TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025160369
公報種別
公開特許公報(A)
公開日
2025-10-22
出願番号
2025126469,2023199749
出願日
2025-07-29,2023-11-27
発明の名称
自己教師あり学習に基づく統合音声合成方法及び装置
出願人
スーパートーン インコーポレイテッド
代理人
弁理士法人太陽国際特許事務所
主分類
G10L
13/047 20130101AFI20251015BHJP(楽器;音響)
要約
【課題】膨大な量の音声及びテキストデータセットを用いて人工神経ネットワークを学習させる必要がなく、自己教師あり学習で自ら学習した人工神経ネットワークを用いて実際の音声と類似した音声を合成する方法及び装置を提供する。
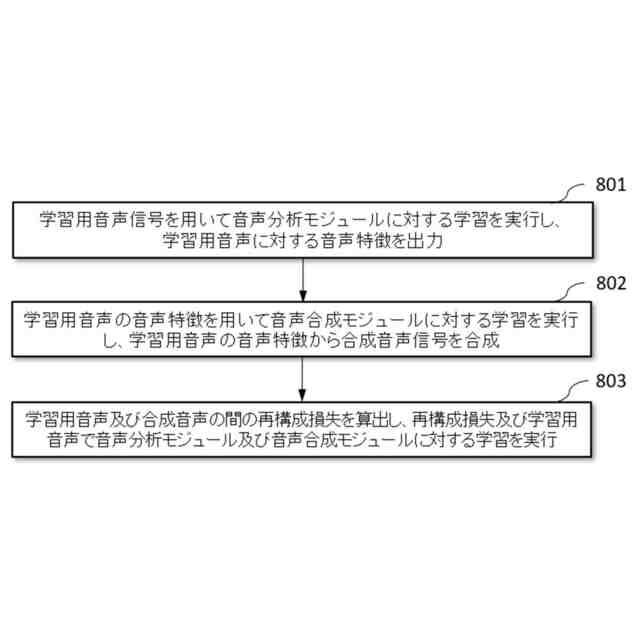
【解決手段】自己教師あり学習に基づく統合音声合成方法であって、学習用音声を示す学習用音声信号を用い、学習用音声信号に対する音声特徴を出力するように音声分析モジュールに対する学習を実行し、学習用音声に対する音声特徴を出力することと、出力された音声特徴を用い、学習用音声の音声特徴から音声信号を合成するように音声合成モジュールに対する学習を実行し、出力された音声特徴から合成音声を示す合成音声信号を合成することと、学習用音声及び合成音声の間の再構成損失を算出し、算出された再構成損失及び学習用音声で音声分析モジュール及び音声合成モジュールに対する学習を実行することと、を含む。
【選択図】図8
特許請求の範囲
【請求項1】
自己教師あり学習に基づく音声合成方法であって、
学習用音声を示す学習用音声信号を用い、前記学習用音声信号に対する音声特徴を出力するように音声分析モジュールに対する学習を実行し、前記学習用音声に対する音声特徴を出力する段階と、
前記出力された音声特徴を用い、前記学習用音声の音声特徴から音声信号を合成するように音声合成モジュールに対する学習を実行し、前記出力された音声特徴から合成音声を示す合成音声信号を合成する段階と、を含み、
前記学習用音声の音声特徴は、学習用音声の基本周波数F
0
、振幅、発音特徴及び音色特徴を含み、
前記学習用音声に対する音声特徴を出力する段階は、
前記学習用音声信号を複数の周波数ビンの確率分布スペクトラムに変換し、変換された確率分布スペクトラムから前記学習用音声の基本周波数F
0
及び振幅を出力する段階と、
前記学習用音声信号から前記学習用音声に含まれたテキストの発音特徴を出力する段階と、
前記学習用音声信号をスペクトログラムに変換し、変換されたスペクトログラムから前記学習用音声の音色特徴を出力する段階と、を含み、
前記出力された音声特徴から合成音声を示す合成音声信号を合成する段階は、
前記学習用音声の基本周波数F
0
及び振幅に基づいて、入力励起信号(input excitation signal)を生成する段階と、
前記学習用音声の音色特徴に基づいて、時間変化音色エンベディング(time-varying embedding)を生成する段階と、
前記学習用音声の発音特徴及び前記生成された時間変化音色エンベディングに基づいて、前記合成音声に対するフレームレベルコンディションを生成する段階と、
前記入力励起信号及び前記フレームレベルコンディションに基づいて、前記合成音声を示す合成音声信号を合成する段階と、を含むことを特徴とする、自己教師あり学習に基づく音声合成方法。
続きを表示(約 5,800 文字)
【請求項2】
前記学習用音声信号及び前記合成音声信号に基づいて、前記学習用音声信号及び前記合成音声信号の再構成損失を算出し、算出された再構成損失に基づいて前記音声分析モジュール及び前記音声合成モジュールに対する学習を実行する段階をさらに含むことを特徴とする、請求項1に記載の自己教師あり学習に基づく音声合成方法。
