TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025162971
公報種別
公開特許公報(A)
公開日
2025-10-28
出願番号
2025036203
出願日
2025-03-07
発明の名称
対話型時系列分析システムおよびその方法
出願人
株式会社日立製作所
代理人
青稜弁理士法人
主分類
G06F
16/732 20190101AFI20251021BHJP(計算;計数)
要約
【課題】時間の経過とともに刻々と変化するイベントの意味を動的に解釈したり、時間に関する抽象的で曖昧さのないクエリのための会話インタフェースを利用する対話型時系列分析のためのシステムおよび方法を提供する。
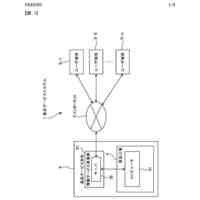
【解決手段】対話型時系列分析システムは、複数のビデオを管理する大容量データストレージ300と、クエリを受信すると、クエリに関連する複数のビデオからのビデオの各フレーム上の少なくとも1つのオブジェクトの確率情報を計算し、過去から指定時刻までの確率情報に基づいて指定時刻の少なくとも1つのオブジェクトの状態を計算し、クエリに応答する自然言語出力で分析と予測を出力する大規模言語モデル(LLM)に指定時刻の状態を入力する時系列解析コンポーネント100と、を含む。
【選択図】図2
特許請求の範囲
【請求項1】
複数のビデオを管理するデータベースと、
問い合わせを受信するように構成された処理部と、を有し、
前記処理部は、
複数のビデオからクエリに関連するビデオの各フレームの少なくとも1つのオブジェクトの確率情報を計算し、
過去から指定された時間までの確率情報に基づいて、指定された時間における少なくとも1つのオブジェクトの状態を計算し、
クエリに応答する自然言語出力で分析と予測を出力するように構成された大規模言語モデル(LLM)に、指定された時間の状態を入力する
対話型時系列分析システム。
続きを表示(約 1,200 文字)
【請求項2】
請求項1に記載の対話型時系列分析システムにおいて、
前記処理部は、過去および現在の確率情報を統合することにより、指定された時刻における前記少なくとも1つの物体の状態を計算するように構成されている、
対話型時系列分析システム。
【請求項3】
請求項1に記載の対話型時系列分析システムにおいて、
前記LLMは、前記確率情報の入力と、前記指定された時間における前記少なくとも1つのオブジェクトの状態とに基づいて、対話応答を生成する
対話型時系列分析システム。
【請求項4】
請求項1に記載の対話型時系列分析システムにおいて、
前記処理部は、
前記少なくとも1つの物体の動的変化を組み込んだ確率モデルを用いて、前記指定された時間の状態を計算するように構成されている
対話型時系列分析システム。
【請求項5】
請求項1に記載の対話型時系列分析システムにおいて、
前記処理部は、
将来の確率情報を予測することにより、指定された時間の状態を計算し、将来の確率情報をLLMへの入力として使用することから、将来の事象の分析および予測を容易にするように構成されている
対話型時系列分析システム。
【請求項6】
請求項1に記載の対話型時系列分析システムにおいて、
前記LLMは、
生成された対話応答とユーザからの追加情報要求のコンテキストに応じて、応答を動的に調整するように構成されている
対話型時系列分析システム。
【請求項7】
請求項1に記載の対話型時系列分析システムにおいて、
前記LLMは、
将来の確率情報に基づく自然言語出力における予測を、警告、提案、または行動指示のうちの1つ以上として出力するように構成されている
対話型時系列分析システム。
【請求項8】
請求項1に記載の対話型時系列分析システムにおいて、
前記処理部は、
前記確率情報を計算する前に、前処理手順によりラベル情報を最適化するように構成されている
対話型時系列分析システム。
【請求項9】
請求項1に記載の対話型時系列分析システムにおいて、
前記LLMは、
外部知識ベースからの文脈情報を統合するために、入力に応答してRAG(Retriever-Augmented Generation)ベースのアプローチを実行するように構成されている
対話型時系列分析システム。
【請求項10】
請求項1に記載の対話型時系列分析システムにおいて、
前記処理部は、
ユーザとの対話から指定された時間の確率情報および少なくとも1つのオブジェクトの状態の計算に使用されるモデルを改良するためのフィードバック機構を実行する
対話型時系列分析システム。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本開示は、一般的に工場システム、より具体的には、大規模言語モデル(LLM)の使用によるビデオコンテンツの解釈およびテキストコンテキストに基づく拡張検索に向けられている。特に、本開示はゼロショット推論とテキストコンテキストに基づく拡張検索による映像コンテンツ解釈のための対話型時系列分析システムおよびその方法に向けられている。
続きを表示(約 2,100 文字)
【背景技術】
【0002】
製造業では、ヒューマンエラーによる生産停止が頻発し、大きな課題となっている。歴史的に、個々の作業員の行動やパターンの記録は紙で保管され、デジタル化されてこなかったため、このようなヒューマンエラーを効率的に理解し、防止するにはギャップが残っている。
【0003】
製造現場における人間の行動パターンのデジタル化に対する期待は、工場の停止を緩和し、業務効率を向上させることを目的として高まっている。人工知能(AI)の最近の進歩、特にビデオ解析のための機械学習モデルは、このニーズに対応し始めている。これらの進歩は、単一の画像の分析にとどまらず、ビデオフレームのコンテキスト分析を可能にし、リアルタイムでビジュアルデータのニュアンスに富んだ正確な解釈を提供する。
