TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025164490
公報種別
公開特許公報(A)
公開日
2025-10-30
出願番号
2024068497
出願日
2024-04-19
発明の名称
評価装置、評価方法及び評価プログラム
出願人
KDDI株式会社
代理人
個人
主分類
G06F
40/279 20200101AFI20251023BHJP(計算;計数)
要約
【課題】現実的な攻撃者を想定したうえで、言語モデルのプライバシーリスクを評価できる評価装置を提供すること。
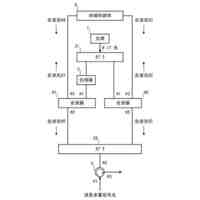
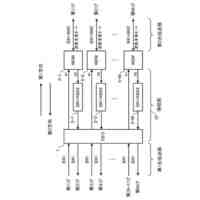
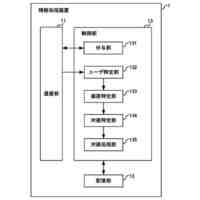
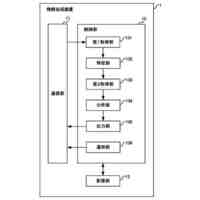
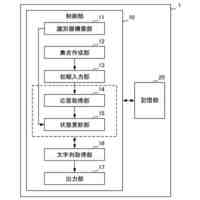
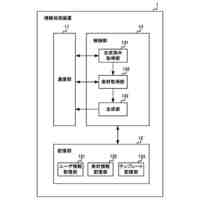
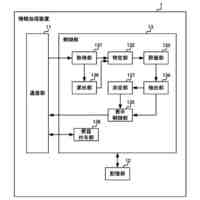
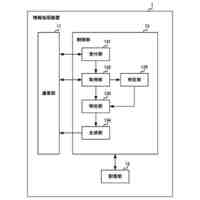
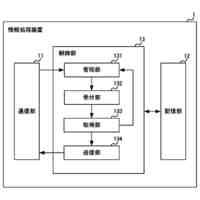
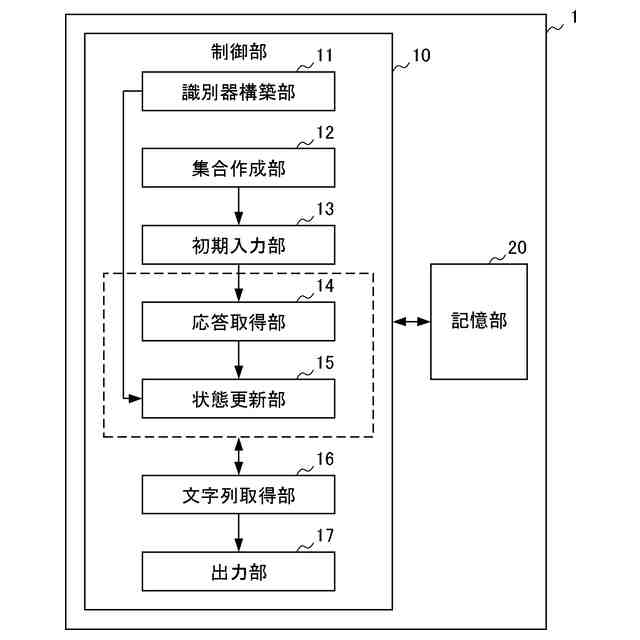
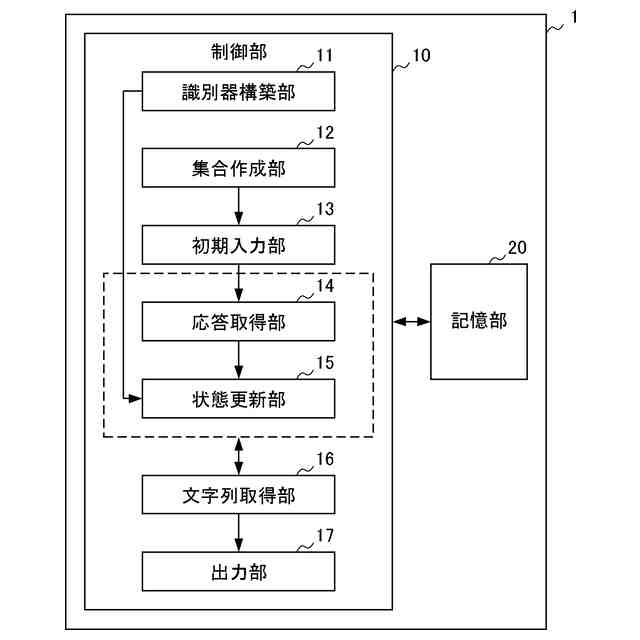
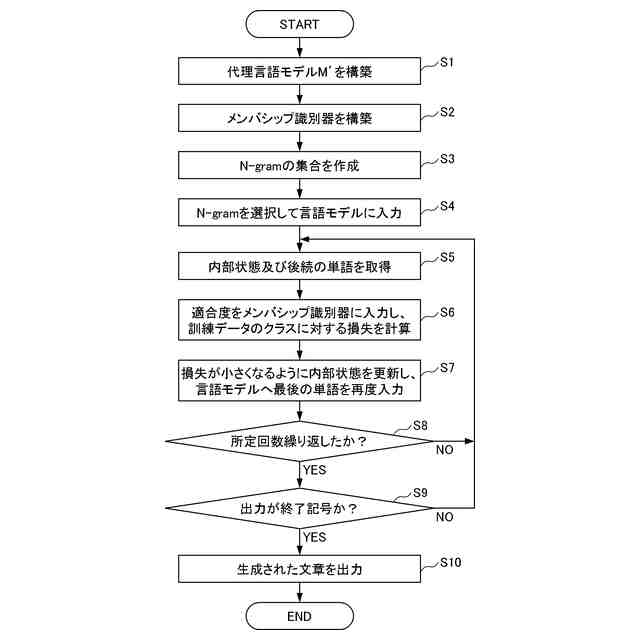
【解決手段】評価装置1は、代理言語モデルを用いてメンバシップ識別器を構築する識別器構築部11と、データセットからN-gramの集合を作成する集合作成部12と、集合から選択したN-gramを評価対象の言語モデルに入力する初期入力部13と、入力されたトークンに対する応答として後続のトークン及び内部状態を取得する応答取得部14と、応答に対して、メンバシップ識別器により訓練データのクラスに対する損失を計算し、当該損失が小さくなるように内部状態を更新した後、直前に入力したトークンを再度入力する状態更新部15と、応答取得部14及び状態更新部15の処理を所定回繰り返し実行させて、終了記号が得られるまで文字列の一部の取得を繰り返す文字列取得部16と、得られた文字列を出力する出力部17と、を備える。
【選択図】図1
特許請求の範囲
【請求項1】