【請求項3】
自己教師あり学習に基づく音声合成装置であって、
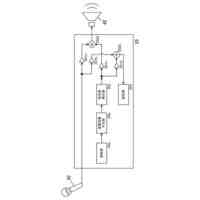
学習用音声を示す学習用音声信号を用い、前記学習用音声信号に対する音声特徴を出力するように音声分析モジュールに対する学習を実行し、前記学習用音声に対する音声特徴を出力する音声分析モジュール(103)と、
前記出力された音声特徴を用い、前記学習用音声の音声特徴から音声信号を合成するように音声合成モジュールに対する学習を実行し、前記出力された音声特徴から合成音声を示す合成音声信号を合成する音声合成モジュール(104)と、を含み、
前記学習用音声の音声特徴は、学習用音声の基本周波数F
0
、振幅、発音特徴及び音色特徴を含み、
前記音声分析モジュール(103)は、
前記学習用音声信号を複数の周波数ビンの確率分布スペクトラムに変換し、変換された確率分布スペクトラムから前記学習用音声の基本周波数F
0
及び振幅を出力する音高エンコーダー(1031)と、
前記学習用音声信号から前記学習用音声に含まれたテキストの発音特徴を出力する発音エンコーダー(1032)と、
前記学習用音声信号をスペクトログラムに変換し、変換されたスペクトログラムから前記学習用音声の音色特徴を出力する音色エンコーダー(1033)と、を含み、
前記音声合成モジュール(104)は、
前記学習用音声の基本周波数F
0
及び振幅に基づいて、入力励起信号(input excitation signal)を生成する正弦波ノイズ生成器(1041)と、
前記学習用音声の音色特徴に基づいて、時間変化音色エンベディング(time-varying embedding)を生成する時間変化音色人工神経ネットワーク(1043)と、
前記学習用音声の発音特徴及び前記生成された時間変化音色エンベディングに基づいて、前記合成音声に対するフレームレベルコンディションを生成するフレームレベル合成人工神経ネットワーク(1042)と、
前記入力励起信号及び前記フレームレベルコンディションに基づいて、前記合成音声を示す合成音声信号を合成するサンプルレベル合成人工神経ネットワーク(1044)と、を含むことを特徴とする、音声合成装置。
【請求項4】
学習用音声を示す学習用音声信号を用い、前記学習用音声信号に対する音声特徴を出力するように音声分析モジュールに対する学習を実行し、前記学習用音声に対する音声特徴を出力する音声分析モジュールと、前記出力された音声特徴を用い、前記学習用音声の音声特徴から音声信号を合成するように音声合成モジュールに対する学習を実行し、前記出力された音声特徴から合成音声を示す合成音声信号を合成する音声合成モジュールと、を含む音声合成装置で実行される自己教師あり学習に基づく歌声合成方法であって、
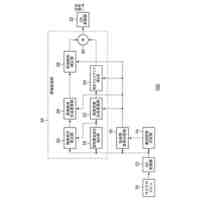
合成対象歌及び合成対象歌手を含む歌声合成要請を獲得する段階と、
前記歌声合成要請に基づいて、前記合成対象歌手に関連した音声信号を獲得する段階と、
SVS(Singing Voice Synthesis)モジュールで、前記歌声合成要請及び前記合成対象歌手に関連した音声信号に基づいて、前記合成対象歌及び前記合成対象歌手に対する基本周波数F
0
、振幅及び発音特徴を含む歌声特徴を生成する段階と、
前記音声分析モジュールで、前記獲得された合成対象歌手に関連した音声信号に基づいて前記合成対象歌手の音色特徴を生成する段階と、
前記音声合成モジュールで、前記歌声特徴及び前記音色特徴に基づいて、前記合成対象歌手の声で前記合成対象歌を歌った音声を示す歌声信号を合成する段階と、を含み、
前記学習用音声の音声特徴は、学習用音声の基本周波数F
0
、振幅、発音特徴及び音色特徴を含み、
前記音声分析モジュール(103)は、
