TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025015341
公報種別
公開特許公報(A)
公開日
2025-01-30
出願番号
2023118694
出願日
2023-07-20
発明の名称
音声認識装置およびプログラム
出願人
日本放送協会
代理人
個人
,
個人
,
個人
,
個人
主分類
G10L
15/16 20060101AFI20250123BHJP(楽器;音響)
要約
【課題】過去に発話されている文字(列)を繰り返し出力するという誤認識を軽減することのできる音声認識装置を提供する。
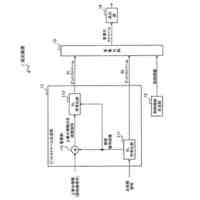
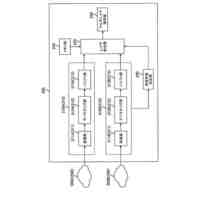
【解決手段】音声認識装置が、層構成のL個(Lは2以上の整数)のエンコーダー層を持ち、認識対象の音響特徴量の系列を入力し、認識対象の音響特徴量の系列に対応する認識結果を出力するストリーミングトランスフォーマーと、ストリーミングトランスフォーマーの第l番目(1≦l≦L-1)の層のエンコーダー層からの中間層信号を基に、認識結果を構成する記号についての確率分布情報を表す信号を生成し、中間層信号と記号についての確率分布情報を表す信号とを混合することによってストリーミングトランスフォーマーの第(l+1)番目の層のエンコーダー層への入力信号として供給する自己条件付きCTC処理部と、を備える。
【選択図】図1
特許請求の範囲
【請求項1】
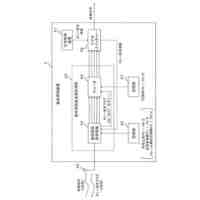
層構成のL個(Lは2以上の整数)のエンコーダー層を持ち、認識対象の音響特徴量の系列を入力し、且つ、前記認識対象の音響特徴量の系列よりも過去の音響特徴量に関する情報であるコンテキストエンベディングを入力し、前記認識対象の音響特徴量の系列に対応する認識結果を出力するストリーミングトランスフォーマーと、
前記ストリーミングトランスフォーマーの第l番目(1≦l≦L-1)の層の前記エンコーダー層からの中間層信号(h
l
out
)を基に、認識結果を構成する記号についての確率分布情報を表す信号を生成し、前記中間層信号と前記記号についての確率分布情報を表す信号とを混合することによって前記ストリーミングトランスフォーマーの第(l+1)番目の層の前記エンコーダー層への入力信号(h
l+1
in
)として供給する自己条件付きCTC処理部と、
を備える音声認識装置。
続きを表示(約 2,500 文字)
【請求項2】
学習用音響特徴量の系列と当該学習用音響特徴量の系列に対応する正解テキストとの対の集合である学習データを用いて、前記学習データの前記学習用音響特徴量の系列を前記ストリーミングトランスフォーマーに入力して、前記ストリーミングトランスフォーマーから出力される認識結果と前記学習データの前記正解テキストとの損失に基づいて、前記ストリーミングトランスフォーマーが持つ内部パラメーターの値と、前記自己条件付きCTC処理部が持つ内部パラメーターの値との最適化処理を可能とするよう構成された、
請求項1に記載の音声認識装置。
【請求項3】
前記認識対象の音響特徴量の系列は、N個(Nは正整数)の音響特徴量を含むブロックであり、
前記ストリーミングトランスフォーマーの第1番目の層の前記エンコーダー層は、前記ブロックを入力するとともに、当該ブロックよりも未来側のブロックに含まれるN
ahead
個(N
ahead
は正整数)の音響特徴量を先読みして入力し、
前記ストリーミングトランスフォーマーの第(l+1)番目の層の前記エンコーダー層は、前記自己条件付きCTC処理部から渡される認識対象である当該ブロックの信号を入力するとともに、当該ブロックよりも未来側のブロックに基づいて前記自己条件付きCTC処理部から渡される信号を先読みして入力する、
請求項1に記載の音声認識装置。
【請求項4】
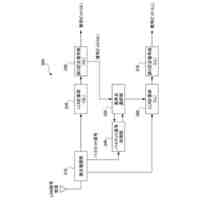
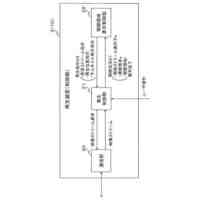
前記自己条件付きCTC処理部は、
前記ストリーミングトランスフォーマーの第l番目(1≦l≦L-1)の層の前記エンコーダー層からの中間層信号(h
l
out
)のレイヤー正規化の処理を行うレイヤー正規化層と、
前記レイヤー正規化層からの出力を線形変換してソフトマックス処理することにより前記確率分布情報(z
l
)を出力するソフトマックス層と、
前記レイヤー正規化層からの出力(z
l
norm
)と前記ソフトマックス層からの出力(z
l
)とを混合して、前記ストリーミングトランスフォーマーの第(l+1)番目の層の前記エンコーダー層への入力信号(h
l+1
in
)を出力する混合部と、
を備える、
請求項1に記載の音声認識装置。
【請求項5】
