TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025020226
公報種別
公開特許公報(A)
公開日
2025-02-12
出願番号
2024189109,2023151488
出願日
2024-10-28,2019-12-11
発明の名称
自動アシスタントによって応答アクションをトリガするためのホットコマンドの検出および/または登録
出願人
グーグル エルエルシー
,
Google LLC
代理人
個人
,
個人
,
個人
主分類
G10L
15/28 20130101AFI20250204BHJP(楽器;音響)
要約
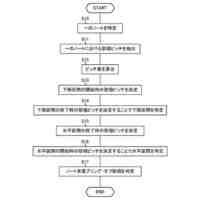
【課題】最初に明示的に起動させなければならないことを伴わずに、自動アシスタントに応答アクションを実行させるために使用可能な新しいホットコマンドを検出するか又はは登録する方法、システム及びコンピュータ可読媒体を提供する。
【解決手段】コンピューティングデバイス上で動作する自動アシスタントは、トリガイベントに応答して限定聴取状態から完全音声認識状態に遷移され、完全音声認識状態にある間、テキストコマンドを生成するためにユーザから話されたコマンドを受信し、それに対して音声認識処理を実行し、テキストコマンドがテキストコマンドのコーパス内の頻度しきい値を満たすかどうか決定し、満たす場合、テキストコマンドを示すデータをホットコマンドとして登録する。テキストコマンドに意味的に矛盾しない別のテキストコマンドの後続の発話は、明示的な起動を必要とせずに、自動アシスタントによる応答アクションの実行をトリガする。
【選択図】図6
特許請求の範囲
【請求項1】
1つまたは複数のプロセッサを使用して実装される方法であって、
前記プロセッサのうちの1つまたは複数を使用して、自動アシスタントを動作させるステップと、
トリガイベントに応答して、前記自動アシスタントを限定聴取状態から完全音声認識状態に遷移させるステップと、
前記完全音声認識状態にある間、前記自動アシスタントによって、ユーザから話されたコマンドを受信するステップと、
テキストコマンドを生成するために、前記話されたコマンドに対して音声認識処理を実行するステップと、
前記テキストコマンドがテキストコマンドのコーパス内の頻度しきい値を満たすと決定するステップと、
前記決定に応答して、前記テキストコマンドを示すデータをホットコマンドとして登録するステップであって、前記登録に続いて、前記テキストコマンドに意味的に矛盾しない別のテキストコマンドの発話が、前記自動アシスタントの明示的な起動を必要とせずに、前記自動アシスタントによる応答アクションの実行をトリガする、登録するステップと
を含む、方法。
続きを表示(約 1,100 文字)
【請求項2】
前記トリガイベントが、マイクロフォンによってキャプチャされたオーディオデータ内の1つまたは複数のデフォルトホットワードの検出を含む、請求項1に記載の方法。
【請求項3】
テキストコマンドの前記コーパスが、前記ユーザによって生成されたテキストコマンドのコーパスを含む、請求項1に記載の方法。
【請求項4】
テキストコマンドの前記コーパスが、前記ユーザを含めて、ユーザの集団によって生成されたテキストコマンドのコーパスを含む、請求項1に記載の方法。
【請求項5】
