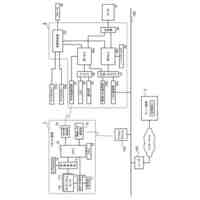
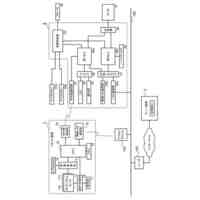
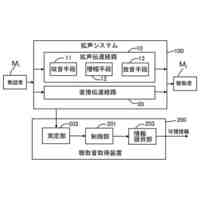
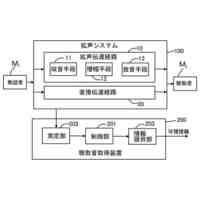
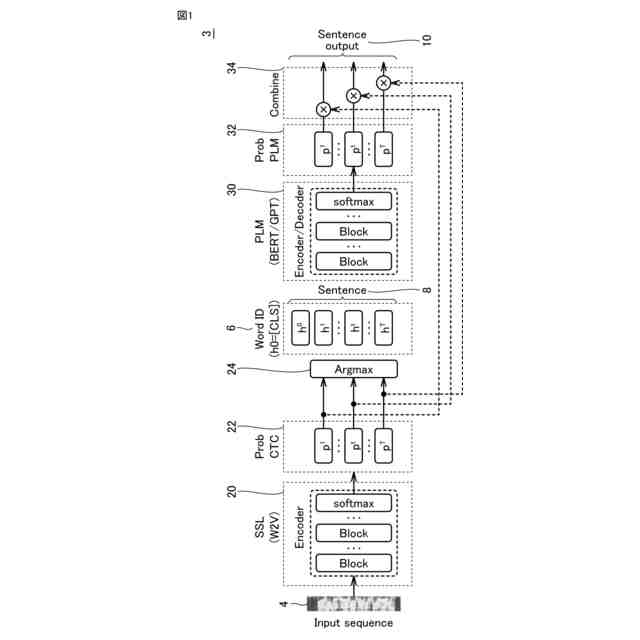
発明の詳細な説明【技術分野】 【0001】 本発明は、音声認識システム、音声認識方法およびプログラムに関する。 続きを表示(約 1,700 文字)【背景技術】 【0002】 ASR(Automatic Speech Recognition)のアプリケーションの一例として、大規模に学習された大規模言語モデルを含む音声認識を行うシステムが公知である。大規模言語モデルとして、代表的には、エンコーダベースのモデルと、デコーダベースのモデルとが存在する。 【0003】 エンコーダベースのモデルとして、例えば、BERT(非特許文献1など参照)やTransformerの双方向エンコーダ(非特許文献2など参照)などが知られている。デコーダベースのモデルとして、例えば、GPT-2(非特許文献3など参照)や、一方向性Transformerデコーダ)などが知られている。 【0004】 大規模言語モデルは、主として、エラー訂正、モデル圧縮、再スコアリング、マルチモーダルアプリケーションなどに用いることもできる。 【先行技術文献】 【非特許文献】 【0005】 J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "Bert: Pre-training of deep bidirectional transformers for language understanding," arXiv preprint arXiv:1810.04805, 2018. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, Attention is all you need, Proc. NeurlPS 30 (2017). A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., "Language models are unsupervised multitask learners," OpenAI blog, vol. 1, no. 8, p. 9, 2019. 【発明の概要】 【発明が解決しようとする課題】 【0006】 上述したような大規模言語モデルは、ベクトルのシーケンスの入力に対して対応するベクトルのシーケンスを出力するように設計されている。このようなシーケンス・トゥ・シーケンスの設計を前提として、センテンス単位(文単位)で処理する、大規模言語モデルを含む音声認識システムが提案されている。 【0007】 本発明は、大規模言語モデルを利用して、より推論精度の高い音声認識システムを提供することを目的とする。 【課題を解決するための手段】 【0008】 ある実施の形態に従う音声認識システムは、音声信号に含まれる単語に対応するトークンをトークン単位で出力することのできる第1の学習済み推論モデルと、1または複数のトークンの入力に基づく推論によって、対応する1または複数のトークンを出力する第2の学習済み推論モデルと、第1の学習済み推論モデルの第1推論出力と、第2の学習済み推論モデルの出力であって、第1推論出力に対応する第2推論出力とを単語単位で乗算する乗算器とを含む。乗算器の出力である新たな確率分布に基づき選択した単語が、第2の学習済み推論モデルに入力される。 【0009】 乗算器の出力は、音声認識システムの認識出力として利用されてもよい。 第2の学習済み推論モデルは、音声認識の対象言語のコーパスを用いて、少なくとも入力シーケンスに対する次の単語を予測するタスクを事前学習済みであってもよい。 【0010】 第2の学習済み推論モデルは、対象言語の方言データを用いてファインチューニングされていてもよい。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する

 特許ウォッチ
特許ウォッチ