評価対象の言語モデルの訓練データ集合と類似したデータセットにより構築した代理言語モデル、及び当該データセットを用いて、前記代理言語モデルへの入力が訓練データか否かを応答から推定するためのメンバシップ識別器を構築する識別器構築部と、
前記データセットに含まれるテキストから、N-gramの集合を作成する集合作成部と、
前記集合から選択したN-gramに続く文字列を生成するため、当該N-gramを構成するトークンを順次、前記評価対象の言語モデルに入力する初期入力部と、
前記評価対象の言語モデルから、入力されたトークンに対する応答として後続のトークン及び内部状態を取得する応答取得部と、
前記応答に対して、前記メンバシップ識別器により前記訓練データのクラスに対する損失を計算し、当該損失が小さくなるように前記内部状態を更新した後、直前に入力したトークンを前記評価対象の言語モデルへ再度入力する状態更新部と、
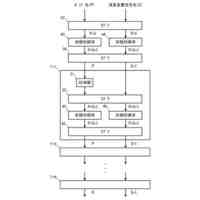
前記応答取得部及び前記状態更新部の処理を所定回繰り返し実行させて、前記評価対象の言語モデルから後続のトークンを前記文字列の一部として取得すると、当該取得したトークンが終了記号でない場合、当該トークンを前記評価対象の言語モデルに入力し、終了記号が得られるまで前記文字列の一部の取得を繰り返す文字列取得部と、
前記文字列取得部により得られた前記文字列を、前記評価対象の言語モデルから復元可能な情報として、プライバシーリスク評価のために出力する出力部と、を備える評価装置。
続きを表示(約 1,100 文字)
【請求項2】
前記初期入力部は、前記集合から、高頻度のN-gramを優先して選択する請求項1に記載の評価装置。
【請求項3】
前記識別器構築部は、前記代理言語モデルに入力された一連のトークンに出力のトークンを連結したデータの、前記評価対象の言語モデルに対する適合度を入力とする前記メンバシップ識別器を構築する請求項1に記載の評価装置。
【請求項4】
前記識別器構築部は、前記代理言語モデルの内部状態を入力とする前記メンバシップ識別器を構築する請求項1に記載の評価装置。
【請求項5】
前記初期入力部は、前記N-gramの選択を繰り返し、
前記出力部は、複数の前記文字列を出力する請求項1から請求項4のいずれかに記載の評価装置。
【請求項6】
コンピュータが、
識別器構築部により、評価対象の言語モデルの訓練データ集合と類似したデータセットにより構築した代理言語モデル、及び当該データセットを用いて、前記代理言語モデルへの入力が訓練データか否かを応答から推定するためのメンバシップ識別器を構築し、
集合作成部により、前記データセットに含まれるテキストから、N-gramの集合を作成し、
