TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2024148934
公報種別
公開特許公報(A)
公開日
2024-10-18
出願番号
2023062528
出願日
2023-04-07
発明の名称
学習方法、学習装置、及びプログラム
出願人
国立大学法人 東京大学
,
トヨタ自動車株式会社
代理人
個人
主分類
G06N
20/00 20190101AFI20241010BHJP(計算;計数)
要約
【課題】一部の学習データに真のラベルを付した学習データセットを用いて全ての学習データに真のラベルを付した学習データセットで機械学習した場合に近い性能の学習モデルを生成する。
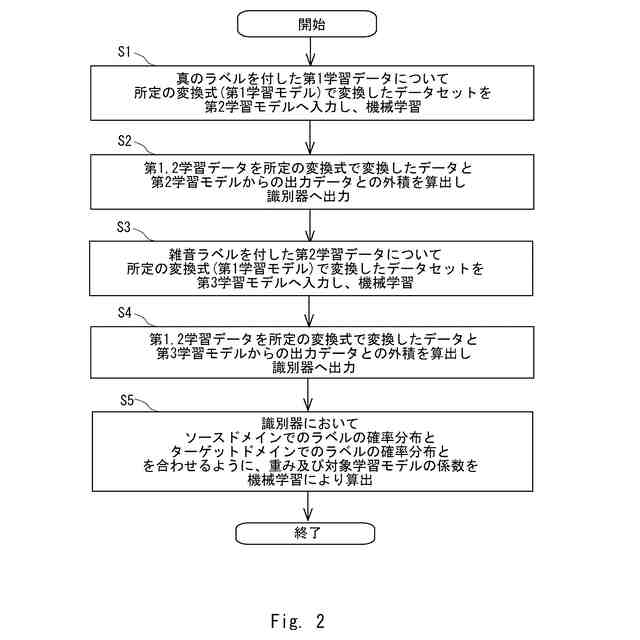
【解決手段】本開示に係る学習方法は、生成対象の学習モデルの係数を算出するために用意した、真のラベルを付した正解の学習データについてのデータセット、雑音ラベルを付した学習データについてのデータセットを、それぞれソースドメイン、ターゲットドメインとして入力する。学習方法は、ソースドメインのデータセットとターゲットドメインのデータセットとが同じラベルについて所定の変換式を用いて同じ値となることを条件として、ソースドメイン及びターゲットドメインのデータセットを用いて、各ラベルについての、ソースドメインのデータセットとターゲットドメインのデータセットとの比である重みと、生成対象の学習モデルの係数とを、機械学習により算出する。
【選択図】図1
特許請求の範囲
【請求項1】
生成対象の学習モデルの係数を算出するために用意した、真のラベルを付した正解の学習データについてのデータセットを、ソースドメインとして入力し、
前記生成対象の学習モデルの係数を算出するために用意した、雑音ラベルを付した学習データについてのデータセットを、ターゲットドメインとして入力し、
前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとが、同じラベルについて所定の変換式を用いて同じ値となることを条件として、前記ソースドメインのデータセット及び前記ターゲットドメインのデータセットを用いて、各ラベルについての、前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとの比である重みと、前記生成対象の学習モデルの係数とを、機械学習により算出する、
学習方法。
続きを表示(約 1,700 文字)
【請求項2】
γをγ∈[0,1]を満たすハイパーパラメータ、T
jk
を前記ソースドメインでの(j,k)成分のタスク、
~
T
jk
を前記ターゲットドメインでの(j,k)成分のタスク、P
S
を前記ソースドメインでの真のラベルの確率分布、P
T
を前記ターゲットドメインでの雑音ラベルの確率分布、gを前記所定の変換式としての、前記ソースドメイン及び前記ターゲットドメインに共通の学習モデルを表現する関数、hを前記ソースドメインについての学習モデルを表現する関数、lを前記ターゲットドメインについての学習モデルを表現する関数、前記重みの(j,k)成分を下式のw
jk
とし、確率分布P
S
と確率分布P
T
とを合わせるように、前記重みと前記生成対象の学習モデルの係数とを、機械学習により算出する、
w
jk
=(1-γ){T
jk
-1
P
T
(h(g(X)))}+γ{
~
T
jk
-1
P
T
(
~
Y)}
ここで、
~
T
jk
=P
S
