TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025160881
公報種別
公開特許公報(A)
公開日
2025-10-23
出願番号
2025026947
出願日
2025-02-21
発明の名称
発話言語理解のためのシステムおよび方法
出願人
株式会社東芝
代理人
弁理士法人鈴榮特許綜合事務所
主分類
G10L
15/10 20060101AFI20251016BHJP(楽器;音響)
要約
【課題】より少ない計算リソースで発話言語理解を行うシステムおよび方法を提供する。
【解決手段】発話言語理解を実施するためのコンピュータ実装方法は、音声を含むオーディオを表すデータを受信することと、音声の内容に対応するテキストを決定するためのモデルを使用してデータを処理することと、1つまたは複数の意味論的ラベルのテキストに基づく表現を備えた、言語理解タスクを実施するための入力を受信することと、モデルの少なくとも部分を使用して入力を処理して、音声の内容に対応するテキストから意味論的情報を抽出することと、言語理解タスクに関して抽出された意味論的情報を取得することと、を実行する。
【選択図】図1
特許請求の範囲
【請求項1】
発話言語理解を実施するためのコンピュータ実装方法であって、
音声を備えたオーディオを表すデータを受信することと、
前記音声の内容に対応するテキストを決定するためのモデルを使用して前記データを処理することと、
言語理解タスクを実施するための入力を受信することと、前記入力が1つまたは複数の意味論的ラベルのテキストに基づく表現を備え、
前記モデルの少なくとも部分を使用して前記入力を処理して、前記音声の前記内容に対応する前記テキストから前記言語理解タスクのための意味論的情報を抽出することと、
前記言語理解タスクに関して前記抽出された意味論的情報を取得することと
を備える、コンピュータ実装方法。
続きを表示(約 1,300 文字)
【請求項2】
前記モデルがトランスフォーマーに基づくモデルを備える、請求項1に記載のコンピュータ実装方法。
【請求項3】
前記モデルが、エンコーダと、前記エンコーダに動作可能に結合されたデコーダとを備え、
前記データの前記処理が、前記エンコーダと前記デコーダとを使用して実施され、
前記入力の前記処理が、前記デコーダの少なくとも部分を使用して実施される、
請求項1に記載のコンピュータ実装方法。
【請求項4】
前記エンコーダが、セルフアテンション機構とフィードフォワードニューラルネットワークとを備え、
前記デコーダが、セルフアテンション機構と、クロスアテンション機構と、フィードフォワードニューラルネットワークとを備え、
前記データの前記処理が、前記エンコーダの前記セルフアテンション機構および前記フィードフォワードニューラルネットワークと、前記デコーダの前記セルフアテンション機構、前記クロスアテンション機構、および前記フィードフォワードニューラルネットワークとを使用して実施され、
前記入力の前記処理が、前記デコーダのいずれのクロスアテンション機構も使用せずに、前記デコーダの前記セルフアテンション機構と前記フィードフォワードニューラルネットワークとを使用して実施される、
請求項3に記載のコンピュータ実装方法。
【請求項5】
前記データの前記処理の結果として取得された、前記デコーダの複数の状態を記録または記憶することと、
前記デコーダの前記記録または記憶された複数の状態を適用して、前記入力の前記処理を促進することと
をさらに備える、請求項3に記載のコンピュータ実装方法。
【請求項6】
前記デコーダの前記複数の状態が、前記データを処理する結果として前記エンコーダによって取得された複数の音響特徴と、前記データを処理する結果として前記デコーダによって取得された複数のテキスト依存性とを表す、請求項5に記載のコンピュータ実装方法。
【請求項7】
前記1つまたは複数の意味論的ラベルの前記テキストに基づく表現が、各々が前記1つまたは複数の意味論的ラベルのうちのそれぞれの1つに関連する、1つまたは複数の質問を備える、請求項1に記載のコンピュータ実装方法。
