TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025174770
公報種別
公開特許公報(A)
公開日
2025-11-28
出願番号
2024091019
出願日
2024-05-17
発明の名称
生成シーケンスの文節区間分割による応答テキスト生成と音声合成の並列実行パイプラインによる高速音声対話システム
出願人
ThinkX株式会社
代理人
主分類
G10L
15/28 20130101AFI20251120BHJP(楽器;音響)
要約
【課題】音声認識モデル、音声合成モデルおよび言語モデルを含む機械学習モデルを用い、文構造の複雑なテキストほどパイプラインの並列性が向上し、全体のスループットが改善され、ユーザーが音声信号を知覚するまでにかかる応答時間が短縮される音声対話システムを提供する。
【解決手段】音声対話システムでは、音声認識モデル、音声合成モデル、および言語モデルを含む機械学習モデルを用い言語モデルによるテキスト生成部が逐次的に生成するトークンを監視するテキスト処理部が、文節マーカーを検出するやそのマーカーの内容に応じて生成テキストをマーカーの直前または直後で分割し、応答テキスト全体または一文の生成終了を待たずに音声合成の実行を開始し、文中の残りのテキスト生成と音声合成処理を並列実行する。
【選択図】図1
特許請求の範囲
【請求項1】
計算機端末上で動作する音声対話システムにおいて、
音声入力部、音声入力バッファ、音声認識部、言語モデルによるテキスト生成部、テキスト処理部、音声合成部、音声出力部の各部を有し、
前記音声入力部から入力された音声は前記音声入力バッファに蓄積されたのち前記音声認識部でテキストに変換され、その入力テキストへの応答テキストを前記テキスト生成部が出力トークンとして逐次的に生成し、テキスト処理部は生成された内容の解析や編集を行ったのち前記音声合成部に転送し、前記音声合成部はテキスト処理部から転送された応答テキストを音声信号に変換し、音声出力部に転送した後、音声出力部は音声信号を物理的音波として出力する音声対話システムについて、
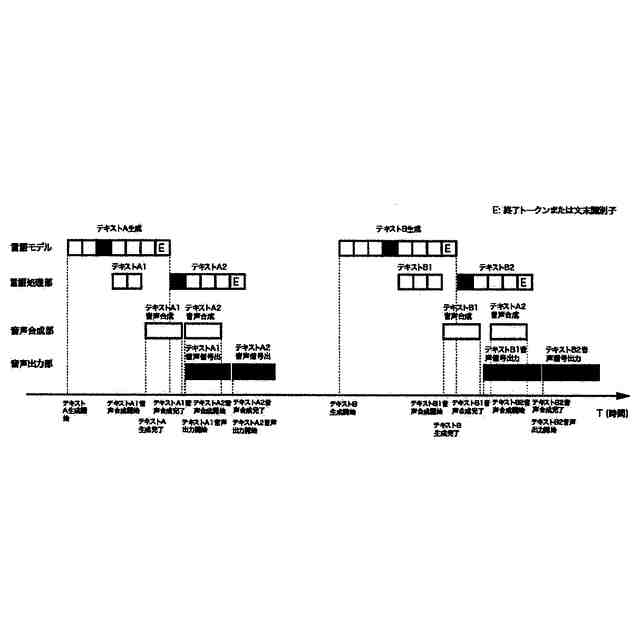
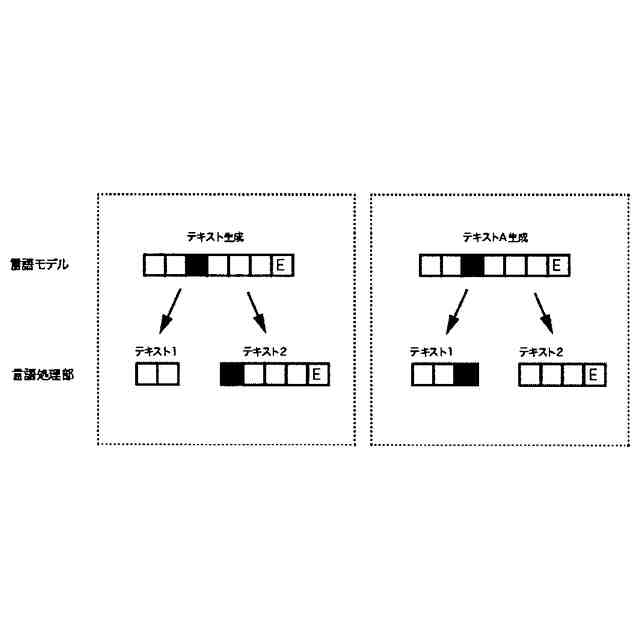
前記テキスト処理部は前記テキスト生成部が逐次的に出力トークンとして生成する応答テキストシーケンスから文節の区切りとなるマーカーを生成ごとに検出し、マーカーが検出されるやマーカーの語または形態素に応じてマーカーの直前または直後の位置でシーケンスを分割した後、分割された要素のうち時系列が前の要素から前記音声合成部に転送、テキスト生成部が一文の全体を生成し終える前に音声合成処理が開始されることで、
テキスト生成部の文全体の生成完了を待つことなく応答テキスト生成と音声信号生成を並列実行し、全体のパイプラインを短縮、スループットを向上し、自然な音声出力を維持しながら応答速度を高速化すること、