前記学習用音声信号を複数の周波数ビンの確率分布スペクトラムに変換し、変換された確率分布スペクトラムから前記学習用音声の基本周波数F
0
及び振幅を出力する音高エンコーダー(1031)と、
前記学習用音声信号から前記学習用音声に含まれたテキストの発音特徴を出力する発音エンコーダー(1032)と、
前記学習用音声信号をスペクトログラムに変換し、変換されたスペクトログラムから前記学習用音声の音色特徴を出力する音色エンコーダー(1033)と、を含み、
前記音声合成モジュール(104)は、
前記学習用音声の基本周波数F
0
及び振幅に基づいて、入力励起信号(input excitation signal)を生成する正弦波ノイズ生成器(1041)と、
前記学習用音声の音色特徴に基づいて、時間変化音色エンベディング(time-varying embedding)を生成する時間変化音色人工神経ネットワーク(1043)と、
前記学習用音声の発音特徴及び前記生成された時間変化音色エンベディングに基づいて、前記合成音声に対するフレームレベルコンディションを生成するフレームレベル合成人工神経ネットワーク(1042)と、
前記入力励起信号及び前記フレームレベルコンディションに基づいて、前記合成音声を示す合成音声信号を合成するサンプルレベル合成人工神経ネットワーク(1044)と、を含むことを特徴とする、自己教師あり学習に基づく歌声合成方法。
【請求項5】
前記SVSモジュールは、学習用歌、学習用歌手音声及び学習用歌声特徴を含む学習用データセットによって、入力された合成対象歌及び合成対象歌手に対する歌声特徴を出力するように事前にトレーニングされた人工神経ネットワークであることを特徴とする、請求項4に記載の自己教師あり学習に基づく歌声合成方法。
【請求項6】
学習用音声を示す学習用音声信号を用い、前記学習用音声信号に対する音声特徴を出力するように音声分析モジュールに対する学習を実行し、前記学習用音声に対する音声特徴を出力する音声分析モジュールと、前記出力された音声特徴を用い、前記学習用音声の音声特徴から音声信号を合成するように音声合成モジュールに対する学習を実行し、前記出力された音声特徴から合成音声を示す合成音声信号を合成する音声合成モジュールと、を含む音声合成装置で実行される自己教師あり学習に基づく変造音声合成方法であって、
音声変換の対象となる変換前音声を獲得する段階と、
前記音声分析モジュールで、前記獲得した変換前音声に基づいて、前記変換前音声に対する基本周波数F
0
、振幅及び発音特徴を含む変換前音声特徴を出力する段階と、
変換音声に対する音声属性を獲得する段階と、
VOD(Voice Design)モジュールで、前記変換音声に対する音声属性に基づいて、変換音声に対する基本周波数F
0
及び音色特徴を含む変換音声特徴を出力する段階と、
前記音声合成モジュールで、前記変換前音声特徴及び前記変換音声特徴に基づいて変換音声を合成する段階と、を含み、
前記学習用音声の音声特徴は、学習用音声の基本周波数F
0
、振幅、発音特徴及び音色特徴を含み、
前記音声分析モジュール(103)は、
前記学習用音声信号を複数の周波数ビンの確率分布スペクトラムに変換し、変換された確率分布スペクトラムから前記学習用音声の基本周波数F
0
及び振幅を出力する音高エンコーダー(1031)と、
前記学習用音声信号から前記学習用音声に含まれたテキストの発音特徴を出力する発音エンコーダー(1032)と、
前記学習用音声信号をスペクトログラムに変換し、変換されたスペクトログラムから前記学習用音声の音色特徴を出力する音色エンコーダー(1033)と、を含み、
前記音声合成モジュール(104)は、
前記学習用音声の基本周波数F
0
及び振幅に基づいて、入力励起信号(input excitation signal)を生成する正弦波ノイズ生成器(1041)と、
前記学習用音声の音色特徴に基づいて、時間変化音色エンベディング(time-varying embedding)を生成する時間変化音色人工神経ネットワーク(1043)と、
