TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025159405
公報種別
公開特許公報(A)
公開日
2025-10-21
出願番号
2024061899
出願日
2024-04-08
発明の名称
情報処理装置、制御方法、および制御プログラム
出願人
コニカミノルタ株式会社
代理人
IBC一番町弁理士法人
主分類
G06N
20/00 20190101AFI20251014BHJP(計算;計数)
要約
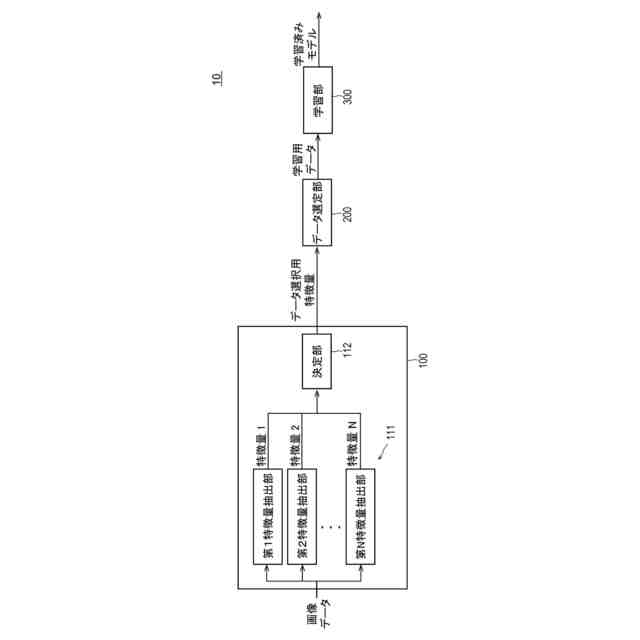
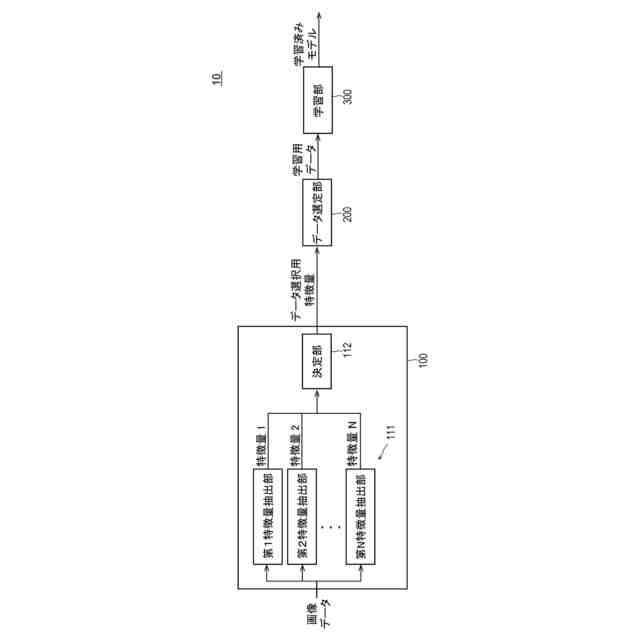
【課題】適切な学習用データの効率的な選定ができる情報処理装置を提供する。
【解決手段】データから特徴量をそれぞれ抽出する、互いに異なる複数の抽出部と、複数の前記抽出部によりそれぞれ抽出された複数の特徴量に基づいて、モデルの学習用データとして用いる前記データの選定に用いる前記特徴量を決定する決定部と、を含む情報処理装置。
【選択図】図1
特許請求の範囲
【請求項1】
データから特徴量をそれぞれ抽出する、互いに異なる複数の抽出部と、
複数の前記抽出部によりそれぞれ抽出された複数の特徴量に基づいて、モデルの学習用データとして用いる前記データの選定に用いる前記特徴量を決定する決定部と、
を有する情報処理装置。
続きを表示(約 1,300 文字)
【請求項2】
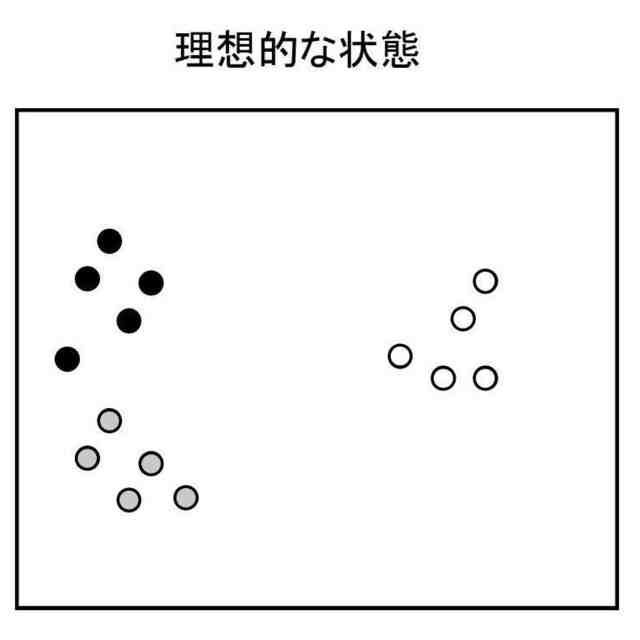
前記決定部は、前記抽出部ごとに、抽出される前記特徴量をクラスタリングし、クラスタ数が前記モデルにより実行されるタスクのクラス数に近い前記特徴量を抽出する前記抽出部を選定し、選定された前記抽出部により抽出される前記特徴量を、前記データの選定に用いる前記特徴量として決定する、請求項1に記載の情報処理装置。
【請求項3】
前記決定部は、前記抽出部ごとに、抽出される前記特徴量をクラスタリングし、各クラスタのバラツキが小さい前記特徴量を抽出する前記抽出部を選定し、選定された前記抽出部により抽出される前記特徴量を、前記データの選定に用いる前記特徴量として決定する、請求項1に記載の情報処理装置。
【請求項4】