【請求項8】
前記入力が、前記音声の前記内容に対応する前記テキストをさらに備える、請求項1に記載のコンピュータ実装方法。
【請求項9】
前記言語理解タスクが意図分類タスクを備え、
前記1つまたは複数の意味論的ラベルが、1つまたは複数の意図ラベルを備え、
前記抽出された意味論的情報が、抽出された意図情報を備える、
請求項1に記載のコンピュータ実装方法。
【請求項10】
前記抽出された意図情報が、それぞれの意図ラベルとのそれぞれの正の関連性または負の関連性を示す、請求項9に記載のコンピュータ実装方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本明細書で説明される実施形態は、発話言語理解のためのシステムおよび方法に関する。
続きを表示(約 2,500 文字)
【背景技術】
【0002】
発話言語理解は、音声処理および自然言語処理に密接に関係するコンピュータ実装技術である。たとえば、従来の人工知能における発話言語理解は、発話をユーザの意図、エンティティ、または感情など、意味論的要素(semantic elements)に変換することを目的とする。
【0003】
発話言語理解の1つのタイプは、新しい領域におけるトレーニングデータを使用して事前にトレーニングせずに、それらの新しい領域においてユーザの発話を理解するように構成されたゼロショット発話言語理解である。
【0004】
ゼロショット発話言語理解を実施するための既存のシステムは、一般に、モジュラーシステムまたはエンドツーエンドシステムである。モジュラーシステムは、一般に、音声をテキストに書き写す(transcribe)ように構成された音声認識モデルと、意味論的出力(semantic output)を作成するためにテキストを処理するように動作可能な別個の自然言語理解モデルとを含む。モジュラーシステムでは、2つのモデルは別個にトレーニングされる。エンドツーエンドシステムは、一般に、音声をテキストに書き写すように構成された音声認識モデルと、意味論的出力を作成するためにテキストを処理するように動作可能な自然言語理解モデルとを含む。エンドツーエンドシステムでは、2つのモデルは、接続され、一緒にトレーニングされ、音声入力は意味論的出力に直接マッピングされる。
【0005】
これらの既存のモジュラーシステムおよびエンドツーエンドシステムでは、ゼロショット発話言語理解を実施する際の音声認識モデルと自然言語理解モデルの両方の使用は、比較的大量の計算リソース(たとえば、処理リソース、メモリ消費など)を必要とし得る。
【0006】
次に、本発明の実施形態が、添付の図面を参照しながら、例として説明される。
【図面の簡単な説明】
【0007】
図1は、本発明の一実施形態における、発話言語理解を実施するための動作を例示するフローチャートである。
図2は、本発明の一実施形態における、発話言語理解を実施するための動作を例示する概略図である。
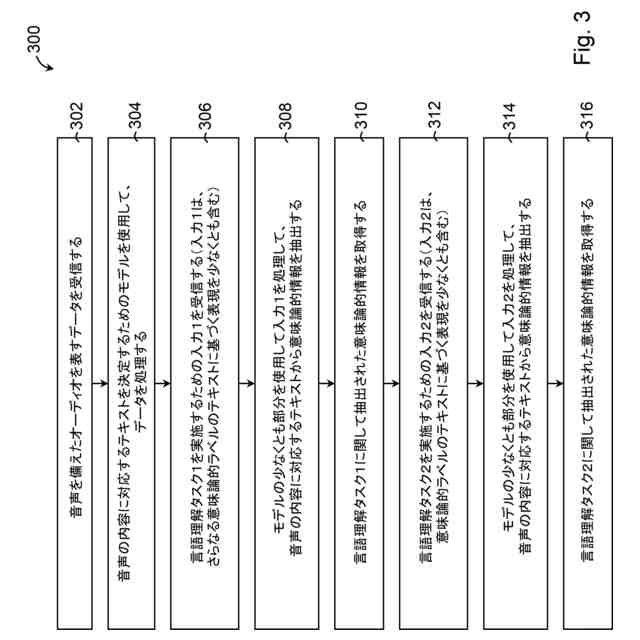
図3は、本発明の一実施形態における、発話言語理解を実施するための動作を例示するフローチャートである。
図4は、本発明の一実施形態における、発話言語理解を実施するための動作を例示するフローチャートである。
図5は、本発明の一実施形態における、音声認識を実施するための動作を例示する概略図である。
図6は、本発明の一実施形態における、言語理解を実施するための動作を例示する概略図である。
図7は、本発明の一実施形態における、音声認識を実施するための動作を例示する概略図である。
図8は、本発明の一実施形態における、意図分類を実施するための動作を例示する概略図である。
図9は、本発明の一実施形態における、スロットフィリングを実施するための動作を例示する概略図である。
図10Aは、本発明の一実施形態における、音声認識を実施するための動作を例示する概略図である。