前記学習用音声の発音特徴及び前記生成された時間変化音色エンベディングに基づいて、前記合成音声に対するフレームレベルコンディションを生成するフレームレベル合成人工神経ネットワーク(1042)と、
前記入力励起信号及び前記フレームレベルコンディションに基づいて、前記合成音声を示す合成音声信号を合成するサンプルレベル合成人工神経ネットワーク(1044)と、を含むことを特徴とする、自己教師あり学習に基づく変造音声合成方法。
【請求項7】
前記VODモジュールは学習用音声属性、学習用基本周波数F
0
及び学習用音色特徴を含む学習用データセットによって、入力された音声属性に基づいて変換音声の基本周波数F
0
及び音色特徴を出力するように事前にトレーニングされた人工神経ネットワークであることを特徴とする、請求項6に記載の自己教師あり学習に基づく変造音声合成方法。
【請求項8】
学習用音声を示す学習用音声信号を用い、前記学習用音声信号に対する音声特徴を出力するように音声分析モジュールに対する学習を実行し、前記学習用音声に対する音声特徴を出力する音声分析モジュールと、前記出力された音声特徴を用い、前記学習用音声の音声特徴から音声信号を合成するように音声合成モジュールに対する学習を実行し、前記出力された音声特徴から合成音声を示す合成音声信号を合成する音声合成モジュールと、を含む音声合成装置で実行される自己教師あり学習に基づくTTS(Text To Speech)合成方法であって、
TTS合成を行おうとする合成対象テキスト及び合成対象音声主体を獲得する段階と、
前記合成対象音声主体に基づいて、前記合成対象音声主体に関連した音声を獲得する段階と、
前記音声分析モジュールで、前記合成対象音声主体に関連した音声に基づいて、前記合成対象音声主体の音色特徴を含む合成対象音声主体の音声特徴を出力する段階と、
TTSモジュールで、合成対象テキスト及び合成対象音声主体に関連した音声に基づいて、前記合成対象テキストを前記合成対象音声主体の声で読んだテキスト音声に対する基本周波数F
0
及び振幅を含むテキスト音声の音声特徴を出力する段階と、
前記テキスト音声に対する基本周波数F
0
及び振幅、並びに前記合成対象音声主体の音色特徴に基づいて、テキスト音声を合成する段階と、を含み、
前記学習用音声の音声特徴は、学習用音声の基本周波数F
0
、振幅、発音特徴及び音色特徴を含み、
前記音声分析モジュール(103)は、
前記学習用音声信号を複数の周波数ビンの確率分布スペクトラムに変換し、変換された確率分布スペクトラムから前記学習用音声の基本周波数F
0
及び振幅を出力する音高エンコーダー(1031)と、
前記学習用音声信号から前記学習用音声に含まれたテキストの発音特徴を出力する発音エンコーダー(1032)と、
前記学習用音声信号をスペクトログラムに変換し、変換されたスペクトログラムから前記学習用音声の音色特徴を出力する音色エンコーダー(1033)と、を含み、
前記音声合成モジュール(104)は、
前記学習用音声の基本周波数F
0
及び振幅に基づいて、入力励起信号(input excitation signal)を生成する正弦波ノイズ生成器(1041)と、
前記学習用音声の音色特徴に基づいて、時間変化音色エンベディング(time-varying embedding)を生成する時間変化音色人工神経ネットワーク(1043)と、
前記学習用音声の発音特徴及び前記生成された時間変化音色エンベディングに基づいて、前記合成音声に対するフレームレベルコンディションを生成するフレームレベル合成人工神経ネットワーク(1042)と、
前記入力励起信号及び前記フレームレベルコンディションに基づいて、前記合成音声を示す合成音声信号を合成するサンプルレベル合成人工神経ネットワーク(1044)と、を含むことを特徴とする、自己教師あり学習に基づくTTS合成方法。