【発明の概要】
【発明が解決しようとする課題】
【0004】
古くから研究されてきた教師あり学習AIの応用は、こうしたパターンのデジタル化に一定の効果を示し、生産ボトルネックの分析や生産性最大化の可能性につながっている。しかし、このアプローチには、AIモデルの最適化に多大な労力を要することや、異なる拠点間での水平展開の難しさなどの課題がある。
【0005】
さらに、大規模言語モデル(LLM)、対照言語画像事前学習(CLIP)などの基礎モデルは、ゼロショット学習のためのエキサイティングな機会を提供し、特定の訓練なしで新しいデータに使用することができる。これらは、分類、物体認識、画像キャプション付けにおいて有望な応用を実証している。これにより、モデルの訓練と展開に必要な時間とリソースを大幅に削減することができる。とはいえ、入力データの品質に依存するため、出力には無関係な情報や不正確な情報が含まれる可能性があり、精度と信頼性に課題がある。特に、検出対象外の物体が含まれるような複雑な背景を持つ映像の解析などでは、精度は高くない。
【0006】
このような背景から、製造業は変革期を迎えており、最適化されたAIモデルを通じて人間の行動パターンをデジタル化することで、新たなレベルの生産性と業務上の洞察力を引き出すことができる。現場に最適化されたAIの精度の高さと、基礎的なモデルの適用範囲は広いが精度は低いことのバランスは、極めて重要な開発分野である。
【0007】
基礎モデルを使用する既存の技術は、主にオブジェクトの検出と画像の分類に重点を置いており、コンテキストや時間的分析を深く統合していない。例えば、従来の機械学習モデルは、1つのフレーム内のオブジェクトや異常を識別することはできても、シーケンスや経時的な変化の重要性を理解することに苦労している。関連技術の実装には、ビデオ解析や異常検出に対する様々なアプローチが含まれるが、文脈の理解とインタラクティブ性を強化するための自然言語処理(NLP)の統合が欠けていることが多い。市場に出回っている製品やサービスは、基本的なビデオ解析を提供しているかもしれないが、ビジュアルデータの解釈と自然言語理解の間の相乗効果を十分に活用していない。
【0008】
関連技術の実施態様では、ビデオデータを照会する方法がある。映像データを、画像フレーム、音声データ、同一キャプションに関連するキャプションデータに基づいて、ショット毎に分割し、各ショットの特徴量をベクトル情報として抽出する。各ショットのベクトル情報を多層ニューラルネットワークでまとめて処理することで、映像データ全体の特徴ベクトルを生成する。比較特徴ベクトルとの類似度に基づいて、映像ストレージから最適な映像データが選択される。このような関連技術の実装では、フレーム単位での時系列分析は行われない。
【0009】
別の関連技術の実装では、ラベル付けされたデータの必要性を回避して、テキスト記述から直接学習するコンピュータビジョンシステムがある。ウェブ上で収集された4億の画像とテキストのペアで事前学習することにより、このような関連技術モデルは、自然言語を使用して視覚的概念を識別および記述し、タスク固有の訓練なしで多様なタスクにわたるゼロショット分類を可能にする。この関連アート手法は、ImageNetにおけるResNet-50のような従来の完全教師ありモデルの性能に匹敵し、大幅な適応性と効率性を示している。しかし、このアプローチは時系列情報処理を伴わず、代わりに視覚認識のための自然言語の活用に焦点を当てている。
【0010】
本明細書で説明する実装例は、このような課題を解決するものであり、ヒューマンエラーを最小化し、製造効率を向上させるために、両方のアプローチの長所を活用した新規のソリューションを提供するものである。本明細書で説明する実施例は、人間の行動のデジタル化だけでなく、他の装置、材料、自律走行車(AGV)などのデジタル化にも適用することができる。理解を容易にするため、本明細書で説明する実施例は、人間の行動のデジタル化に関して説明するが、これに限定されるものではない。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
詐欺保険
1か月前
個人
縁伊達ポイン
1か月前
個人
5掛けポイント
13日前
個人
RFタグシート
24日前
個人
職業自動販売機
6日前
個人
地球保全システム
1か月前
個人
QRコードの彩色
1か月前
個人
ペルソナ認証方式
21日前
個人
自動調理装置
23日前
個人
情報処理装置
16日前
個人
残土処理システム
1か月前
個人
農作物用途分配システム
1か月前
個人
サービス情報提供システム
8日前
個人
インターネットの利用構造
20日前
個人
知的財産出願支援システム
1か月前
個人
タッチパネル操作指代替具
1か月前
個人
携帯端末障害問合せシステム
29日前
個人
スケジュール調整プログラム
29日前
株式会社キーエンス
受発注システム
1か月前
株式会社キーエンス
受発注システム
1か月前
株式会社キーエンス
受発注システム
1か月前
個人
食品レシピ生成システム
1か月前
個人
エリアガイドナビAIシステム
21日前
キヤノン株式会社
情報処理装置
14日前
株式会社ケアコム
項目選択装置
16日前
株式会社ケアコム
項目選択装置
16日前
株式会社ワコム
電子ペン
15日前
キヤノン株式会社
印刷システム
29日前
株式会社ワコム
電子ペン
15日前
エッグス株式会社
情報処理装置
1か月前
トヨタ自動車株式会社
通知装置
27日前
キヤノン株式会社
画像認識装置
今日
キヤノン株式会社
情報処理装置
今日
個人
帳票自動生成型SaaSシステム
1か月前
キヤノン株式会社
情報処理装置
今日
個人
音声・通知・再配達UX制御構造
1か月前
続きを見る
他の特許を見る








 特許ウォッチ
特許ウォッチ