図10Bは、本発明の一実施形態における、意図分類およびスロットフィリングを実施するための動作を例示する概略図である。
図11は、本発明の一実施形態における、意図ラベルおよびスロットラベル用の大規模言語モデルベースの質問生成プロセスのある例を例示する概略図である。
図12は、本発明のいくつかの実施形態における、動作を実施するように動作可能なある例示的な情報処理システムのブロック図である。
【発明を実施するための形態】
【0008】
本発明の実施形態は、ゼロショットエンドツーエンド発話言語理解などの発話言語理解に関する。
【0009】
ある実施形態では、発話言語理解を実施するためのコンピュータ実装方法が提供される。コンピュータ実装方法は、音声を備えたオーディオを表すデータを受信することと、音声の内容に対応するテキストを決定するためのモデルを使用してデータを処理することと、言語理解タスクを実施するための、1つまたは複数の意味論的ラベル(semantic label)のテキストに基づく表現を備えた入力を受信することと、モデルの少なくとも部分を使用して入力を処理して、音声の内容に対応するテキストから言語理解タスクのための意味論的情報(semantic information)を抽出することと、言語理解タスクのために抽出された意味論的情報を取得することとを備える。ここで、モデルは、データと入力の両方を処理するために使用され、すなわち、モデルの少なくとも部分は、(音声認識を実施するための1つのモデルと、言語理解を実施するための別の異なるモデルとを使用する代わりに)音声認識と言語理解の両方を実施するように構成される。モデルを使用した(音声認識のための)データの処理は、モデルの少なくとも部分を使用した(言語理解のための)入力の処理を促進すること、または導くことができる。場合によっては、(言語理解のための)入力の処理は、いずれの外部言語モデルの使用も必要としなくてよい。有利には、いくつかの実施形態では、このモデルは、よりパラメータ効率がよい(parameter-efficient)ことがあり、より効果的にトレーニングされることおよび/または動作することが可能である(たとえば、より少ないメモリリソースを消費する)。有利には、いくつかの実施形態では、言語理解タスク、またはより一般的に発話言語理解は、より効果的に実施され得る。
【0010】
いくつかの実施形態では、モデルはゼロショットエンドツーエンド発話言語理解を実施するように動作可能である。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
株式会社東芝
端子台
22日前
株式会社東芝
固定子
3か月前
株式会社東芝
モータ
1か月前
株式会社東芝
センサ
1か月前
株式会社東芝
センサ
1か月前
株式会社東芝
センサ
2か月前
株式会社東芝
除去装置
15日前
株式会社東芝
電子回路
1か月前
株式会社東芝
吸音装置
1か月前
株式会社東芝
電子装置
1か月前
株式会社東芝
金型構造
1か月前
株式会社東芝
電子装置
1か月前
株式会社東芝
真空バルブ
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
2か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
高周波回路
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
真空バルブ
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1日前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
2か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
株式会社東芝
半導体装置
1か月前
続きを見る
他の特許を見る






 特許ウォッチ
特許ウォッチ