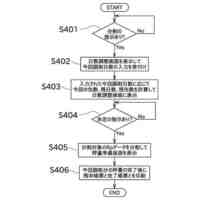
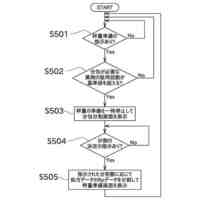
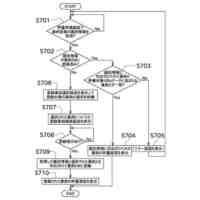
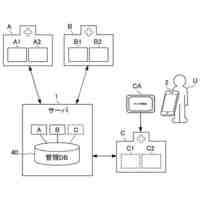
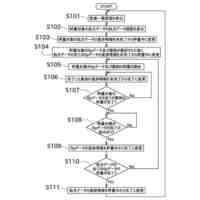
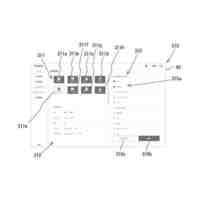
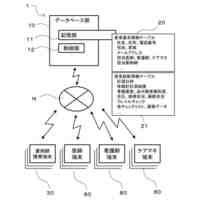
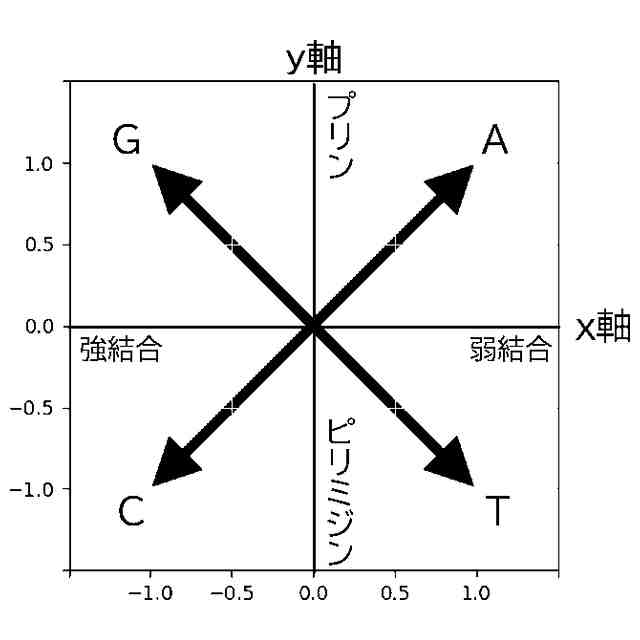
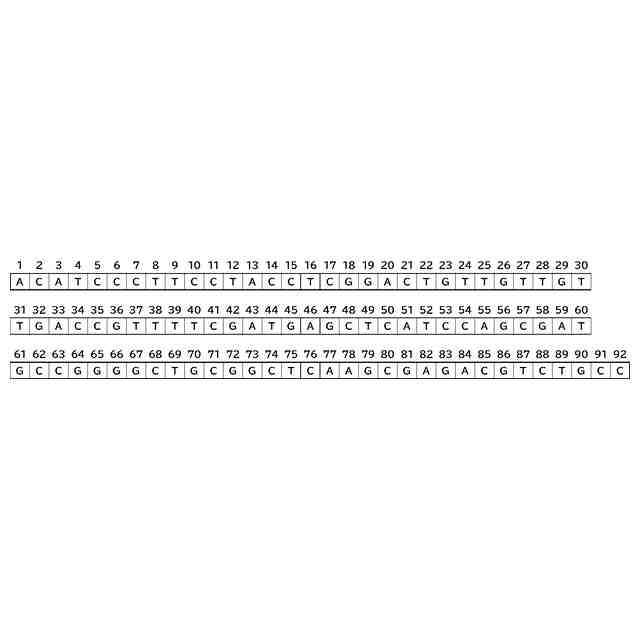
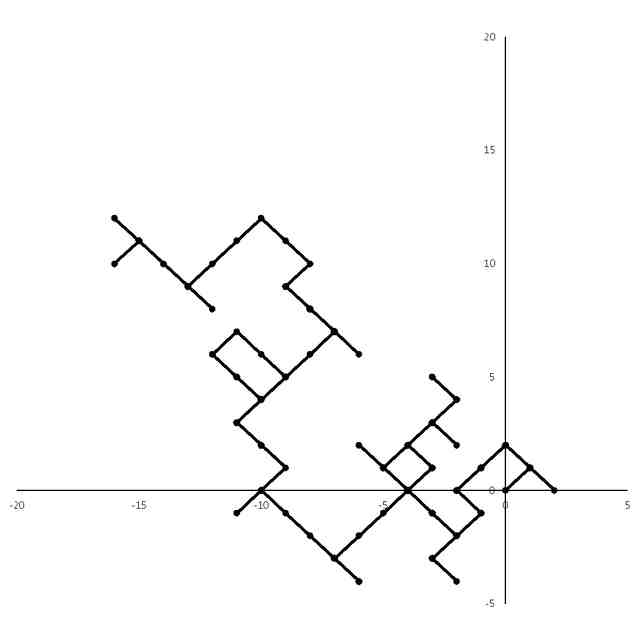
発明の詳細な説明【技術分野】 【0001】 本発明は、ゲノム配列の数値表現、類似性評価および可視化に関係する。 続きを表示(約 3,600 文字)【背景技術】 【0002】 DNAは4種の塩基の配列であり、塩基配列を符号化したゲノム配列は一般にATGCの4種の文字列として表現される。その文字列は、文字が不規則に並んでおり、人間が判読することは難しい。例えば、複数のゲノム配列があった場合、どこがどれだけ異なるのかあるいは似ているのか、人間が判読することは難しい。そのため、ゲノム配列の解析は、コンピュータによる文字列解析あるいは数値解析が行われる。例えば、多数のゲノム配列データから類似するゲノム配列を収集し、動的計画法による塩基の変異(置換、欠失、挿入)の推定などが行われる。類似するゲノム配列の収集にあたり、類似性評価が重要となるが、ゲノム配列の文字列の先頭からの一致率のみでは塩基の変異の影響を強く受け、同種の配列であっても類似性を正しく評価できない。そのため、塩基の変異についての事前情報がない状況において、変異の影響を小さく抑えて、類似性を評価する方法が必要となる。なお、ここでゲノム配列は、ゲノム全体または染色体や遺伝子などの一部の配列を指す。 【0003】 ゲノム配列はヒトの場合で全体では約30億文字分であり、染色体単位に分割しても数千万文字分のデータ量となる。ゲノム配列の大規模な調査に向けて、類似性評価の計算時間および記憶容量の増大を避ける方法が求められる。 