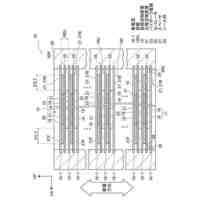
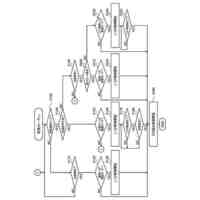
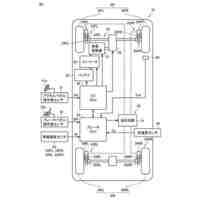
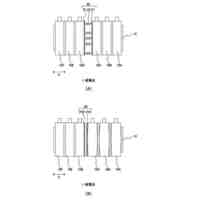
公開番号2025092455 公報種別公開特許公報(A) 公開日2025-06-19 出願番号2024209738 出願日2024-12-02 発明の名称コンピュータにより実施する方法、コンピュータプログラム、および記録媒体 出願人トヨタ自動車株式会社,テクニシェ ユニバーシタット ミュンヘン 代理人弁理士法人秀和特許事務所 主分類G06T 13/40 20110101AFI20250612BHJP(計算;計数) 要約【課題】アニメーション化された対象の制御可能なアバター生成における従来技術の短所を是正する。 【解決手段】コンピュータによって実施される方法は、アニメーション化された対象の制御可能なアバターを、そのアニメーション化された対象の少なくとも一組の画像セットから生成するための方法である。この方法は幾何学的プリミティブをアニメーション化された対象のパラメトリックでモーフィング可能なモデルと関連付けること、および少なくとも一組の画像セットに基づいて、関連付けられた幾何学的プリミティブのパラメータを学習すること、を含む。 【選択図】図1 特許請求の範囲【請求項1】 アニメーション化された対象の制御可能なアバターを、前記アニメーション化された対象の少なくとも一組の画像セットから生成するための、コンピュータによって実施される方法であって、 幾何学的プリミティブを前記アニメーション化された対象のパラメトリックでモーフィング可能なモデルと関連付けること、および 前記少なくとも一組の画像セットに基づいて、前記関連付けられた幾何学的プリミティブのパラメータを学習すること、を含む方法。 続きを表示(約 830 文字)【請求項2】 前記関連付けは、幾何学的プリミティブをモデルの諸点に結合されたローカル参照フレームのそれぞれに配置することを含み、この配置は前記パラメータの値によって定義される、請求項1に記載の方法。 【請求項3】 前記幾何学的プリミティブは離散的であり、前記モデルはメッシュを含み、前記関連付けは、各々の前記幾何学的プリミティブをメッシュの一つのセルに割り当てることを含み、幾何学的プリミティブをセルと共に動き変形することができるようにする、請求項1または2に記載の方法。 【請求項4】 前記学習において、前記幾何学的プリミティブのメッシュのセルへの割り当てを一定に維持する、請求項3に記載の方法。 【請求項5】 前記パラメータは、対応するセルのスケーリングに対する前記幾何学的プリミティブのスケーリング情報を含む、請求項3に記載の方法。 【請求項6】 前記学習は、前記モデルのグローバル参照フレームにおいて前記パラメータの値を更新することを含む、請求項1に記載の方法。 【請求項7】 前記幾何学的プリミティブは3Dガウシアンを含む、請求項1に記載の方法。 【請求項8】 前記幾何学的プリミティブの局所密度を調整することを含む、請求項1に記載の方法。 【請求項9】 前記調整は、第1の幾何学的プリミティブが既に割り当てられているローカル参照フレームに第2の幾何学的プリミティブを付加することを含み、任意選択で前記第2の幾何学的プリミティブは前記ローカル参照フレームに割り当てられる、請求項8に記載の方法。 【請求項10】 前記調整は幾何学的プリミティブを削除すること、および前記削除はセルの最後の一つの幾何学的プリミティブを除去しないように確認することを含む、請求項8または9に記載の方法。 (【請求項11】以降は省略されています) 発明の詳細な説明【技術分野】 【0001】 本開示は画像およびアニメーションからの再構築の分野に関わり、より詳細にはコンピュータによって実施する方法、コンピュータプログラム、および記録媒体に関わる。 続きを表示(約 3,600 文字)【背景技術】 【0002】 アニメーション化された対象アニメーション化された対象、例えば関節を有する物体、身体部分、あるいは人間や動物の頭部などの制御可能なアバターを作成することは、コンピュータビジョンおよびコンピュータグラフィックスにおける長年の課題である。特に、任意の視点から見たフォトリアリスティックな(写真のような現実感のある)動的アバターを生成することができれば、ゲーム、映画製作、イマーシブテレプレゼンス(没入型テレプレゼンス)、および拡張現実または仮想現実における多くの応用が可能となる。このような応用に際しては、アバターを制御できること、および新たな諸姿勢や諸表情を表せるようアバターを適切に普遍化することが肝要である。 【0003】 例えば人間の頭部などの対象の外見、形状および動きを一緒に捉えることの出来る3D表現を再構築することは忠実度の高いアバター生成における主要な課題となっている。この再構築問題はその性質上、過少制約的(under-constrained)であり、そのことが、新 規ビューレンダリング(novel view rendering:新たな視点における画像レンダリング)において、フォトリアリズムと姿勢や表情の可制御性とを結びつけた表現を達成する作業を非常に複雑なものとしている。更に人体頭部の場合には、極限的な表現や顔貌の細部、例えば皺や口の内部および髪といったものを捉えることが困難であり、目に付きやすい視覚的アーチファクトを生じさせてしまう可能性がある。