(l(g(X))=j,Y=k)
請求項1に記載の学習方法。
【請求項3】
生成対象の学習モデルの係数を算出するために用意した、真のラベルを付した正解の学習データについてのデータセットを、ソースドメインとして入力し、前記生成対象の学習モデルの係数を算出するために用意した、雑音ラベルを付した学習データについてのデータセットを、ターゲットドメインとして入力する入力部と、
前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとが、同じラベルについて所定の変換式を用いて同じ値となることを条件として、前記ソースドメインのデータセット及び前記ターゲットドメインのデータセットを用いて、各ラベルについての、前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとの比である重みと、前記生成対象の学習モデルの係数とを、機械学習により算出する算出部と、
を備えた学習装置。
【請求項4】
前記算出部は、γをγ∈[0,1]を満たすハイパーパラメータ、T
jk
を前記ソースドメインでの(j,k)成分のタスク、
~
T
jk
を前記ターゲットドメインでの(j,k)成分のタスク、P
S
を前記ソースドメインでの真のラベルの確率分布、P
T
を前記ターゲットドメインでの雑音ラベルの確率分布、gを前記所定の変換式としての、前記ソースドメイン及び前記ターゲットドメインに共通の学習モデルを表現する関数、hを前記ソースドメインについての学習モデルを表現する関数、lを前記ターゲットドメインについての学習モデルを表現する関数、前記重みの(j,k)成分を下式のw
jk
とし、確率分布P
S
と確率分布P
T
とを合わせるように、前記重みと前記生成対象の学習モデルの係数とを、機械学習により算出する、
w
jk
=(1-γ){T
jk
-1
P
T
(h(g(X)))}+γ{
~
T
jk
-1
P
T
(
~
Y)}
ここで、
~
T
jk
=P
S
(l(g(X))=j,Y=k)
請求項3に記載の学習装置。
【請求項5】
コンピュータに、請求項1又は2に記載の学習方法を実行させるためのプログラム。
発明の詳細な説明
【技術分野】
【0001】
本開示は、学習方法、学習装置、及びプログラムに関する。
続きを表示(約 2,100 文字)
【背景技術】
【0002】
学習モデルは、教師データにラベルを付与して生成することができる。しかしながら、ラベル付きのデータの収集には時間を要する。そこで、少数のラベル付きデータを用いて、ラベルを生成することも多い。この問題を解決するための技術の一つとして、教師なしドメイン適応(Unsupervised Domain Adaptation; UDA)がある。非特許文献1には、教師なしドメイン適応についての技術が記載されている。
【先行技術文献】
【非特許文献】
【0003】
Tachet des Combes, R., Zhao, H., Wang, Y. X., & Gordon, G. J.、“Domain adaptation with conditional distribution matching and generalized label shift”、34th Conference on Neural Information Processing Systems (NeurIPS 2020)、2020年
【発明の概要】
【発明が解決しようとする課題】
【0004】
