TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2024109471
公報種別
公開特許公報(A)
公開日
2024-08-14
出願番号
2023014281
出願日
2023-02-01
発明の名称
人物検索装置及びプログラム
出願人
日本放送協会
代理人
個人
主分類
G06F
16/332 20190101AFI20240806BHJP(計算;計数)
要約
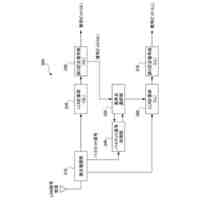
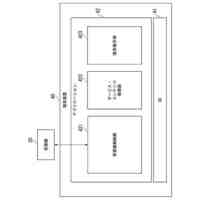
【課題】人物情報を収集し、その人物情報から所望の人名を検索する際に、人物情報の収集が一層容易となり、かつユーザにとって使い勝手の良い検索を実現する。
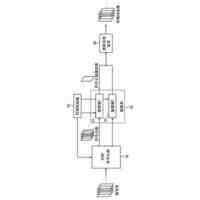
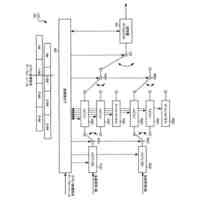
【解決手段】人物検索装置1のテキスト人名抽出手段21は、ドキュメントを入力し、ドキュメントからテキストを抽出し、固有表現抽出技術を用いて人名を抽出し、テキスト特徴抽出手段22は、事前学習済みのBERTモデルを用いて、テキストの特徴量ベクトルC1を抽出し、登録手段23は、人名及び特徴量ベクトルC1を組としてデータベースに登録する。テキスト特徴抽出手段24は、検索クエリーを入力し、事前学習済みBERTモデルを用いて、検索クエリーの特徴量ベクトルC2を抽出する。検索手段25は、データベースの特徴量ベクトルC1と検索クエリーの特徴量ベクトルC2との間のコサイン類似度を算出し、最も高いコサイン類似度に対応する人名を特定する。
【選択図】図1
特許請求の範囲
【請求項1】
ユーザの操作により検索クエリーを入力し、当該検索クエリーに関連する人名を検索する人物検索装置において、
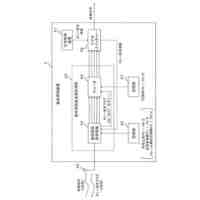
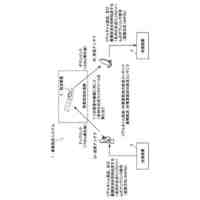
ドキュメントを入力し、当該ドキュメントからテキストを抽出し、固有表現抽出技術を用いて、当該テキストから人名を抽出するテキスト人名抽出手段と、
前記テキスト人名抽出手段により抽出された前記テキストを複数のトークンに分割し、前記複数のトークンの先頭に先頭トークンを付加し、トークン毎に分散表現ベクトルを生成することで、ベクトル列V1を生成し、
事前学習されたBERTモデルを用いて、前記ベクトル列V1を入力データとしたときのベクトル列V2を出力データとして推定し、
前記ベクトル列V2に基づいて、前記テキストの特徴量ベクトルC1を抽出する第1のテキスト特徴抽出手段と、
前記テキスト人名抽出手段により抽出された前記人名、及び前記第1のテキスト特徴抽出手段により抽出された前記テキストの特徴量ベクトルC1を組として、複数の組のデータをデータベースに登録する登録手段と、
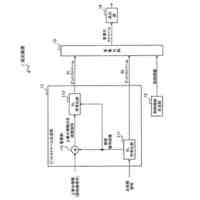
前記ユーザの操作に従い、テキストからなる前記検索クエリーを入力し、前記検索クエリーを複数のトークンに分割し、前記複数のトークンの先頭に先頭トークンを付加し、トークン毎に分散表現ベクトルを生成することで、ベクトル列V3を生成し、
前記BERTモデルを用いて、前記ベクトル列V3を入力データとしたときのベクトル列V4を出力データとして推定し、
前記ベクトル列V4に基づいて、前記検索クエリーの特徴量ベクトルC2を抽出する第2のテキスト特徴抽出手段と、
前記データベースに登録された前記複数の組のデータのそれぞれを読み出し、前記複数の組のデータのそれぞれについて、当該組のデータにおける前記テキストの特徴量ベクトルC1と、前記第2のテキスト特徴抽出手段により抽出された前記検索クエリーの特徴量ベクトルC2との間の類似度を算出し、最も高い前記類似度の前記特徴量ベクトルC1に対応する前記人名を特定する検索手段と、
を備えたことを特徴とする人物検索装置。
続きを表示(約 1,000 文字)
【請求項2】