を特徴とする音声対話システム。
続きを表示(約 190 文字)
【請求項2】
請求項1に記載の音声対話システムにより、
請求項1に記載の音声入力部、音声入力バッファ、音声出力部をWebブラウザ上で動作する計算機プログラムで実行し、請求項1に記載のその他の各部を、Webブラウザの動作するプロセスと通信可能でかつ異なる計算機端末またはプロセス上で実行することで、Webブラウザでも高速な応答を可能にする音声対話システム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識モデル、音声合成モデル、および言語モデルを含む機械学習モデルを用いた音声対話システムに関する。
続きを表示(約 5,000 文字)
【背景技術】
【0002】
音声対話システムの応答速度を改善する方法がこれまで様々に検討されてきた。音声認識の精度、応答内容の品質、合成音声の品質、を最大限に向上させつつ、より人間らしい反応時間を実現するために応答までのレイテンシーを短縮することが動機である。一般に、人間の知覚では発話終了から相手の応答が到達するまでにかかる時間が1秒を越える場合、人間と話していると感じ難く、ストレスを感じる。
【0003】
応答内容の品質と応答内容の出力にかかる計算時間は一般にトレードオフであった。大規模言語モデルが実用化される以前は主に応答内容は膨大な返答内容辞書データベースと入力テキスト間の機械学習モデルによるパターンマッチングで実現されていた。例えば、返答として想定される膨大な応答文をデータベースに格納しておき、特徴ベクトルに変換された入力テキストを入力値に取り、最も尤度の高い応答文のインデックスを出力する機械学習モデルが用いられた。
非特許文献1では、検索に基づく応答選択タスクを用い事前学習を行い、効率良く高速に応答文を選択するための機械学習エンコーダーであり、応答文データベースの存在を前提としている。
一方で、膨大なテキストシーケンスを事前学習させた大規模言語モデルの実用化により、応答文データベースがなくてもモデルが適切な応答を生成できるようになった。大規模言語モデルは一回の推論ステップで一つのトークンを生成する。この推論ステップはコンピューターアーキテクチャーにおけるクロックサイクルに相当する。一つのトークンは概ね一つの単語またはサブワードに相当する。または生成完了を表す終了トークンなどの特別なトークンも出力される。
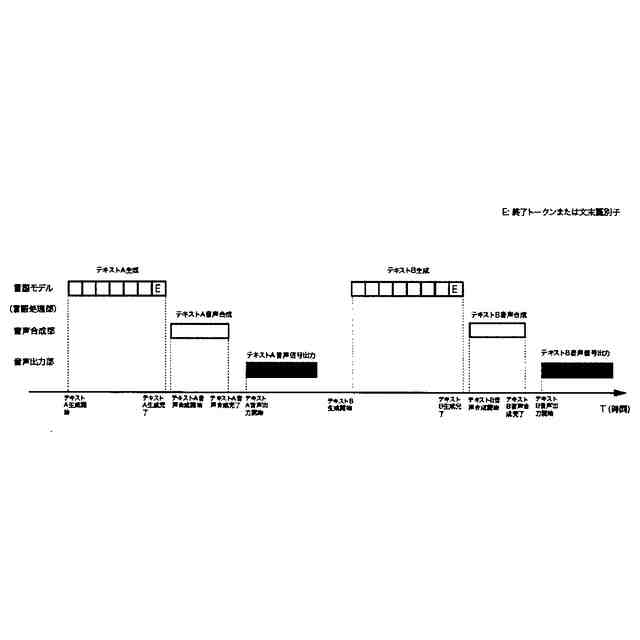
音声対話システムのパイプラインに言語モデルが組み込まれる場合、最も単純にはクロックサイクルが終了トークンに達するまで生成処理を実行し、終了トークンの検出をキーにして次のパイプラインに生成テキストを転送する。この場合、応答テキスト生成から音声合成までの処理は直線的であり、計算機アーキテクチャーにおいて単一の実行ユニットを持つスカラープロセッサに等しい。この設計では応答内容の生成完了までのレイテンシが長く速度制約となると同時に、特に複数のGPUプロセスをはじめとする計算資源の実行待ち状態を作る。または文末の句点またはピリオドの検出をキーにして音声合成パイプラインに転送する設計もある。その場合も、一文が長い場合には言語モデルのクロックサイクルが1000トークン/秒の生成速度であっても20トークンを生成するまでに0.2秒要し、その他のパイプラインにかかるレイテンシーを合計すると1.0秒を容易に超えてしまう。
