汎用型モデル」を開発することが中心となっている。一方、特定領域の文章をもとに学習させた「特化型モデル」の方がその特定領域において高い性能を期待でき、それを試みている例(例えば、Bloomberg GPT)も出てきている。特定領域の文章を学習させてその知識を埋め込む「領域特化」は、Knowledge-Injectionと呼ばれている。非特許文献1には、この領域特化の追加学習に関する手法が開示されている。しかしながら、いずれのモデルも数億円単位の巨額の資金を投じる必要があり、なかなか浸透していない。
【0004】
計算量を減らすための手法として、汎用に学習された大規模な事前学習済みモデル(Pre-Trained Language Model:PLM)から出発して、小規模なモデルを加えて追加学習(fine-tuning)する手法も存在する。また、さらに計算量やメモリ消費量を減らすために、LoRA(Low-Rank Adaptation)という手法も開発されている。ただし、これらは主に、文語体を出力するかわりに口語体で出力するとか、長い文章ではなく歯切れのよい会話形式で出力するといったように、PLMの出力形態を変更するなどの「タスク特化」のために利用されてきた。
【先行技術文献】
【特許文献】
【0005】
“Plug-and-Play Knowledge Injection for Pre-trained Language Models”(ACL Rolling Review - June 2022, 2022.6.6 (modified:2023.5.6) <URL:https://openreview.net/forum?id=f4RClsuGaHS>
【発明の概要】
【発明が解決しようとする課題】
【0006】
本発明は、このような実情に鑑みて成されたものであり、大規模な計算資源を要することなく領域特化の言語モデルの学習を実現できるようにすることを目的とする。
【課題を解決するための手段】
【0007】
上記した課題を解決するために、本発明は、特定領域に限定しない文章データセットを用いて学習済みの大規模言語モデルに対して追加される小規模言語モデルを学習するものであり、小規模言語モデルからの出力文章が特定領域の知識を反映したものとなるように、特定領域に限定した文章データセットを用いて領域特化のための学習を行うとともに、小規模言語モデルからの出力文章が所望の表現形態となるように、入出力対の文章から成る文章データセットを用いて表現形態調整に関するタスク特化のための学習を行うようにしている。
【発明の効果】
【0008】
上記のように構成した本発明によれば、特定領域に限定しない文章データセットを用いて汎用的に学習された大規模言語モデルより規模の小さい小規模言語モデルが領域特化のために学習され、学習された小規模言語モデルを大規模言語モデルと共に使用して推論可能な構成が提供されるので、大規模な計算資源を要することなく領域特化の言語モデルの学習を実現することができる。さらに本発明では、小規模言語モデルに対して表現形態調整に関するタスク特化のための学習も行われるので、大規模な計算資源を要することなく領域特化およびタスク特化の言語モデルの学習を実現することができる。
【図面の簡単な説明】
【0009】
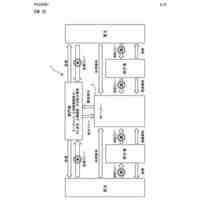
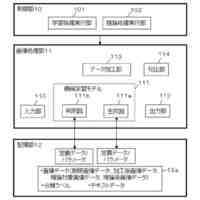