【請求項9】
前記TTSモジュールは、学習用合成テキスト、学習用音声及び学習用音声特徴を含む学習用データセットによって、入力されたテキスト及び音声に基づいてテキスト音声の基本周波数F
0
及び振幅を出力するように事前にトレーニングされた人工神経ネットワークであることを特徴とする、請求項8に記載の自己教師あり学習に基づくTTS合成方法。
【請求項10】
請求項1及び2のいずれか一項に記載の方法を実行するプログラムが記録された、コンピュータ可読の記録媒体。
発明の詳細な説明
【技術分野】
【0001】
自己教師あり学習に基づく統合音声合成方法及び装置に関し、より詳しくは自己教師あり学習に基づいて学習された機械学習モデルを用いて音声を合成することができるようにするための自己教師あり学習に基づく統合音声合成方法及び装置に関する。
続きを表示(約 2,000 文字)
【背景技術】
【0002】
音声合成(TTS;Text To Speech)技術は、コンピュータを用いてテキストで入力された任意の文章をヒトの声、すなわち音声信号として生成する技術を意味する。従来の音声合成技術は、音声信号を生成するとき、予め録音された一音節の音声信号を結合して文章全体に対する音声信号を生成する波形接続型音声合成(Concatenative TTS)方式と、音声の特徴が表現された高次元パラメーターからボコーダ(vocoder)を用いて音声信号を生成するパラメトリック音声合成(Parametric TTS)方式とに区分される。
【0003】
従来の波形接続型音声合成方式は、入力されたテキストに合わせて予め録音された単語、音節、音素の音声信号を結合して文章に対する全体音声信号を生成する。このように生成された文章に対する音声信号は予め録音された音声信号を合成したものであるので、音声信号において文章のイントネーション、韻律などが表現されなくて音声間の連結がスムーズでなく、ヒトの声とは異なる異質感が感じられる問題点があった。
【0004】
最近、人工知能(Artificial Intelligence、AI)技術が大きく発展している。音声合成の分野にもこのような人工知能技術が多様に活用されている。人工知能アルゴリズムとしては機械学習(machine learning)アルゴリズムを使用することができ、機械学習は、大別して、教師あり学習(Supervised Learning)及び自己教師あり学習(Self-Supervised Learning)に区別することができる。教師あり学習は、人工知能に基づく機械学習モデルに対して学習すべきデータ及びそのデータがどのデータであるかに対する正解ラベル(Label)を用いて人工知能モデルを学習させる。自己教師あり学習は、人工知能に基づく機械学習モデルに対して、学習すべきデータに対する正解ラベルなしに、学習すべきデータのみで人工知能モデルを学習させる。
【0005】
また、従来のパラメトリック音声合成方式は、音声信号の自然さを向上させるために、機械学習を用いる方式に発展した。これは、莫大な量のテキスト及び音声データを用いて人工神経ネットワークを学習させ、学習された人工神経ネットワークを用いて、入力された文章のテキストに対する音声信号を生成する。機械学習に基づくパラメトリック音声合成方式は、人工神経ネットワークを用いて入力テキストに対する音声信号を生成するので、学習された音声信号の音声主体のイントネーション、韻律などを表現する音声信号を生成することができる。したがって、波形接続型音声合成方式よりも自然な音声信号を生成することができる。しかし、このような機械学習に基づくパラメトリック音声合成方式は、人工神経ネットワークを学習させるために膨大な量の音声及びテキストデータセットが必要な欠点が存在する。
【0006】