この問題を抜本的に解決するために、テキスト生成言語モデルと音声合成モデルを統合し単一のモデルとして学習する方法が考えられている。その場合には大幅なレイテンシーの削減が可能になるが、一方でモジュールごとの独立性を失う。
非特許文献2では、音声と補助テキストを入力値に取りテキスト生成部を介さずそのまま応答音声を出力することのできる生成モデルが提案される。テキスト生成部と音声合成部が一体化されることで、応答文生成から音声合成までに要するレイテンシを省略することができるが、前述の通りモジュールの独立性がなく、カスタマイズ性が低いアーキテクチャー上の欠点をもつ。
【先行技術文献】
【非特許文献】
【0004】
「Matthew Henderson,Inigo Casanueva,Nikola Mrksic,Pei-Hao Su,Tsung-Hsien Wen,and Ivan Vulic.2020.ConveRT:Efficient and Accurate Conversational Representations from Transformers.In Findings of the Association for Computational Linguistics:EMNLP 2020,pages 2161-2174,Online.Association for Computational Linguistics.」
「Le,Matthew,et al.“Voicebox:Text-guided multilingual universal speech generation at scale.”Advances in neural information processing systems 36(2024).」
【発明の概要】
【発明が解決しようとする課題】
【0005】
大規模言語モデルを応答内容生成に用いる音声対話システムは、既存の応答選択タスクベース等の対話システムに比べてより柔軟で人間に近い判断と多様な推論を可能にするが、既存の音声対話システムパイプラインとは異なるアーキテクチャが必要とされ、発展途上であった。特に応答速度において、例えば応答選択タスクベースの対話システムは応答文を一度の推論実行で決定できるのに対し、大規模言語モデルはトークン単位で推論を行うため、応答内容の決定開始から終了までの間に、1文を構成する平均30~40単語程度を生成する逐次処理サイクルによる遅延が発生する。一方で、人間同士の音声対話の応答速度は通常1秒未満であることから、快適な音声対話体験には1秒未満にまで遅延を削減することが必須であり、計算資源の高性能化だけでなくシステムアーキテクチャ上の工夫を必要とする一方で、確立された方法論は存在していない。