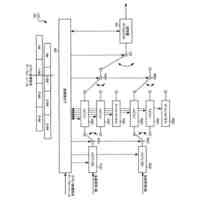
前記自己条件付きCTC処理部は、
前記ストリーミングトランスフォーマーの第l番目(1≦l≦L-1)の層の前記エンコーダー層からの中間層信号(h
l
out
)のレイヤー正規化の処理を行うレイヤー正規化層と、
前記レイヤー正規化層からの出力を線形変換してソフトマックス処理することにより前記確率分布情報を出力するソフトマックス層と、
前記ソフトマックス層からの出力(z
l
)を入力して、リカレントニューラルネットワークによる処理の結果である信号(z
l
rnn
)を出力するリカレントニューラルネットワーク層と、
前記レイヤー正規化層からの出力(z
l
norm
)と前記リカレントニューラルネットワーク層からの出力(z
l
rnn
)とを混合して、前記ストリーミングトランスフォーマーの第(l+1)番目の層の前記エンコーダー層への入力信号(h
l+1
in
)を出力する混合部と、
を備え、
前記リカレントニューラルネットワーク層は、前記リカレントニューラルネットワーク層による前のブロックの信号の処理の結果として得られる潜在ベクトルにも基づいてリカレントニューラルネットワークによる処理を行うとともに、処理対象のブロックの信号の処理の結果として得られる潜在ベクトルを次のブロックの処理のために記憶する、
請求項1に記載の音声認識装置。
【請求項6】
前記混合部は、
前記レイヤー正規化層からの出力(z
l
norm
)と前記リカレントニューラルネットワーク層からの出力(z
l
rnn
)とを連結して線形変換処理を行うことによって1次元の係数(α)を算出し、当該係数(α)を重みとして作用させることによって前記レイヤー正規化層からの出力(z
l
norm
)と前記リカレントニューラルネットワーク層からの出力(z
l
rnn
)とを混合して、前記ストリーミングトランスフォーマーの第(l+1)番目の層の前記エンコーダー層への入力信号(h
l+1
in
)を出力する、
請求項5に記載の音声認識装置。
【請求項7】
層構成のL個(Lは2以上の整数)のエンコーダー層を持ち、認識対象の音響特徴量の系列を入力し、且つ、前記認識対象の音響特徴量の系列よりも過去の音響特徴量に関する情報であるコンテキストエンベディングを入力し、前記認識対象の音響特徴量の系列に対応する認識結果を出力するストリーミングトランスフォーマーと、
前記ストリーミングトランスフォーマーの第l番目(1≦l≦L-1)の層の前記エンコーダー層からの中間層信号(h
l
out
)を基に、認識結果を構成する記号についての確率分布情報を表す信号を生成し、前記中間層信号と前記記号についての確率分布情報を表す信号とを混合することによって前記ストリーミングトランスフォーマーの第(l+1)番目の層の前記エンコーダー層への入力信号(h
l+1
in
)として供給する自己条件付きCTC処理部と、
を備える音声認識装置、としてコンピューターを機能させるプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識装置およびプログラム
に関する。
続きを表示(約 2,300 文字)
【背景技術】
【0002】
リアルタイムに認識結果を出力する音声認識の処理の方式としては、2種類の方式が存在する。第1の方式は、1つずつ音響特徴を入力して認識結果を出力する方式である。第2の方式は、複数の音響特徴をまとめて1つのブロックとして、ブロック単位の音響特徴を入力して認識結果を出力する方式である。近年、ブロックごとに処理する音声認識技術であるStreaming transformer(ストリーミングトランスフォーマー)が提案された。Streaming transformerの手法では、過去に出力した認識結果を再度モデルに入力することにより、過去に出力した言語情報もふまえながら認識結果を出力することができる。また、Streaming transformerにおいては、過去に処理したブロックの音響的な情報を引き継ぐcontext embedding(コンテキストエンベディング)の手法を導入するなどすることによって、高い認識性能を達成している。
【0003】
非特許文献1には、Streaming transformerの技術が記載されている。
【0004】
非特許文献2には、エンコーダーにおいてコンテキストを引き継ぐ機構が記載されている(Fig.2等)。
【0005】
非特許文献3には、CTCベースの音声認識の技術が記載されている。
【先行技術文献】
【非特許文献】
【0006】
Emiru Tsunoo,Yosuke Kashiwagi,Shinji Watanabe,“Streaming Transformer ASR with Blockwise Synchronous Beam Search”,In Proc. IEEE Spoken Language Technology Workshop (SLT),2021年.