請求項1に記載の人物検索装置において、
前記第2のテキスト特徴抽出手段により前記ユーザの操作に従い入力される前記検索クエリーを、文章のテキストとする、ことを特徴とする人物検索装置。
【請求項3】
ユーザの操作により検索クエリーを入力し、当該検索クエリーに関連する人名を検索する人物検索装置を構成するコンピュータを、
ドキュメントを入力し、当該ドキュメントからテキストを抽出し、固有表現抽出技術を用いて、当該テキストから人名を抽出するテキスト人名抽出手段、
前記テキスト人名抽出手段により抽出された前記テキストを複数のトークンに分割し、前記複数のトークンの先頭に先頭トークンを付加し、トークン毎に分散表現ベクトルを生成することで、ベクトル列V1を生成し、
事前学習されたBERTモデルを用いて、前記ベクトル列V1を入力データとしたときのベクトル列V2を出力データとして推定し、
前記ベクトル列V2に基づいて、前記テキストの特徴量ベクトルC1を抽出する第1のテキスト特徴抽出手段、
前記テキスト人名抽出手段により抽出された前記人名、及び前記第1のテキスト特徴抽出手段により抽出された前記テキストの特徴量ベクトルC1を組として、複数の組のデータをデータベースに登録する登録手段、
前記ユーザの操作に従い、テキストからなる前記検索クエリーを入力し、前記検索クエリーを複数のトークンに分割し、前記複数のトークンの先頭に先頭トークンを付加し、トークン毎に分散表現ベクトルを生成することで、ベクトル列V3を生成し、
前記BERTモデルを用いて、前記ベクトル列V3を入力データとしたときのベクトル列V4を出力データとして推定し、
前記ベクトル列V4に基づいて、前記検索クエリーの特徴量ベクトルC2を抽出する第2のテキスト特徴抽出手段、及び、
前記データベースに登録された前記複数の組のデータのそれぞれを読み出し、前記複数の組のデータのそれぞれについて、当該組のデータにおける前記テキストの特徴量ベクトルC1と、前記第2のテキスト特徴抽出手段により抽出された前記検索クエリーの特徴量ベクトルC2との間の類似度を算出し、最も高い前記類似度の前記特徴量ベクトルC1に対応する前記人名を特定する検索手段として機能させるためのプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、固有表現抽出技術及び学習モデルを用いて人物の名前を検索する人物検索装置に関する。
続きを表示(約 1,700 文字)
【背景技術】
【0002】
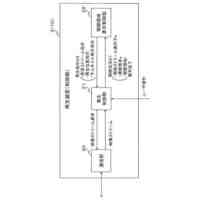
従来、例えば会社内でプロジェクトを立ち上げるときの人員を選定したり、業務を遂行するときの手助けとなる人員を選定したりするために、人物検索装置が使用されることがある。この人物検索装置は、人物情報を収集し、多様な業務経験、スキル等を有する人物の中から、目的に適した人物を検索する装置である。
【0003】
このような人物検索装置として、情報の機密性の低下を抑制し、人物情報及び文書情報の共有化を促進する装置が提案されている(例えば特許文献1を参照)。この人物検索装置は、人物の名前(人名)、専門分野、所属、連絡先等からなる人物情報が格納された第1記憶部、ユーザの権限及び人物情報の開示範囲の情報が格納された第2記憶部を備え、ユーザ操作に従って文字列を入力すると、第1記憶部から当該文字列に対応する人物情報を読み出し、第2記憶部に格納された情報に基づき、ユーザの権限に応じた表示対象の人物情報の範囲を決定し、その範囲に応じて一部を伏せて人物情報を画面表示するものである。
【0004】
また、この人物検索装置は、文書が格納された第3記憶部を備え、第3記憶部から文書を読み出し、文書から人名を抽出すると共に、技術用語、機器等の名称等の用語を抽出し、用語に重みを付与し、人名、用語及び重みからなる人物情報を生成して第1記憶部に格納する。
【0005】
一方で、例えば文書から人名、用語等を抽出するための固有表現抽出技術が知られている(例えば非特許文献1を参照)。この固有表現抽出技術は、文書から固有表現を抽出し、これを人名、組織名、地名等の固有名詞、日付、時間、数量、金額、パーセンテージ等の予め定義された固有表現分類へと分類する手法である。