初期入力部により、前記集合から選択したN-gramに続く文字列を生成するため、当該N-gramを構成するトークンを順次、前記評価対象の言語モデルに入力し、
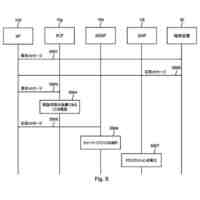
応答取得部により前記評価対象の言語モデルから、入力されたトークンに対する応答として後続のトークン及び内部状態を取得し、
状態更新部により、前記応答に対して、前記メンバシップ識別器により前記訓練データのクラスに対する損失を計算し、当該損失が小さくなるように前記内部状態を更新した後、直前に入力したトークンを前記評価対象の言語モデルへ再度入力し、
文字列取得部により、前記応答取得部及び前記状態更新部の処理を所定回繰り返し実行させて、前記評価対象の言語モデルから後続のトークンを前記文字列の一部として取得すると、当該取得したトークンが終了記号でない場合、当該トークンを前記評価対象の言語モデルに入力し、終了記号が得られるまで前記文字列の一部の取得を繰り返し、
出力部により、前記文字列取得部により得られた前記文字列を、前記評価対象の言語モデルから復元可能な情報として、プライバシーリスク評価のために出力する評価方法。
【請求項7】
請求項1から請求項4のいずれかに記載の評価装置としてコンピュータを機能させるための評価プログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、言語モデルのプライバシーリスクを評価するための技術に関する。
続きを表示(約 1,900 文字)
【背景技術】
【0002】
言語モデルの大規模化が進み、文章生成の汎用性が向上する一方、言語モデルの情報漏洩に関する負の影響の一つとして、訓練データの漏洩など、プライバシーリスクの問題が指摘され始めている。
例えば、非特許文献1により、対象の言語モデルの入出力から訓練データに含まれていたセンシティブな固有名詞を復元できる可能性が示されている。本文献では、センシティブな固有名詞がマスクされた訓練データが与えられた際に、固有名詞の直前までの文章を対象の言語モデルに入力することで、マスクされた固有名詞の復元が試みられている。
【0003】
また、機械学習モデルの訓練データを推定する攻撃としては、非特許文献2で示されたメンバシップ推定攻撃がある。メンバシップ推定攻撃では、攻撃者は、訓練データと類似のデータセットを用いて、モデルの出力からあるデータが訓練データかどうかを判定するためのメンバシップ識別器を構築する。そして、攻撃者は、何らかのデータが与えられた際に、構築したメンバシップ識別器を用いて、このデータが対象のモデルの訓練データだったかどうかを推定する。