【課題を解決するための手段】
【0006】
本発明の計算機端末上で動作する音声対話システムは、
音声入力部、音声入力バッファ、音声認識部、言語モデルによるテキスト生成部、テキスト処理部、音声合成部、音声出力部、からなる一連の処理のうち、テキスト生成部から音声合成部までのパイプラインを高度に並列化することでスループットを向上させる。テキスト生成部が逐次的に出力するトークンから文節の区切りをマーカーとして検出し、生成テキストをそのマーカーの内容に応じてマーカーの直前または直後で分割、一文が生成し終わらないうちに音声合成部に転送、音声合成処理を開始することで実行待ちの計算資源を減らし、並列性を向上させる。これにより自然な音声合成品質を維持しながら、ユーザーに最初の音声信号が到達するまでの時間を短縮、発話応答の遅延を低減し高速化する。
【発明の効果】
【0007】
本発明では、機械学習モデルを主に用いる音声対話システムの遅延を構成する主要な要因である、音声入力、発話終端検出(EOU)、音声認識、言語モデルによる応答内容生成、テキスト処理、音声合成、音声出力、およびデータ転送や圧縮エンコードおよびデコードなどにかかるオーバーヘッド、のうち、応答内容生成から音声合成までのスループットを向上し、応答速度を高速化する。言語モデルのクロックサイクルを1000トークン/秒の生成速度、1文を構成する単語数の平均を35語、1文を構成する平均文節数を2、1トークンあたりの平均対応語数を1語、生成テキストからのマーカー検出時間をε<0.000001秒とすると、応答文の生成開始から最初の音声信号が合成開始されるまでの持続時間は平均0.35秒から0.175秒に短縮される。音声入力発話終了から応答音声信号再生開始までの平均持続時間を0.9秒とした場合、短縮された時間が全体の遅延パイプラインに占める割合は約19.4%であることから、平均して約20%の応答速度向上が実現されることになる。
【図面の簡単な説明】
【0008】
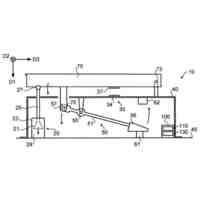
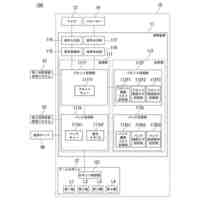
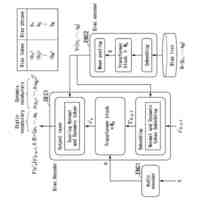
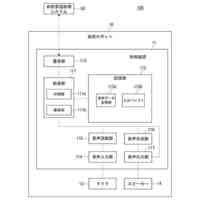
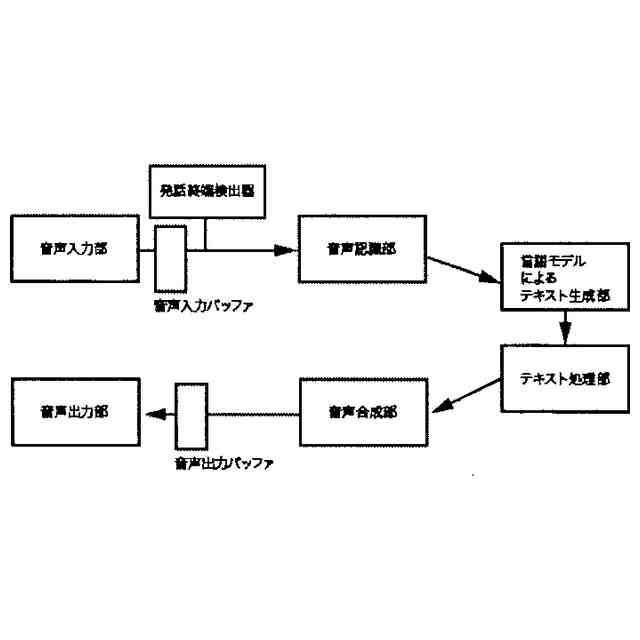
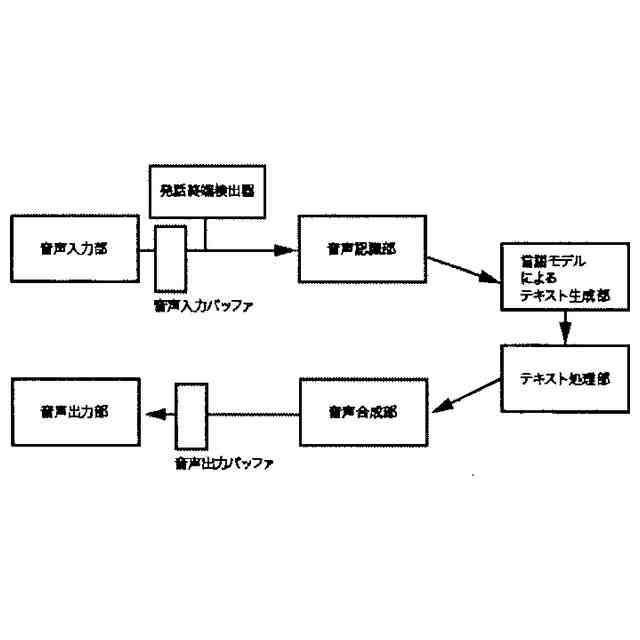
請求項1に記載された本発明の音声対話システムを構成する全体のパイプラインを図示した概念図である。このパイプラインは機械学習モデルを用いた音声対話システムを構成するパイプラインとして一般的である。
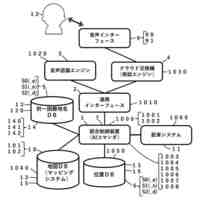