出力を生成するために、機械学習モデルにわたって、入力として前記テキストコマンドを適用するステップであって、前記出力が、前記テキストコマンドが前記自動アシスタントに向けられた確率を示し、前記登録が、前記確率によるしきい値の満足にさらに応答する、適用するステップをさらに含む、請求項1に記載の方法。
【請求項6】
1つまたは複数のカメラによってキャプチャされた視覚データに基づいて、前記ユーザの視線が、その上で前記自動アシスタントが少なくとも部分的に実装されるコンピューティングデバイスに向けられていることを検出するステップをさらに含み、前記登録が、前記検出にさらに応答する、請求項1に記載の方法。
【請求項7】
前記登録するステップが、前記話されたコマンドの後の所定の時間間隔中、何の追加の発話も検出されていないとの決定にさらに応答する、請求項1に記載の方法。
【請求項8】
前記登録するステップが、前記話されたコマンドの後の所定の時間間隔中、ある人物によって何の応答アクションも行われなかったとの決定にさらに応答する、請求項1に記載の方法。
【請求項9】
前記登録するステップに応じて、前記テキストコマンドを示すデータまたは前記テキストコマンド自体を、前記自動アシスタントを少なくとも部分的に実装するコンピューティングデバイスのローカルメモリ内にキャッシュするステップをさらに含む、請求項1に記載の方法。
【請求項10】
前記テキストコマンドに応答する情報をキャッシュするために、前記テキストコマンドが明示的に起動されずに、前記キャッシュされたデータに基づいて、前記登録するステップに続いて前記テキストコマンドをトリガするステップをさらに含み、前記トリガするステップに続いて、前記キャッシュされた情報が、前記テキストコマンドがトリガされる代わりに、前記テキストコマンドの後続の起動に応じて出力される、請求項9に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【背景技術】
【0001】
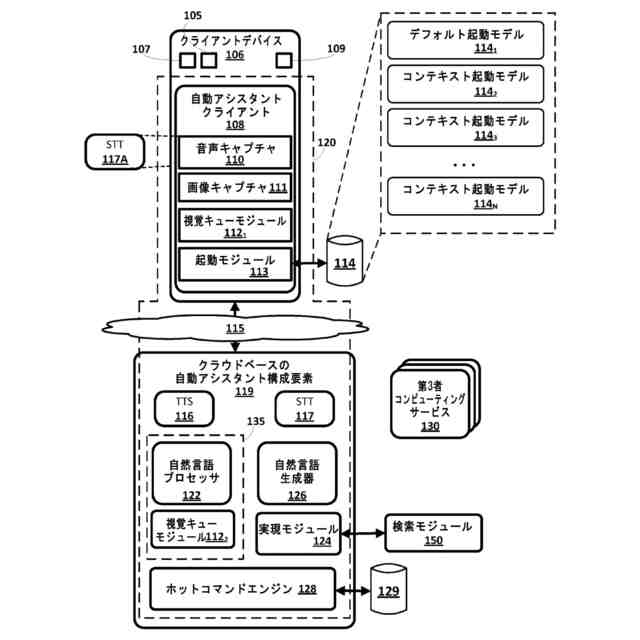
人間は、本明細書で「自動アシスタント」と呼ばれる(「チャットボット」、「対話型パーソナルアシスタント」、「インテリジェントパーソナルアシスタント」、「パーソナルボイスアシスタント」、「会話エージェント」、「仮想アシスタント」などとも呼ばれる)対話型ソフトウェアアプリケーションと人間対コンピュータダイアログに従事し得る。たとえば、人間(その人間が自動アシスタントと対話するとき、「ユーザ」と呼ばれることがある)は、テキストに変換され、次いで、処理および/またはタイプされた自由形式自然言語入力に変換される音声発話を含み得る自由形式自然言語入力を使用して、コマンド、クエリ、および/または要求を提供し得る。
続きを表示(約 3,800 文字)
【0002】
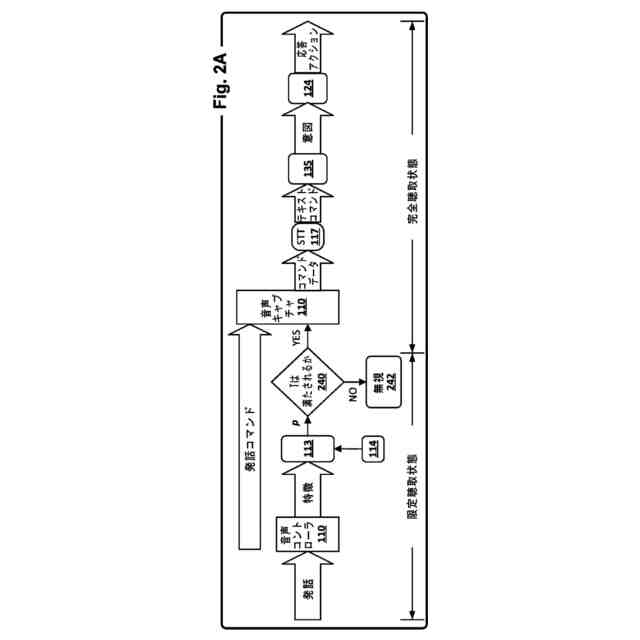
多くの場合、自動アシスタントがユーザの要求を解釈してそれに応答し得る前に、自動アシスタントは、最初に、たとえば、しばしば「ホットワード」または「ウェイクワード」と呼ばれる、事前定義された口頭起動フレーズを使用して、「起動」されなければならない。したがって、多くの自動アシスタントは、自動アシスタントがホットワードの限定(または、有限または「デフォルト」)セットに対してマイクロフォンによってサンプリングされるオーディオデータを常に「聴取している」状態である、本明細書で「限定聴取状態」または「デフォルト聴取状態」と呼ばれることになる状態で動作する。ホットワードのデフォルトセット以外のオーディオデータ内でキャプチャされたいずれの発話も無視される。