【先行技術文献】
【非特許文献】
【0004】
N. Lukas et al., Analyzing Leakage of Personally Identifiable Information in Language Model, IEEE S&P 2023.
R. Shokri et al., Membership Inference Attacks against Machine Learning Models, IEEE S&P 2017.
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、非特許文献1の手法は、固有名詞がマスクされた訓練データを入手できることが前提のため、現実的な攻撃者を想定した評価が十分にできなかった。また、非特許文献2の手法でも、同様に何らかのデータが与えられることを前提としており、メンバシップ推定器を訓練データの復元に利用する方法は知られていない。
【0006】
本発明は、現実的な攻撃者を想定したうえで、言語モデルのプライバシーリスクを評価できる評価装置、評価方法及び評価プログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
本発明に係る評価装置は、評価対象の言語モデルの訓練データ集合と類似したデータセットにより構築した代理言語モデル、及び当該データセットを用いて、前記代理言語モデルへの入力が訓練データか否かを応答から推定するためのメンバシップ識別器を構築する識別器構築部と、前記データセットに含まれるテキストから、N-gramの集合を作成する集合作成部と、前記集合から選択したN-gramに続く文字列を生成するため、当該N-gramを構成するトークンを順次、前記評価対象の言語モデルに入力する初期入力部と、前記評価対象の言語モデルから、入力されたトークンに対する応答として後続のトークン及び内部状態を取得する応答取得部と、前記応答に対して、前記メンバシップ識別器により前記訓練データのクラスに対する損失を計算し、当該損失が小さくなるように前記内部状態を更新した後、直前に入力したトークンを前記評価対象の言語モデルへ再度入力する状態更新部と、前記応答取得部及び前記状態更新部の処理を所定回繰り返し実行させて、前記評価対象の言語モデルから後続のトークンを前記文字列の一部として取得すると、当該取得したトークンが終了記号でない場合、当該トークンを前記評価対象の言語モデルに入力し、終了記号が得られるまで前記文字列の一部の取得を繰り返す文字列取得部と、前記文字列取得部により得られた前記文字列を、前記評価対象の言語モデルから復元可能な情報として、プライバシーリスク評価のために出力する出力部と、を備える。
【0008】
前記初期入力部は、前記集合から、高頻度のN-gramを優先して選択してもよい。
【0009】
前記識別器構築部は、前記代理言語モデルに入力された一連のトークンに出力のトークンを連結したデータの、前記評価対象の言語モデルに対する適合度を入力とする前記メンバシップ識別器を構築してもよい。
【0010】
前記識別器構築部は、前記代理言語モデルの内部状態を入力とする前記メンバシップ識別器を構築してもよい。
(【0011】以降は省略されています)
特許ウォッチbot のツイートを見る
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
KDDI株式会社
光増幅器
1か月前
KDDI株式会社
光増幅器
1か月前
KDDI株式会社
光接続ノード
1か月前
KDDI株式会社
緊急ネットワーク分離方法
1か月前
KDDI株式会社
無線デバイス及びプログラム
9日前
KDDI株式会社
基地局及び基地局の制御方法
29日前
KDDI株式会社
情報処理装置及び情報処理方法
1か月前
KDDI株式会社
情報処理装置及び情報処理方法
29日前
KDDI株式会社
情報処理装置及び情報処理方法
1か月前
KDDI株式会社
情報処理装置及び情報処理方法
1か月前
KDDI株式会社
情報処理装置及び情報処理方法
1か月前
KDDI株式会社
情報処理装置及び情報処理方法
1か月前
KDDI株式会社
制御装置、方法及びプログラム
1か月前
KDDI株式会社
情報処理装置及び情報処理方法
1か月前
KDDI株式会社
情報処理装置及び情報処理方法
1か月前
KDDI株式会社
基地局装置およびその通信方法
1か月前
KDDI株式会社
通信制御システム及び通信制御方法
1か月前
KDDI株式会社
情報処理装置、方法及びプログラム
29日前
KDDI株式会社
基地局装置、端末装置及び無線通信方法
29日前
KDDI株式会社
情報処理装置、学習装置及びプログラム
1か月前
KDDI株式会社
評価装置、評価方法及び評価プログラム
9日前
KDDI株式会社
飛行体、情報処理装置及び情報処理方法
1か月前
KDDI株式会社
通信装置、無線デバイス及びプログラム
1か月前
KDDI株式会社
ログ処理装置、端末、方法及びプログラム
24日前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
プログラム、情報処理端末及び情報処理方法
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
画像復号装置、画像復号方法及びプログラム
17日前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
1か月前
続きを見る
他の特許を見る
 特許ウォッチ
特許ウォッチ