【0006】
また、自然言語処理技術の一つとして、BERT(Bidirectional Encoder Representations from Transformers)が知られている。このBERTにはTransformer Encoderの構造が組み込まれており、文章を文頭及び文末の双方向から学習することにより、文脈を反映した文章の特徴量ベクトルを得ることができる(例えば非特許文献2を参照)。
【先行技術文献】
【特許文献】
【0007】
特開2019-168738号公報
【非特許文献】
【0008】
松田寛、外4名、“UD Japanese GSDの再整備と固有表現情報付与”、[online]、2020年3月、言語処理学会、[令和4年12月23日検索]、インターネット<URL:https://anlp.jp/proceedings/annual_meeting/2020/pdf_dir/P1-34.pdf>
“cl-tohoku/bert-base-japanese”、[online]、東北大学乾研究室、[令和4年12月23日検索]、インターネット<URL:https://huggingface.co/cl-tohoku/bert-base-japanese>
【発明の概要】
【発明が解決しようとする課題】
【0009】
一般に、人物情報が格納された記憶部から人名を検索するためには、予め人物情報を収集して記憶部に格納しておき、ユーザ操作により入力された検索クエリーに対応する人名を、当該記憶部から抽出する技術が必要となる。
【0010】
前述の特許文献1の人物検索装置では、ユーザ操作により入力されたキーワード(単語、例えば「冬季」「凍結」(特許文献1の図5~図7を参照))に対応する人物情報を、記憶部から読み出す処理を行う。しかし、記憶部には、予め人名、専門分野、所属、連絡先等からなる基本的な人物情報を格納しておく必要がある。このような基本的な人物情報の格納作業は、ユーザ操作等によるのが一般的であるため、手間がかかるという問題があった。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
日本放送協会
撮像装置
11か月前
日本放送協会
撮像装置
10か月前
日本放送協会
撮像装置
3か月前
日本放送協会
液晶表示装置
8か月前
日本放送協会
光学計測装置
1か月前
日本放送協会
マイクロホン
1か月前
日本放送協会
無線通信装置
22日前
日本放送協会
光制御デバイス
8か月前
日本放送協会
カメラ正対治具
12か月前
日本放送協会
磁性細線デバイス
3か月前
日本放送協会
有機光電変換素子
9か月前
日本放送協会
情報提示システム
10か月前
日本放送協会
レンズアダプター
5か月前
日本放送協会
360度撮影装置
10か月前
日本放送協会
無線伝送システム
2か月前
日本放送協会
データ管理システム
2か月前
日本放送協会
LDM送信システム
10か月前
日本放送協会
垂直分離型撮像素子
7か月前
日本放送協会
衛星放送受信システム
5か月前
日本放送協会
撮像装置及び撮像方法
10か月前
日本放送協会
送信装置及び受信装置
2か月前
日本放送協会
送信装置及び受信装置
8か月前
日本放送協会
送信装置及び受信装置
2か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
11か月前
日本放送協会
受信装置及び送出装置
4か月前
日本放送協会
同軸切替器の着脱機構
6か月前
日本放送協会
撮像素子及び撮像装置
8か月前
日本放送協会
送信装置及び受信装置
3か月前
日本放送協会
送信装置及び受信装置
8か月前
日本放送協会
送出装置及び受信装置
8か月前
日本放送協会
送信装置及び受信装置
11か月前
日本放送協会
送信装置及び受信装置
11か月前
日本放送協会
再生装置及びプログラム
6か月前
日本放送協会
端末装置及びプログラム
4か月前
続きを見る
他の特許を見る








 特許ウォッチ
特許ウォッチ