他のタイプの対象においても、上記対象に準じて同様の問題がある。 【0004】 近年、全身アバター、頭部アバターの両者について、数多くの統計的メッシュモデルが開発されている(下記の非特許文献3および6)。これらのモデルは人の形状や動きを3Dスキャンから捉えるものである。これらモデルを動かす(アニメーション化する)ことは、アバターの姿勢、表情その他の諸態様を制御可能とするパラメータを操作することにより容易に実現することができる。しかしこれらのモデルだけではフォトリアリスティックなレンダリングを生成することはできない。なぜならこれらモデルは高周波数のディテイル(細部)に欠けており、且つたいていの場合、服の皺や髪の毛といった細かなディテイルを効果的にモデル化することができないからである。ニューラル・ラディアンス・フィールド(NeRF:Neural Radiance Field)およびその諸変種(非特許文献1)は多 視点から見た静的なシーン(場面)の再構築において素晴らしい成果を挙げている。その諸所産(成果物)は、NeRFを拡張し、任意のシナリオおよび人為的に作られたシナリオの両方に対応する動的なシーンをモデル化するに至っている。これら所産は新規ビューレンダリングにおいて素晴らしい成果を挙げている。しかし、これら所産は可制御性に欠けており、そのため新たな諸姿勢や諸表情を表すほど十分に普遍化されない。近年の3Dガウシアン・スプラッティング法(3D Gaussian splatting method)(非特許文献2)は、リアルタイムで実施する新規ビュー合成(novel-view synthesis)に関してはNeRFよりも高いレンダリング品質を実現している。この方法は離散的な幾何プリミティブ(3Dガウシアン)を3D空間全体に渡って最適化するものである。この方法は時間ステップ間で明示的な対応関係を構築することによって動的なシーンをキャプチャできるように発展してきてはいるが、再構築された出力をアニメーション化することはできていない。 【0005】 以下の文献は画像、アニメーション、人体モデルからの再構築の分野に関する様々な手 法を開示している。 Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99-106, 2021 Bernhard Kerbl, Georgios Kopanas, Thomas Leimkuhler, and George Drettakis. 3D Gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (ToG), 42(4):1-14, 2023 Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6):194:1-194:17, 2017 Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Niessner. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2387-2395, 2016 Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014 Matthew Loper and Naureen Mahmood and Javier Romero and Gerard Pons-Moll and Michael J. Black. SMPL: A Skinned Multi-Person Linear Model. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 34(6): 248:1---248:16, 2015 【発明の概要】 【発明が解決しようとする課題】 【0006】 本発明の目的は上記の短所を少なくとも実質的に是正することである。 【課題を解決するための手段】 【0007】 それに関連して、本開示は、アニメーション化された対象(アニメーション化された対象:animated subject)の制御可能なアバターを、そのアニメーション化された対象の少なくとも一組の画像セットから生成するための、コンピュータによって実施される方法であって、 複数の幾何学的プリミティブをアニメーション化された対象のパラメトリックでモーフィング可能なモデル(parametric morphable model)と関連付けること、および 前記少なくとも一組の画像セットに基づいて、関連付けられた複数の幾何学的プリミティブのパラメータを学習すること、を含む方法に関わる。 【0008】 以下において簡略化のために、この方法を生成方法と称する。 【0009】 本開示においては、特段の記載が無い場合、その数の明示なしに記載された事物(例えば画像セット)は「少なくとも一つの」あるいは「それぞれの」事物(画像セット)を意味するものであり、その事物が複数である場合も含むものとする。逆に複数であると記載された事物も単数である場合を含むものとする。 【0010】 アバターは対象の外見のデジタルな複製であってよい。「アバターが制御可能である」とは、後に詳しく説明するように、そのアバターの外見を変えるためにアバターのパラメータを変化させることができることを意味する。アバターは三次元アバターであってよい。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する
 特許ウォッチ
特許ウォッチ