ホットワードのデフォルトセットのうちの1つまたは複数で自動アシスタントが起動されると、自動アシスタントは、自動アシスタントが起動後の少なくとも何らかの時間間隔にわたって、自動アシスタントがマイクロフォンによってサンプリングされたオーディオデータの音声対テキスト(「STT」)処理(「音声認識処理」とも呼ばれる)を行って、テキスト入力を生成し、次に、ユーザの意図を決定する(また、その意図を実現する)ために意味的に処理される、本明細書で「完全聴取状態」と呼ばれることになる状態で動作し得る。
【0003】
デフォルト聴取状態で自動アシスタントを動作させることは、様々な利益をもたらす。「聴取される」ホットワードの数を限定することは、電力および/または計算リソースの節約を可能にする。たとえば、オンデバイス機械学習モデルは、1つまたは複数のホットワードがいつ検出されるかを示す出力を生成するようにトレーニングされ得る。そのようなモデルの実装は、最低限の計算リソースおよび/または電力のみを必要とし得、これは、リソース制約されることが多いアシスタントデバイスにとって特に有益である。これらの利益と共に、自動アシスタントを限定ホットワード聴取状態で動作させることは、様々な課題をやはり提示する。不注意による自動アシスタントの起動を回避するために、ホットワードは、一般に、日常の会話において発話されることがあまりないワードまたはフレーズ(たとえば、「ロングテール」ワードまたは「ロングテール」フレーズ)になるように選択される。しかしながら、何らかのアクションを実行するために自動アシスタントを起動させる前にロングテールホットワードを発話することをユーザに要求する、厄介であり得る様々なシナリオが存在する。
【発明の概要】
【課題を解決するための手段】
【0004】
最初に明示的に起動させなければならないことを伴わずに、自動アシスタントに応答アクションを実行させるために使用可能な新しい「ホットコマンド」を検出および/または登録する(または、作動させる(commissioning))ための技法について本明細書で説明する。本明細書で使用する「ホットコマンド」は、話されたとき、自動アシスタントが、最初に明示的に起動され、自動アシスタントがいずれかのキャプチャされた発話に応答することを試みる完全聴取/応答状態に遷移することを必要とせずに、自動アシスタントが応答する1つまたは複数のワードまたはフレーズを指す。
【0005】
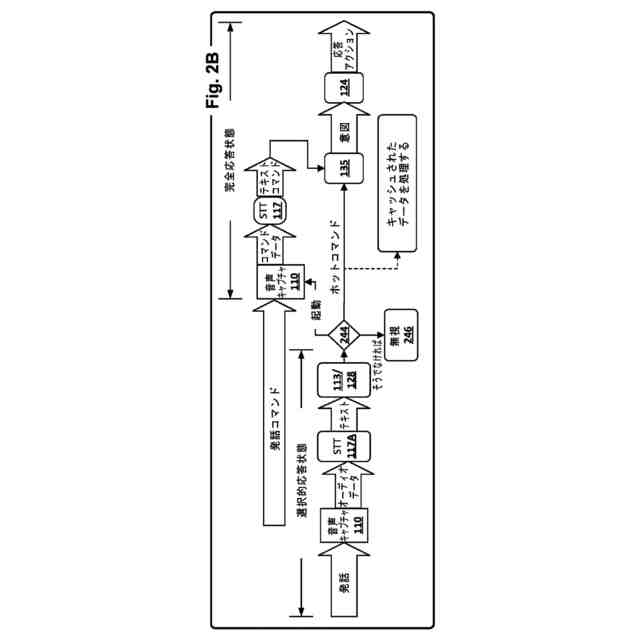
いくつかの実装形態では、音声認識は、ディスプレイ、カメラ、および/または他のセンサーなど、他の構成要素を含んでよく、または含まなくてもよい、全体的にまたは少なくとも部分的に、スタンドアロン対話型スピーカ(speaker)などのクライアントデバイスにオンボードで実装され得る。いくつかのそのような実装形態では、自動アシスタントは、自動アシスタントが起動した直後以外の時点でキャプチャされた、話された発話に対して音声認識処理を実行し得る。これらの他の時点は、たとえば、ユーザがコンピューティングデバイスに近接して検出されるときはいつでも、ユーザ音声が検出され、テレビジョンまたはラジオなど、別の機械から発生していないと決定されるときはいつでも、などを含み得る。
【0006】