上述した従来の音声合成技術の欠点は歌声合成(SVS;Singing Voice Synthesis)技術でも同様である。ここで、歌声合成技術は、歌詞テキスト及び楽譜データなどを用いて歌声信号を生成する技術である。従来の音声合成技術のうち、波形接続型音声合成方式は、事前に録音された種類の音素発話のみを生成することができ、音の高低、音の長さ、拍子などが自由に変形できる歌声信号を生成することができない。よって、歌声合成分野では、人工神経ネットワークを用いたパラメトリック音声合成方式が主に活用されている。
【0007】
このような人工神経ネットワークに基づくパラメトリック音声合成方式は、まず任意の歌手に対する歌声、当該曲に対する楽譜、及び歌詞テキストで人工神経ネットワークを学習させる。学習された人工神経ネットワークは、入力された楽譜及び歌詞テキストに基づいて、学習された歌手の歌声(すなわち、歌)と音色及び唱法の類似した歌声信号を生成することができる。
【0008】
このような問題点は、パラメトリック音声合成方式だけでなく、既存の他の音声合成又は歌声合成方法においても同様である。
【0009】
したがって、このような問題点を解決するために、自己教師あり学習に基づく音声又は歌声合成方法に対する必要性が台頭している。
【先行技術文献】
【特許文献】
【0010】
韓国公開特許第10-2020-0015418号公報
韓国登録特許第10-1991733号公報
韓国登録特許第10-2057926号公報
【非特許文献】
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
木管楽器
25日前
個人
歌唱補助器具
3日前
個人
管楽器用リガチャ-
11日前
大和ハウス工業株式会社
音低減設備
4日前
本田技研工業株式会社
車室環境制御装置
29日前
DIC株式会社
吸音材及び吸音部品
5日前
積水樹脂株式会社
吸音シート
29日前
株式会社SinasSP
自動騒音低減装置
16日前
株式会社第一興商
カラオケ装置
23日前
日本軽金属株式会社
遮音壁
23日前
株式会社第一興商
カラオケ装置
29日前
カシオ計算機株式会社
発音装置、発音方法及びプログラム
18日前
トヨタ自動車株式会社
判定装置
18日前
ブラザー工業株式会社
カラオケ装置及びカラオケプログラム
23日前
シャープ株式会社
電子機器および電子機器の制御方法
23日前
日本電気株式会社
放送用システムおよび字幕作成方法
25日前
カシオ計算機株式会社
電子鍵盤楽器
29日前
大建工業株式会社
吸音体及び音環境調整構造
18日前
ブラザー工業株式会社
音声録音装置、及び、音声録音用プログラム
22日前
株式会社JVCケンウッド
収音装置、収音方法、およびプログラム
18日前
ブラザー工業株式会社
カラオケ用プログラム、及び、カラオケ装置
22日前
カシオ計算機株式会社
電子楽器、電子楽器の制御方法及びプログラム
29日前
有限会社ツバサ
エレキギターおよび保護フィルム付きの樹脂プレート
16日前
トヨタ自動車株式会社
運転者認知機能改善システム
29日前
株式会社河合楽器製作所
鍵盤楽器の鍵盤装置
24日前
株式会社河合楽器製作所
鍵盤楽器の鍵盤装置
24日前
有限会社 宮脇工房
モーター挙動音発生装置
3日前
株式会社NTTドコモ
情報処理装置及び情報処理方法
23日前
株式会社SUBARU
乗物用遮音構造体、及び車両
15日前
株式会社リコー
対話装置、対話システム、対話方法及びプログラム
22日前
株式会社河合楽器製作所
鍵盤楽器の楽音制御装置
24日前
株式会社河合楽器製作所
鍵盤楽器の楽音制御方法
24日前
株式会社河合楽器製作所
鍵盤楽器の楽音制御方法
24日前
カシオ計算機株式会社
演奏装置、方法およびプログラム
1か月前
株式会社プレシジョン
プログラム、情報処理装置及び方法
29日前
本田技研工業株式会社
能動型振動騒音低減装置
23日前
続きを見る
他の特許を見る









 特許ウォッチ
特許ウォッチ