教師なしドメイン適応では、学習データの重みが重要となるが、非特許文献1に記載の技術では重みが判定結果に依存した推論で算出されており、真の値に収束しない可能性がある。よって、一部の学習データに真のラベルを付した学習データセットを用いて全ての学習データに真のラベルを付した学習データセットで機械学習した場合に近い性能の学習モデルを生成する技術の開発が望まれる。
【0005】
本開示は、このような問題を解決するためになされたもので、その目的は、一部の学習データに真のラベルを付した学習データセットを用いて全ての学習データに真のラベルを付した学習データセットで機械学習した場合に近い性能の学習モデルを生成することが可能な学習方法、学習装置、及びプログラムを提供することにある。
【課題を解決するための手段】
【0006】
本開示に係る学習方法は、生成対象の学習モデルの係数を算出するために用意した、真のラベルを付した正解の学習データについてのデータセットを、ソースドメインとして入力し、前記生成対象の学習モデルの係数を算出するために用意した、雑音ラベルを付した学習データについてのデータセットを、ターゲットドメインとして入力し、前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとが、同じラベルについて所定の変換式を用いて同じ値となることを条件として、前記ソースドメインのデータセット及び前記ターゲットドメインのデータセットを用いて、各ラベルについての、前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとの比である重みと、前記生成対象の学習モデルの係数とを、機械学習により算出する、ものである。
【0007】
本開示に係る学習装置は、生成対象の学習モデルの係数を算出するために用意した、真のラベルを付した正解の学習データについてのデータセットを、ソースドメインとして入力し、前記生成対象の学習モデルの係数を算出するために用意した、雑音ラベルを付した学習データについてのデータセットを、ターゲットドメインとして入力する入力部と、前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとが、同じラベルについて所定の変換式を用いて同じ値となることを条件として、前記ソースドメインのデータセット及び前記ターゲットドメインのデータセットを用いて、各ラベルについての、前記ソースドメインのデータセットと前記ターゲットドメインのデータセットとの比である重みと、前記生成対象の学習モデルの係数とを、機械学習により算出する算出部と、を備えたものである。
【0008】
本開示に係るプログラムは、コンピュータに、前記学習方法を実行させるためのプログラムである。
【発明の効果】
【0009】
本開示により、一部の学習データに真のラベルを付した学習データセットを用いて全ての学習データに真のラベルを付した学習データセットで機械学習した場合に近い性能の学習モデルを生成することが可能な学習方法、学習装置、及びプログラムを提供することができる。
【図面の簡単な説明】
【0010】
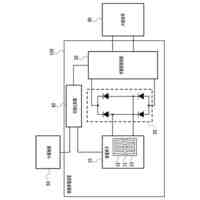
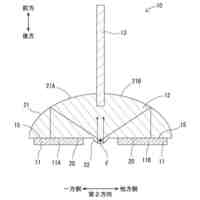
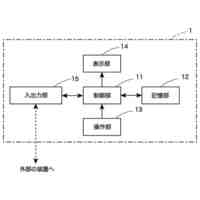
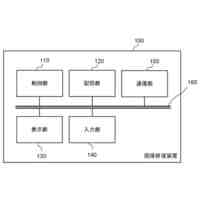
実施の形態に係る学習装置の一構成例を示すブロック図である。