【0004】 ゲノム配列を数値化した上で、評価関数を設定し、ゲノム配列の類似性評価を行う手法がいくつか提案されている。後記の非特許文献1に3次元ベクトルを用い、ゲノム配列を3次元データ配列に変換し、3次元グラフ(Hカーブ)の表示を行う数値化手法について記載されている。また、非特許文献2では、前記文献1とは異なる3次元ベクトルを用いて3次元グラフ(Zカーブ)の表示を可能にする数値化手法について記載されている。他にも、非特許文献3で、複数の3次元ベクトルを組合せてゲノム配列を数値化する手法が提案されている。非特許文献4では、9種類の数値化手法を取り上げ、ゲノム配列の類似性計算の評価を行っている。ゲノム配列の数値表現および類似性評価方法において、塩基の変異の影響を過度に受けないこと、計算時間および記憶容量の増大を避けること、双方を満たす標準となる手法はない。 【先行技術文献】 【非特許文献】 【0005】 Eugene Hamori and John Ruskin, H Curves, A Novel Method of Representation of Nucleotide Series Especially Suited for Long DNA Sequences, THE JOURNAOLF BIOLOGICAL CHEMISTRY Vol. 258, No, 2, 1983 Chun-Ting Zhang and Ren Zhang, Analysis of distribution of bases in the coding sequences by a diagrammatic technique, Nucleic Acids Research, Vol. 19, No. 22 6313-6317 Guosen Xie, Zhongxi Mo, 3D graphical representations of DNA primary sequences based on the classifications of DNA bases and their applications, Journal ofTheoreticalBiology269(2011)123–130 Gerardo Mendizabal-Ruiz, Israel Roma Ân – Godõ Ânez, Sulema Torres-Ramos, Ricardo