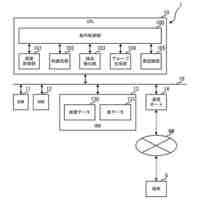
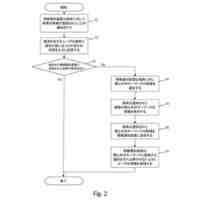
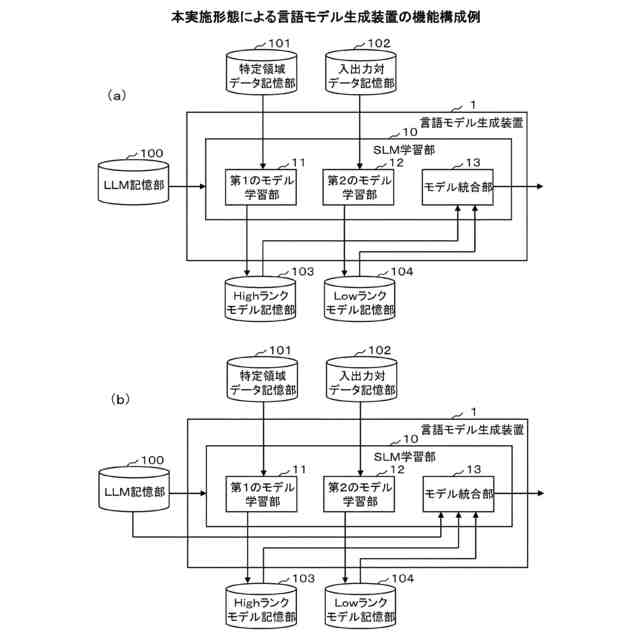
本実施形態による言語モデル生成装置の機能構成例を示すブロック図である。
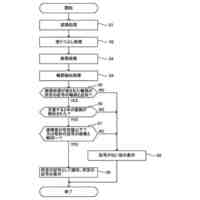
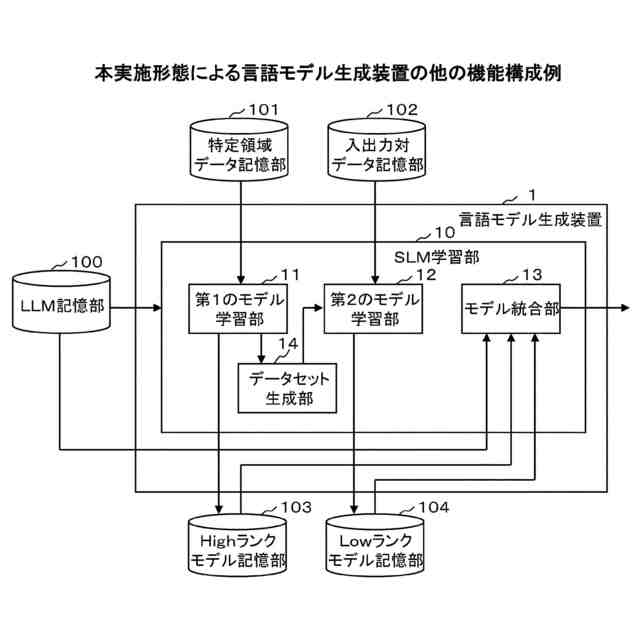
本実施形態による言語モデル生成装置の他の機能構成例を示すブロック図である。
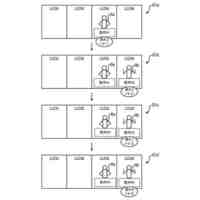
データセット生成部による文章データの生成例を示す図である。
【発明を実施するための形態】
【0010】
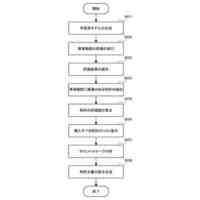
以下、本発明の一実施形態を図面に基づいて説明する。図1は、本実施形態による言語モデル生成装置1の機能構成例を示すブロック図である。本実施形態の言語モデル生成装置1は、機能構成として、小規模言語モデル学習部10を備えている。以下では、小規模言語モデル学習部10を“SLM学習部10”と略す(SLM:Small Language Models)。SLM学習部10は、具体的な機能構成として、第1のモデル学習部11、第2のモデル学習部12およびモデル統合部13を備える。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
情報提示方法
12日前
個人
RFタグ読取装置
29日前
個人
アカウントマップ
5日前
個人
プログラム
4日前
個人
自動精算システム
1か月前
個人
自動精算システム
20日前
個人
プログラム
11日前
個人
売買システム
26日前
個人
管理サーバ
1か月前
個人
発想支援方法及びシステム
15日前
個人
市場受発注システム
18日前
日本精機株式会社
車両用表示装置
28日前
キヤノン株式会社
印刷装置
1か月前
個人
分類処理プログラム及び方法
15日前
日本精機株式会社
車両用表示装置
28日前
個人
学習装置及び推論装置
4日前
個人
VRによる人体各部位の立体化
1か月前
富士通株式会社
金融システム
12日前
井関農機株式会社
ロボット作業車両
20日前
キヤノン株式会社
情報処理装置
1か月前
個人
未来型家系図構築システム
1か月前
トヨタ自動車株式会社
推定装置
1か月前
株式会社SEKT
文字認識装置
1か月前
トヨタ自動車株式会社
表認識装置
1か月前
株式会社プレニーズ
仲介システム
5日前
トヨタ自動車株式会社
情報通知方法
18日前
トヨタ自動車株式会社
記号識別方法
1か月前
ブラザー工業株式会社
無線通信装置
18日前
トヨタ自動車株式会社
作業管理装置
18日前
個人
情報処理装置およびプログラム
1か月前
村田機械株式会社
人員配置システム
15日前
個人
販売支援システム
20日前
トヨタ自動車株式会社
作業評価装置
1か月前
富士通株式会社
情報処理プログラム
1か月前
トヨタ自動車株式会社
画像処理装置
1か月前
ダイハツ工業株式会社
移動支援装置
1か月前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