前記決定部は、前記抽出部ごとに、抽出される前記特徴量をクラスタリングし、クラスタ間の距離が大きい前記特徴量を抽出する前記抽出部を選定し、選定された前記抽出部により抽出される前記特徴量を、前記データの選定に用いる前記特徴量として決定する、請求項1に記載の情報処理装置。
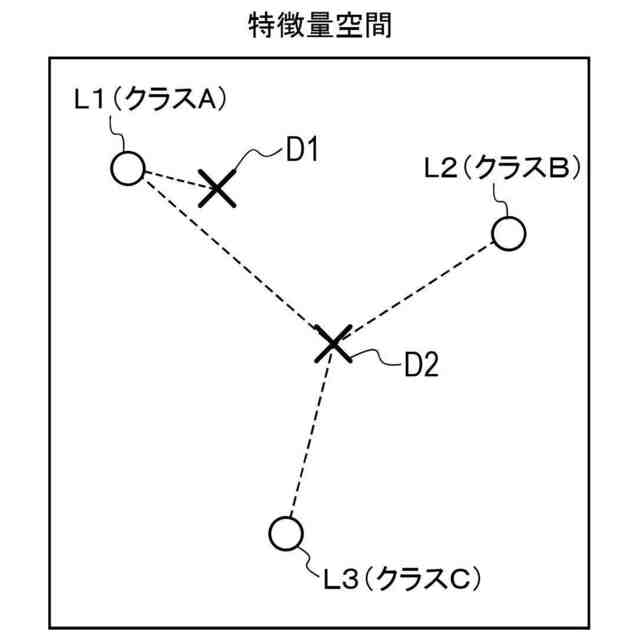
【請求項5】
前記決定部は、ラベルが付された前記データから抽出される前記特徴量のうち、同じ前記ラベルが付された前記データから抽出される前記特徴量が近い前記特徴量を抽出する前記抽出部を選定し、選定された前記抽出部により抽出される前記特徴量を、前記データの選定に用いる前記特徴量として決定する、請求項1に記載の情報処理装置。
【請求項6】
前記決定部は、ラベルが付された前記データから抽出される前記特徴量のうち、異なる前記ラベルが付された前記データから抽出される前記特徴量が離れた前記特徴量を抽出する前記抽出部を選定し、選定された前記抽出部により抽出される前記特徴量を、前記データの選定に用いる前記特徴量として決定する、請求項1に記載の情報処理装置。
【請求項7】
前記決定部は、1つの前記抽出部を選定する、請求項2~6のいずれか一項に記載の情報処理装置。
【請求項8】
前記決定部は、選定された複数の前記抽出部によりそれぞれ抽出される前記特徴量を加算した各値を、前記データの選定に用いる前記特徴量として決定する、請求項2~6のいずれか一項に記載の情報処理装置。
【請求項9】
前記決定部は、選定された複数の前記抽出部によりそれぞれ抽出される前記特徴量をマージした各値を、前記データの選定に用いる前記特徴量として決定する、請求項2~6のいずれか一項に記載の情報処理装置。
【請求項10】
前記決定部による前記特徴量の決定の過程を表示する表示部と、
前記抽出部をユーザーにより選択可能に表示するユーザーインターフェースと、をさらに有し、
前記決定部は、前記ユーザーインターフェースにおいて選択された前記抽出部により抽出される前記特徴量を、前記データの選定に用いる前記特徴量として再決定する、請求項1に記載の情報処理装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、情報処理装置、制御方法、および制御プログラムに関する。
続きを表示(約 1,300 文字)
【背景技術】
【0002】