言い換えれば、いくつかの実装形態では、本開示の選択された態様で構成された自動アシスタントを実装するコンピューティングデバイスは、上記で論じたように、自動アシスタントが明示的に起動された後で検出される発話に対してのみ音声認識処理を実行し得る、従来の自動アシスタントよりも多くの検出された発話に対して音声認識処理を実行し得る。この音声認識処理から生成されるテキスト断片は、これらのテキスト断片が自動アシスタントによる応答アクションをトリガすべきか、ホットコマンドとして登録されるべきか、または無視または廃棄されるべきかを決定するために、本明細書で説明する技法を使用して分析され得る。多くの実装形態では、テキスト断片は従来の自動アシスタントよりも検出される発話のより大きな部分に対して生成されるにもかかわらず、本明細書で説明する技法は、クライアントデバイス上で局所的に実行され、それにより、クラウドベースのシステムへのテキスト断片の送信を回避し得る。
【0007】
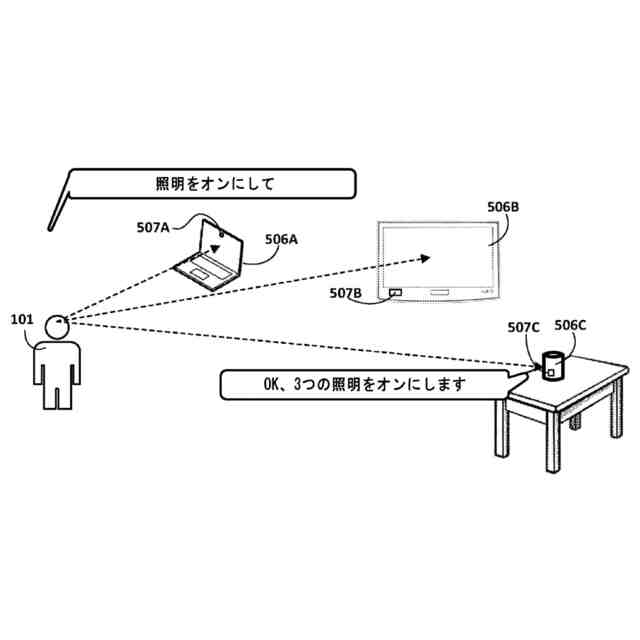
いくつかの実装形態では、ホットコマンドは、様々な「ホットコマンド登録基準」に基づいてホットコマンドライブラリ内に選択的に登録され得る。1つのホットコマンド登録基準は、自動アシスタントの明示的な起動後に受信されたテキストコマンドがテキストコマンドのコーパス内の頻度しきい値を満たすことであり得る。このコーパスは、特定のユーザ(たとえば、話者)またはユーザの集団に関連付けられ得る。たとえば、特定のユーザが特定のコマンド「照明をオフにして」を発するために何らかのしきい値回数だけ自動アシスタントを起動させると仮定する。しきい値が満たされる前に、このコマンドが最初に明示的に起動されずに自動アシスタントによる応答アクションをトリガすることはできない。しかしながら、しきい値が満たされると(たとえば、ユーザが照明をオフにするために自動アシスタントを10回起動させると)、テキストコマンド「照明をオフにして」がホットコマンドライブラリ内に登録される。その後、最初に自動アシスタントを起動させずに、同じユーザによって同じコマンドが発せられるときはいつでも、自動アシスタントは、それでも、たとえば、同じ室内の照明をオフにすることによって、応答アクションを行う。
【0008】
特に自動アシスタントが明示的に起動された後でのみ音声認識処理が実行される、いくつかの実装形態では、ホットコマンドライブラリ内へのテキストコマンドの登録は、今後に向けてテキストコマンドを検出するように、前述のオンデバイス機械学習モデルをさらにトレーニングさせることができる。自動アシスタントが他の時点でキャプチャされた他の発話に対して音声認識処理を(オンボードで)実行する他の実装形態では、各発話から生成されたテキスト断片がホットコマンドライブラリ内に記憶されたテキスト断片と比較され得る。たとえば、所与のテキスト断片が、ホットコマンドライブラリ内の記録に十分類似する場合、かつ/またはその記録に意味的に矛盾しない場合、マッチが生じ得る。
【0009】
十分な類似性は、たとえば、テキスト断片と登録されたホットコマンドとの間に正確なマッチが存在する場合、もしくはテキスト断片と登録されたホットコマンドとの間の編集距離が何らかのしきい値を満たす(たとえば、何らかの編集距離未満である)場合、またはテキスト断片の埋込みがホットコマンドの埋込みの何らかのユークリッド距離内にあるときですら、見出され得る。いくつかの実装形態では、ホットコマンドライブラリは、前に登録されたテキストコマンドの埋込みのみを記憶し得る。たとえば、コマンドの対応するスロットが意味的に同様の値を受信し得る場合、2つのコマンド同士の間に意味的な無矛盾性が存在し得る。たとえば、「タイマーを10分に設定して」および「タイマーを1時間に設定して」は、意味的に矛盾しないが、これは、これらが共有するスロットが時間間隔であるためである。