A. Salido-Ruiz, J. Alejandro Morales, On DNA numerical representations for genomic similarity computation, PLOS ONE (https://doi.org/10.1371/journal.pone.0173288) March 21, 2017 【発明の概要】 【発明が解決しようとする課題】 【0006】 本発明が解決しようとする課題は、ゲノム配列の類似性評価において、DNA塩基の変異の影響を軽減すること、および、計算時間と記憶容量の増大を避けることである。 【課題を解決するための手段】 【0007】 DNAは4種の塩基から成る。2次元平面は4方向(上下左右)の軸で4象限に分けられる。DNAと2次元平面のこの特性を活かし、4塩基を4軸または4象限の座標にマッピングすることで、DNAゲノム配列の数値表現が可能となる。本発明では、DNAゲノム配列のATGCの4種のコードに、以下の3つの特性を備える4種の2次元ベクトル(ここでは要素ベクトルと呼ぶ)を割り当てる。 要素ベクトルの3つの特性: (1)2次元平面上で同じ大きさをもつ (2)対向する2つのベクトルで1つの組を成し、2組がある (3)異なる組のベクトルは垂直である さらに、ゲノム配列の各要素を調査開始点からの要素ベクトルの合成ベクトルに変換する。この合成ベクトルへの変換により、1次元のゲノム配列は2次元座標のデータ配列に変換される。2つのゲノム配列に前記の変換を実施し、得られる2組の2次元データ配列間の相互相関係数を計算し、類似性評価を行う。この方式は、RNA配列(AUGCの4種の文字配列)に対しても同様に用いることができる。 【0008】 ゲノム配列を2次元ベクトルの合成ベクトルに変換することの利点は、ゲノム配列を累積的な数値表現とすることで、ゲノム配列全体の大局的な類似性評価を可能にし、DNA塩基の変異の影響を過度に受けないことである。累積的な数値表現となることから、例えば、合成ベクトルの終点の座標はゲノム配列全体を反映したものとなる。要素ベクトルの合成の軌跡について注目すると、ひとつのDNA配列を元にし、DNA塩基の変異が発現した場合、本方式によるベクトル軌跡は、変異点で本来の軌跡から外れるが、変異点以外では元の軌跡と平行な軌跡を描く。