近年、機械学習を用いた様々な技術が開発されている。例えば、機械学習により学習された学習済みモデルを含む分類器は、各種データを複数のクラスに分類できる。学習済みモデルは、データから特徴量を抽出し、抽出した特徴量に基づいてデータを複数のクラスのいずれかに分類する。例えば、製品の製造現場においては、画像データの入力に対して、良品か不良品かを分類する分類器が製品の検査に用いられ得る。
【0003】
分類器の性能を向上させるためには、一般的に、機械学習に用いる教師データの数が多いほどよい。しかし、大量の教師データに正解ラベルを付与するアノテーションには多大な労力および時間が必要である。
【0004】
このような問題を解決するために、学習効果が高いと推定される最小限のデータを選び出し、選び出したデータにのみアノテーションを行ってモデルを学習させるアクティブラーニングと呼ばれる技術がある。
【0005】
下記の特許文献には次の先行技術が開示されている。正解なしデータから特徴ベクトルを算出する。選定候補の正解なしデータから算出された特徴ベクトルと、選定候補以外の正解なしデータから算出された特徴ベクトルと、の類似度を選定候補ごとに算出する。特徴ベクトルは、データから算出した複数の特徴量をベクトル形式で表したものである。算出された、類似度がより高い選定候補の正解なしデータを、学習に有効と推測されるデータとして選定する。
【先行技術文献】
【特許文献】
【0006】
特開2022-184272号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
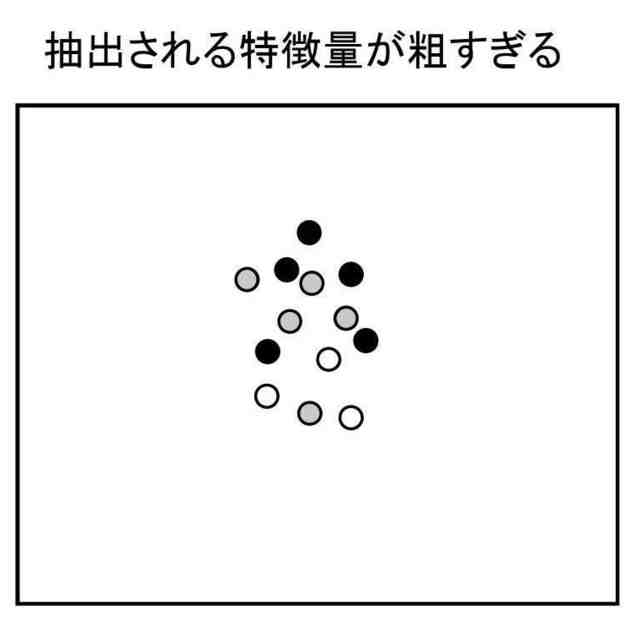
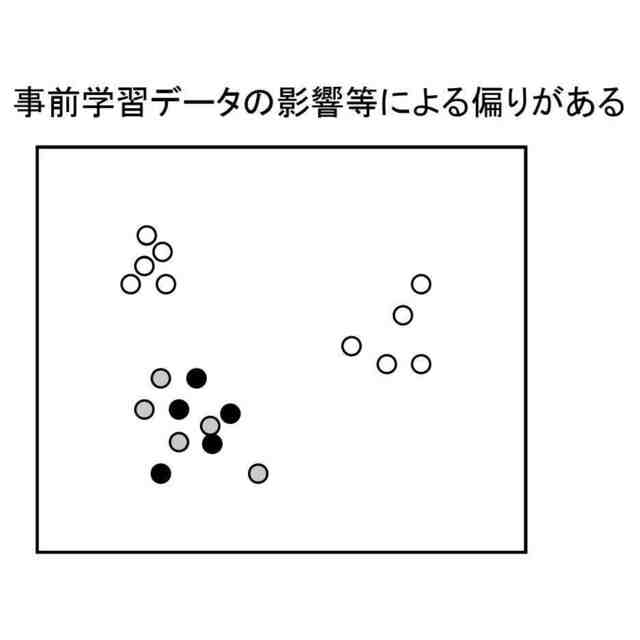
データから特徴量を抽出できるモデルとして、CNN(Convolution Neural Network)系、トランスフォーマー系、LLM(Large Language Models)等さまざまなモデルが存在する。そして、これらのモデルにより抽出される特徴量の傾向や粒度は比較的大きく異なり得る。このため、データから抽出される特徴量に基づいて、分類器の学習に用いる学習用データを選定する場合に、特徴量の抽出に用いるモデルによっては、適切な学習用データを選定できない可能性がある。上記先行技術は、このような問題に対応できない。
【0008】
本発明は、上述の問題を解決するためになされたものである。すなわち、本発明は、適切な学習用データの効率的な選定を可能とする情報処理装置、制御方法、および制御プログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