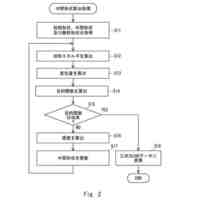
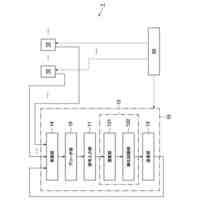
図1の学習装置で実施される学習方法の一例を説明するためのフロー図である。
実施の形態に係る学習方法のアルゴリズムの一例を示す図である。
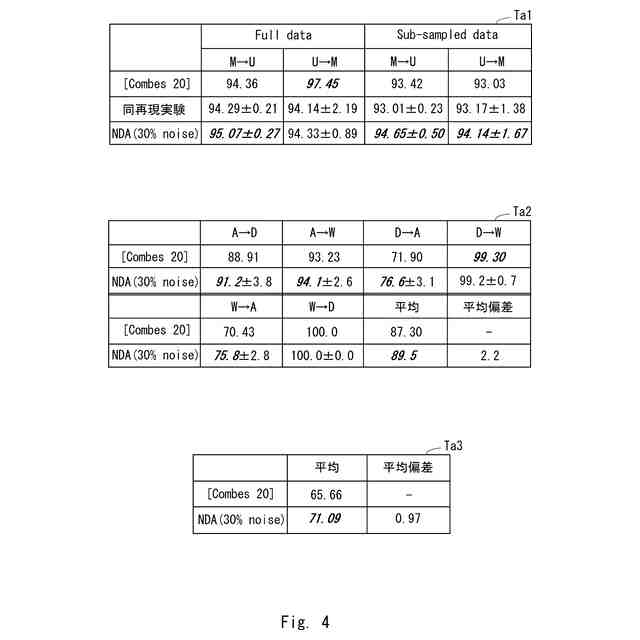
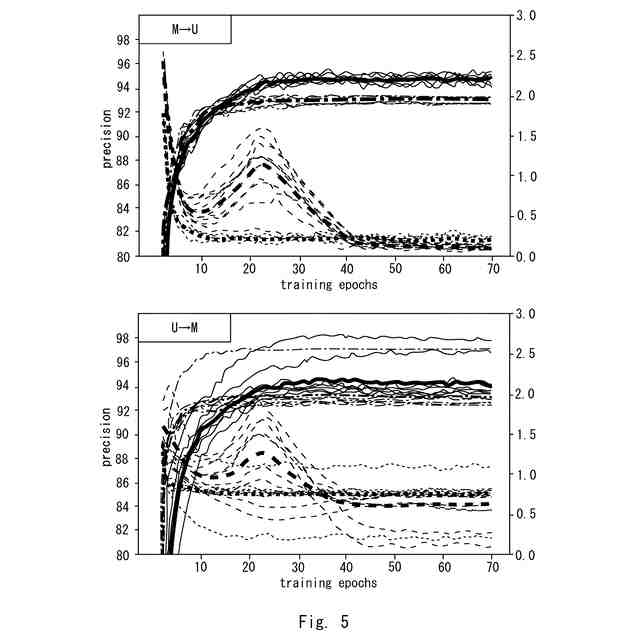
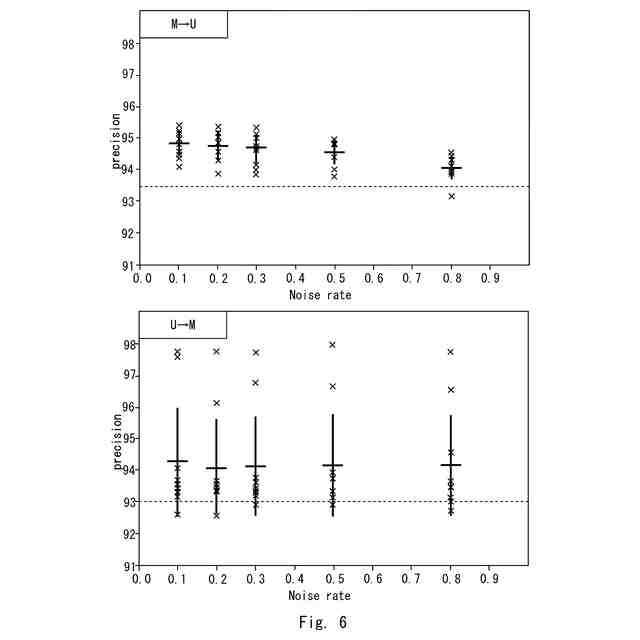
図3のアルゴリズムでの実験結果と比較例に係るアルゴリズムでの実験結果を示す図である。
図3のアルゴリズムでの実験結果を示す図である。
図3のアルゴリズムでの実験結果を示す図である。
【発明を実施するための形態】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
国立大学法人 東京大学
熱交換器
3か月前
国立大学法人 東京大学
センサ装置
2か月前
国立大学法人 東京大学
振動発電装置
2か月前
国立大学法人 東京大学
情報処理装置
18日前
国立大学法人 東京大学
内視鏡補助装置
2か月前
国立大学法人 東京大学
ロボットアーム
5日前
国立大学法人 東京大学
生産性判定装置
2か月前
国立大学法人 東京大学
化合物半導体チップ
4日前
国立大学法人 東京大学
アシルヒドラゾン誘導体
18日前
国立大学法人 東京大学
タンパク質シンチレーター
1か月前
個人
ウイルス増殖抑制剤
1か月前
国立大学法人 東京大学
繊維シート及びその製造方法
2か月前
国立大学法人 東京大学
高速3次元撮影装置及び方法
3か月前
国立大学法人 東京大学
測定装置及び情報処理システム
1か月前
国立大学法人 東京大学
測定装置及び情報処理システム
1か月前
国立大学法人 東京大学
掌蹠膿疱症の治療用医薬組成物
3か月前
国立大学法人 東京大学
試料測定装置及び試料測定方法
8日前
国立大学法人 東京大学
膵炎モデル動物及びその製造方法
1か月前
国立大学法人 東京大学
人工培養皮膚およびその製造方法
2か月前
ダイキン工業株式会社
金属錯体
4日前
株式会社豊田中央研究所
可折構造物
1か月前
国立大学法人 東京大学
放射性物質アスタチン-211除去材
2か月前
国立大学法人 東京大学
ジルコニア焼結体およびその製造方法
2か月前
国立大学法人 東京大学
酵素の検出方法及び酵素の検出キット
2か月前
ダイキン工業株式会社
薄膜の製造方法
4日前
日本特殊陶業株式会社
超音波発生装置
3か月前
株式会社京三製作所
信号制御システム
1か月前
ダイキン工業株式会社
薄膜の製造方法
4日前
国立大学法人 東京大学
中間形状算出装置及び中間形状算出方法
2か月前
国立大学法人 東京大学
触覚提示デバイス及び触覚提示システム
2か月前
国立大学法人 東京大学
CO2吸着システムおよびCO2吸着方法
1か月前
国立大学法人 東京大学
情報処理装置、制御装置、及びプログラム
25日前
国立大学法人 東京大学
プログラム、画像修復装置及び画像修復方法
3か月前
国立大学法人 東京大学
情報処理装置、及び情報処理装置の制御方法
1か月前
国立大学法人 東京大学
SiCウェハのダイシング方法及びその装置
18日前
三洋化成工業株式会社
熱化学電池用電解液
18日前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