このため、変異があっても俯瞰的には類似したベクトル軌跡となり、大局的な類似性評価が可能となる。また、2次元ベクトルを利用するより、3次元以上の多次元情報を用いる方法より、計算時間を削減することができる。 【0009】 相互相関係数を類似性評価に使用することの利点は、ゲノム配列の全体的な評価を行いDNA塩基の変異の影響を過度に受けないことである。相互相関係数の計算においては、各データ配列の各次元成分において、平均値からの各配列要素の偏差の総和を使用する。平均値は各次元成分の全体情報を反映しており、相互相関係数によりデータ配列間の全体的な相関関係を定量化することができる。以上から、本方式により俯瞰的な2次元データ配列間の相関性評価が可能となり、塩基の変異の影響を過度に受けることなく、ゲノム配列の類似性評価が可能となる。 【0010】 2組の2次元データ配列間の相互相関係数の計算は、一般的には、2次元の成分ごとに各配列要素について平均値からの偏差を求め、その偏差のデータ配列間の積の平均値を、各データ配列の成分の標準偏差の双方で除することで求められる。相互相関係数計算の初期段階で各成分の平均値を求める場合、データ配列全体を2回読み込むか、データ配列の全体をメモリに記憶する必要が生じる。相互相関係数の計算手順を変更し、各合成ベクトルの各次元成分の累計、成分の2乗の累計、合成ベクトル間の成分の積の累計を先に求め、その後に相互相関係数を求めることにする。これにより、ゲノム配列の読み込みから、合成ベクトルへの変換、合成ベクトル成分の累計と2乗の累計および合成ベクトル間の成分の積の累計の計算までを一連の処理(パイプライン)として配列要素ごとに実行することが可能になり、2次元データ配列の全体をメモリに記憶する必要がなく、かつ、ゲノム配列の読み込みを1回のみ行うことで相互相関係数の計算が実行可能となる。各種の累計計算(パイプライン内)を平行(オーバラップ)して実行することも可能であり、処理時間の短縮が可能となる。 (【0011】以降は省略されています) この特許をJ-PlatPat(特許庁公式サイト)で参照する

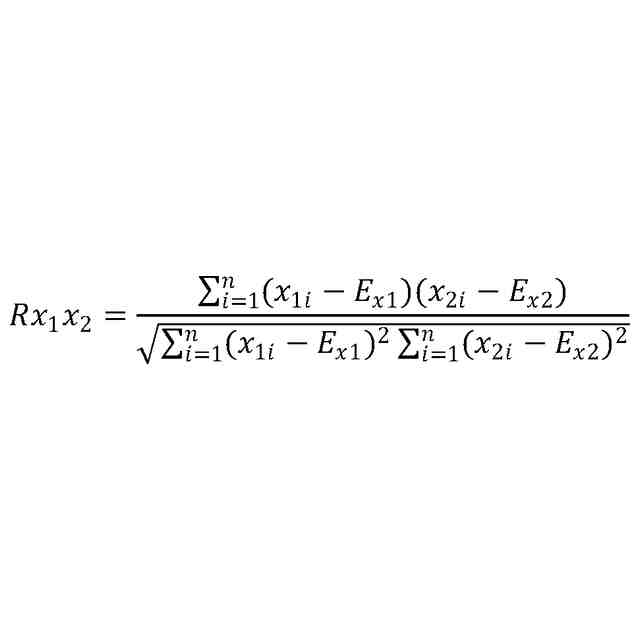
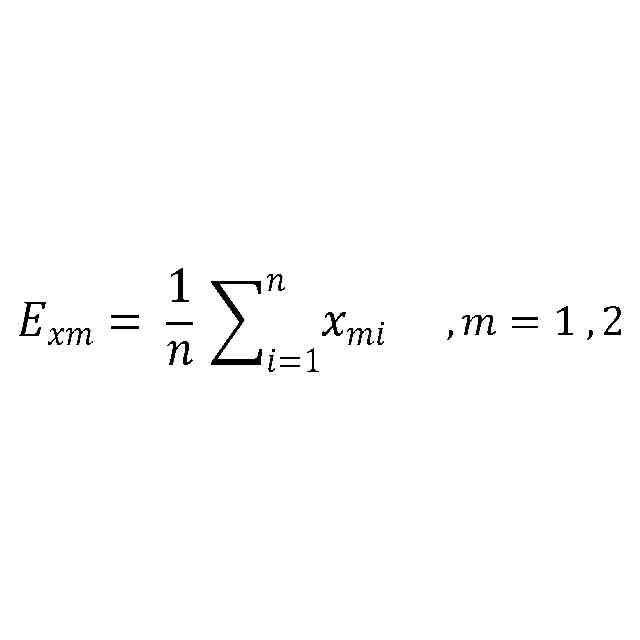
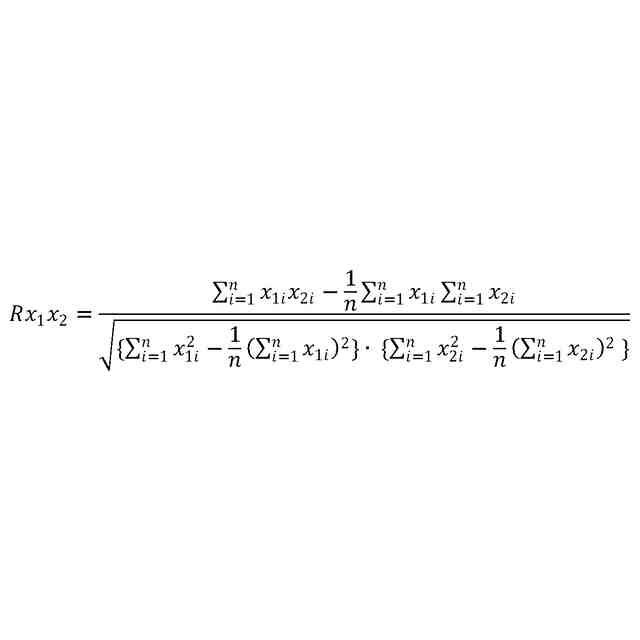



 特許ウォッチ
特許ウォッチ