言語モデルを発話内容文生成器とした、本発明手法を用いない場合の一般的なアーキテクチャによる処理パイプラインを図示したものである。
言語モデルを発話内容文生成器とした、本発明手法を用いる場合の並列アーキテクチャによる処理パイプラインを図示したものである。
テキスト処理部が文節の区切りとなるマーカーを識別し、生成テキストを分割する2つのパターン、すなわちマーカーの直前と直後で分割する2つのパターン、を図示したものである。
【発明を実施するための形態】
【0009】
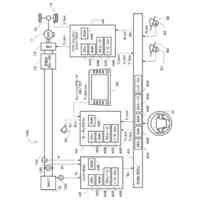
本発明の音声対話システムは、計算機端末上で動作するものであり、先述した音声入力部から音声出力部までの各部を備えてさえいれば、そのいずれかの要素が異なる端末上に分散していても構わない。例えばインターネットを経由せずにローカル端末内のみで実現される音声対話システムは各部が単一の計算機端末に配置される。一方、クラウド方式の音声対話システムでは音声入力部と音声出力部のみがローカル端末上に配置され、それ以外はインターネットで接続されたサーバー端末上に配置されるか、あるいは音声認識部や音声合成部がローカル端末上に配置される場合もある。その組み合わせは任意であり、本発明にとってどのような組み合わせでも構わない。
【0010】
本発明の想定する、音声対話システムを構成する各部の役割を説明する。
音声入力部は一般にマイク機器を通じ物理的な空気中の振動を電気的信号に変換し、アナログ信号をデジタル方式の計算機端末であればPCMをはじめとする離散表現を用い変換し、さらにバイナリやWAV、mp3等の形式で計算機上のメモリ空間に格納することで音声情報を取り込む。音声入力部は物理的に発話された音声信号をメモリ空間に記録できるものであればどのようなものでも構わない。
音声入力バッファは連続入力される音声信号を次の処理部である音声認識部に転送されるまでの間保持する計算機端末上のメモリ領域である。
音声認識部は音声入力部で記録され音声入力バッファより転送される音声信号を入力し、その音声信号によって発話していると推測される自然言語表現をテキストデータで出力する。出力されるテキストデータはUnicodeやASCII文字列、サブワードトークンのインデックスの列など、どのようにエンコードされたものでも構わない。
言語モデルによるテキスト生成部は、音声認識部から出力されたテキストデータ、さらに必要に応じ任意の付随情報を加えた入力を受け付け、その入力に対応する応答内容または必要に応じて付随する情報をテキストシーケンス、すなわちトークン列または語を任意の形式でエンコードした情報の列として、推論ステップの度に通常1トークンまたは1符号化単位で逐次的に出力する。出力されるテキストデータの形式は音声認識部で説明したのと同様、どのようにエンコードされていても構わない。また応答内容に付随する情報がどのようであっても構わない。例えば画像などが付随されて出力されても構わない。