本発明の上記課題は、以下の手段によって解決される。
【0010】
(1)データから特徴量をそれぞれ抽出する、互いに異なる複数の抽出部と、複数の前記抽出部によりそれぞれ抽出された複数の特徴量に基づいて、モデルの学習用データとして用いる前記データの選定に用いる前記特徴量を決定する決定部と、を有する情報処理装置。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
詐欺保険
17日前
個人
縁伊達ポイン
17日前
個人
RFタグシート
4日前
個人
QRコードの彩色
21日前
個人
ペルソナ認証方式
1日前
個人
自動調理装置
3日前
個人
残土処理システム
23日前
個人
農作物用途分配システム
16日前
個人
インターネットの利用構造
今日
個人
タッチパネル操作指代替具
10日前
個人
知的財産出願支援システム
24日前
個人
携帯端末障害問合せシステム
9日前
個人
スケジュール調整プログラム
9日前
個人
エリアガイドナビAIシステム
1日前
個人
音声・通知・再配達UX制御構造
24日前
キヤノン株式会社
印刷システム
9日前
トヨタ自動車株式会社
通知装置
7日前
個人
帳票自動生成型SaaSシステム
24日前
エッグス株式会社
情報処理装置
10日前
株式会社カネカ
製造工場の管理システム
24日前
トヨタ自動車株式会社
車両
8日前
大同特殊鋼株式会社
棒材計数方法
22日前
太陽誘電株式会社
表示装置
7日前
TOTO株式会社
姿勢評価システム
22日前
株式会社PIPS
2次元可視コード
14日前
株式会社オカムラ
電力供給システム
21日前
TOTO株式会社
衛生評価システム
22日前
株式会社栗本鐵工所
触覚提示システム
22日前
株式会社栗本鐵工所
触覚提示システム
22日前
株式会社栗本鐵工所
触覚提示システム
22日前
日本電気株式会社
異常検知装置
8日前
三菱電機株式会社
点検管理装置
1日前
中国電力株式会社
空き家判定システム
21日前
株式会社栗本鐵工所
触覚提示システム
22日前
株式会社三富
取引管理システム
3日前
株式会社JVCケンウッド
画像表示方法
22日前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