【0010】
他の実装形態では、話された発話から生成されたテキスト断片は、ホットコマンドライブラリ内の登録以外の(または、それに加えた)要因に基づいて、ホットコマンドと見なされ得る。たとえば、いくつかの実装形態では、音声認識処理は、複数のテキスト断片を生成するために(たとえば、自動アシスタントの明示的な起動を必要とせずに)複数の発話に対して実行され得る。一方、1つまたは複数の視覚センサーは、分析されるとき、各発話中の話者の視線を明らかにする視覚データを生成し得る。特定のテキスト断片をもたらした特定の発話を話す間、話者が、自動アシスタントが少なくとも部分的に実装されているコンピューティングデバイスを見ていたとき、その特定のテキスト断片はホットコマンドと見なされ得る。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
横浜ゴム株式会社
音響材
今日
横浜ゴム株式会社
音響材
今日
横浜ゴム株式会社
音響材
今日
横浜ゴム株式会社
水中音響材
3日前
ヤマハ株式会社
ヘルムホルツ共鳴器
27日前
ブラザー工業株式会社
カラオケ装置
1か月前
ヤマハ株式会社
電子楽器
1か月前
ブラザー工業株式会社
カラオケ装置
1か月前
大和ハウス工業株式会社
音再現設備
7日前
日産自動車株式会社
防音構造体
21日前
セイコーエプソン株式会社
吸音ボード
21日前
岡山県
吸音構造
今日
株式会社第一興商
カラオケ装置
7日前
株式会社第一興商
カラオケ装置
27日前
コスモネクスト株式会社
入力支援プログラム及び入力支援方法
14日前
京セラ株式会社
音出力装置及び音出力方法
21日前
本田技研工業株式会社
能動型騒音低減装置
27日前
日本放送協会
音声認識装置およびプログラム
21日前
トヨタ自動車株式会社
制御装置及び制御方法
1か月前
本田技研工業株式会社
能動型騒音低減装置
21日前
株式会社アナザーウェア
鍵盤画面表示プログラム及びそのシステム
27日前
トヨタ自動車株式会社
異音診断システム
27日前
株式会社コルグ
音波生成装置、音波生成方法、プログラム
14日前
株式会社永セ仁
「パワハラ」等ハラスメント発言に係る職場環境測定システム
3日前
ソフトバンクグループ株式会社
行動制御システム
14日前
永楽電気株式会社
放送音声文字化システム及び放送設備における故障診断方法
21日前
本田技研工業株式会社
音声認識装置、音声認識方法、およびプログラム
6日前
ヤマハ株式会社
響板、その製造方法および響板を備える楽器
6日前
パイオニア株式会社
情報処理装置
8日前
東日本電信電話株式会社
演奏補助装置、演奏補助方法、及び、演奏補助プログラム
6日前
アルプスアルパイン株式会社
オーディオ信号処理装置及び遠隔制御システム
1か月前
ドーナッツロボティクス株式会社
音声処理システム、音声処理方法
14日前
ヤマハ株式会社
信号生成方法、表示制御方法およびプログラム
今日
三菱重工業株式会社
サイレンサ
27日前
ソフトバンクグループ株式会社
データ処理装置、データ処理方法、及びプログラム
21日前
国立研究開発法人情報通信研究機構
音声認識システム、音声認識方法およびプログラム
1か月前
続きを見る
他の特許を見る







 特許ウォッチ
特許ウォッチ