テキスト処理部は、テキスト生成部から逐次的に生成され出力される符号列を、必要に応じて解析または場合によって操作し改変する。
音声合成部は言語モデルが生成した応答内容としてのテキストデータを入力し、その読み上げ音声としての音声信号を出力する。出力される音声信号のデータ形式はバイナリやWAVまたは任意の圧縮形式でエンコードされた形式など、どのような形式であっても構わない。
音声出力部は音声合成部が出力する音声信号のデジタルデータをヒト聴覚で知覚可能な物理的振動に変換し、スピーカーやヘッドフォンなど任意の機器を通じ出力する。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
ギター
4日前
個人
遮音材
1か月前
個人
歌唱補助器具
1か月前
横浜ゴム株式会社
音響材
25日前
個人
音声出力装置
1か月前
三井化学株式会社
防音構造体
5日前
三井化学株式会社
防音構造体
5日前
大和ハウス工業株式会社
音低減設備
1か月前
DIC株式会社
吸音材及び吸音部品
1か月前
個人
管楽器用音質改善留め具
19日前
NOK株式会社
吸音構造体
1か月前
株式会社デンソー
音低減装置
4日前
横浜ゴム株式会社
多層空洞音響材
1か月前
矢崎総業株式会社
車両用対話システム
1か月前
株式会社第一興商
カラオケ装置
1か月前
三井化学株式会社
防音構造体および自動車の防音構造
5日前
ヤマハ株式会社
鍵盤装置
12日前
ヤマハ株式会社
音処理装置及び音処理方法
19日前
有限会社 宮脇工房
モーター挙動音発生装置
1か月前
株式会社デンソー
制御装置、制御方法、及び制御プログラム
25日前
株式会社第一興商
カラオケ装置、カラオケシステム
4日前
株式会社第一興商
カラオケ装置、カラオケシステム
27日前
株式会社第一興商
カラオケ装置、カラオケシステム
11日前
固昌通訊股ふん有限公司
音響調整装置
1か月前
株式会社コルグ
楽音信号変換装置、楽音信号変換方法、プログラム
1か月前
本田技研工業株式会社
音声認識装置、音声認識方法、及びプログラム
6日前
トヨタ自動車株式会社
ブレーキインジケータシステム
4日前
株式会社枚方技研
方向付き楽器固定具
1か月前
株式会社デンソー
制御装置、ロボットシステム、制御方法、及び制御プログラム
1か月前
日本放送協会
エンコーダー・デコーダー装置、推論装置、およびプログラム
1か月前
エムケイ無線事業協同組合
音声応答システム、及びそれを利用した応答方法
1か月前
日本電気株式会社
伝達音抑制装置、伝達音抑制システム、伝達音抑制方法およびプログラム
4日前
パイオニア株式会社
効果音出力装置
1か月前
ヤマハ株式会社
音響信号処理装置、楽器、音響信号処理方法および音響信号処理プログラム
1か月前
ピクシーダストテクノロジーズ株式会社
遮音ユニット、遮音構造体、および区画設備
1か月前
パナソニックIPマネジメント株式会社
ノイズキャンセルシステムおよびノイズキャンセル方法
4日前
続きを見る
他の特許を見る
 特許ウォッチ
特許ウォッチ