Emiru Tsunoo,Yosuke Kashiwagi,Toshiyuki Kumakura,Shinji Watanabe,“Transformer ASR with Contextual Block Processing”,In Proc. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU),2019年.
Jumon Nozaki,Tatsuya Komatsu,“Relaxing the Conditional Independence Assumption of CTC-based ASR by Conditioning on Intermediate Predictions”,In Proc. INTERSPEECH,pp. 3735-3739,2021年.
【発明の概要】
【発明が解決しようとする課題】
【0007】
しかしながら、Streaming transformerの技術には過去に発話された文字を再度出力してしまうという問題があり、この問題は結果として誤認識につながる。
【0008】
Streaming transformerの手法が誤認識を起こす理由は次のとおりである。つまり、Streaming transformerの手法においては、デコーダーと呼ばれるニューラルネットワークが、エンコードされた情報を参照し、新たな認識結果が出力されなくなるまで認識結果を出力し続ける。この手法においては、発話の終わりを表す特殊記号や1つ前に出力した文字が繰り返し出力された場合に、認識結果の出力処理を終了する。この手法の欠点として、例えば、2文字の列の繰り返しなどといった繰り返しのパターンによって終了条件を満たさない場合があり、その場合には同じパターンの認識結果を繰り返し出力してしまうことが挙げられる。このような理由によって、Streaming transformerの手法における認識精度が低下してしまう。
【0009】
ここでStreaming transformerの技術を用いる場合の誤認識の例を説明する。
【0010】
正解文は次のとおりである。「二 % 達 成 へ 向 け た 道 筋 と い う こ と に つ い て は 二 % 達 成 の メ カ ニ ズ ム と い う 面 で は で す ね 従 来 か ら 申 し 上 げ て い た よ う に 一 方 で で す ね 実 質 金 利 の 引 き 下 げ に よ っ て *** *** *** 景 気 を 刺 激 し で す ね 失 業 率 を 引 き 下 げ る あ る い は G D P ギ ャ ッ プ を 縮 小 す る と い う こ と を 通 じ て 賃 金 や 物 価 が 上 昇 し て い く と い う *** メ カ ニ ズ ム は 基 本 的 に 変 わ っ て お り ま せ ん」。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
日本放送協会
配線構造
2か月前
日本放送協会
撮像装置
6か月前
日本放送協会
光学計測装置
4か月前
日本放送協会
無線通信装置
4か月前
日本放送協会
マイクロホン
4か月前
日本放送協会
液晶表示装置
11か月前
日本放送協会
磁性細線メモリ
3か月前
日本放送協会
光制御デバイス
11か月前
日本放送協会
レンズアダプター
8か月前
日本放送協会
映像伝送システム
2か月前
日本放送協会
磁性細線デバイス
6か月前
日本放送協会
無線伝送システム
6か月前
日本放送協会
3次元映像表示装置
3か月前
日本放送協会
データ管理システム
6か月前
日本放送協会
良撮影位置推定装置
1か月前
日本放送協会
垂直分離型撮像素子
10か月前
日本放送協会
角度選択フィルター
1か月前
日本放送協会
受信装置及び送出装置
7か月前
日本放送協会
送信装置及び受信装置
9か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
同軸切替器の着脱機構
10か月前
日本放送協会
送出装置及び受信装置
12か月前
日本放送協会
送信装置及び受信装置
8か月前
日本放送協会
送信装置及び受信装置
12か月前
日本放送協会
撮像素子及び撮像装置
11か月前
日本放送協会
衛星放送受信システム
8か月前
日本放送協会
送信装置及び受信装置
6か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
11か月前
日本放送協会
端末装置及びプログラム
7か月前
日本放送協会
縮小装置及びプログラム
10日前
日本放送協会
受信装置及びプログラム
8か月前
日本放送協会
磁壁移動型空間光変調器
7か月前
日本放送協会
受信装置及びプログラム
1か月前
日本放送協会
再生装置及びプログラム
10か月前
日本放送協会
伸縮性を有する半導体装置
8か月前
続きを見る
他の特許を見る










 特許ウォッチ
特許ウォッチ