TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2024132588
公報種別
公開特許公報(A)
公開日
2024-10-01
出願番号
2023043422
出願日
2023-03-17
発明の名称
音声合成装置、予測装置、音声合成システム、音声合成方法及びプログラム
出願人
国立大学法人 東京大学
代理人
個人
,
個人
,
個人
,
個人
主分類
G10L
13/08 20130101AFI20240920BHJP(楽器;音響)
要約
【課題】非流暢性を含む合成音声の人間らしさを向上すること。
【解決手段】音声合成装置は、フィラー部分を含む第1のテキストに関する情報を取得する取得部と、前記第1のテキストに含まれる第1の言語部分に対応する音声と前記フィラー部分を含まない第2のテキストに含まれる第2の言語部分に対応する音声との一貫性が保証されるように学習される音声合成モデルに基づいて、前記第1のテキストに対応する音声を合成する音声合成部と、を備える。
【選択図】図5
特許請求の範囲
【請求項1】
フィラー部分を含む第1のテキストに関する情報を取得する取得部と、
前記第1のテキストに含まれる第1の言語部分に対応する音声と前記フィラー部分を含まない第2のテキストに含まれる第2の言語部分に対応する音声との一貫性が保証されるように学習される音声合成モデルに基づいて、前記第1のテキストに対応する音声を合成する音声合成部と、
を備える音声合成装置。
続きを表示(約 1,600 文字)
【請求項2】
前記第1の言語部分に対応する音声と、前記第2の言語部分に対応する音声との間の一貫性を保証する損失を用いて、前記音声合成モデルの学習を行う学習部、
を更に備える請求項1記載の音声合成装置。
【請求項3】
前記学習部は、真のフィラー部分を含む第3のテキストに含まれる第3の言語部分に関する第1の損失と、疑似フィラー部分を含む第4のテキストに含まれる第4の言語部分に関する第2の損失と、を算出し、前記第1の損失と前記第2の損失とに基づいて前記一貫性を保証する前記損失を算出する、
を更に備える請求項2記載の音声合成装置。
【請求項4】
前記音声合成モデルは、前記第3のテキストと前記第3のテキストに対応する音声とのペアを用いて事前学習されたモデルを教師モデルとする生徒モデルであり、
前記学習部は、前記真のフィラー部分と第3の言語部分とを含む前記第3のテキストに関する情報を前記生徒モデルに入力して得られる前記第3の言語部分の中間表現と、前記第3の言語部分に関する情報を前記教師モデルに入力して得られる中間表現と、の間の距離に基づいて、前記第1の損失を算出する、
請求項3記載の音声合成装置。
【請求項5】
前記学習部は、前記疑似フィラー部分と第4の言語部分とを含む前記第4のテキストに関する情報を前記生徒モデルに入力して得られる前記第4の言語部分の中間表現と、前記第4の言語部分に関する情報を前記教師モデルに入力して得られる中間表現と、の間の距離に基づいて、前記第2の損失を算出する、
請求項4記載の音声合成装置。
【請求項6】
話者又は前記話者が属するグループに依存する予測モデルを用いて、前記第4のテキスト内の前記疑似フィラー部分の位置及びワードを予測する予測部
を更に備える請求項5記載の音声合成装置。
【請求項7】
フィラー部分を含まない第2のテキストに関する情報を取得する取得部と、
話者又は前記話者が属するグループに依存する予測モデルに基づいて、前記第2のテキストに対して挿入される前記フィラー部分の位置及びワードを予測する予測部と、
予測された前記位置及び前記ワードのフィラー部分を含む第1のテキストに関する情報を出力する出力部と、
を備える予測装置。
【請求項8】
複数の話者の話者データに含まれる前記フィラー部分の位置及びワードの少なくとも一つに基づいて前記複数の話者を複数のグループにグループ化するグループ化部と、
前記複数のグループそれぞれに対応する複数の予測モデルを記憶する記憶部と、
前記複数の予測モデルの中から、前記フィラー部分の位置及びワードの少なくとも一つに関する前記話者の傾向に基づいて前記話者が属するグループの前記予測モデルを選択する選択部、
を更に備える請求項7に記載の予測装置。
【請求項9】
請求項1から請求項6のいずれか記載の音声合成装置と、請求項7又は請求項8記載の予測装置と、を含む音声合成システムであって、
前記音声合成装置の前記取得部は、前記予測装置の前記出力部から出力された前記フィラー部分を含む前記第1のテキストに関する情報を取得する、
音声合成システム。
【請求項10】
音声合成装置が、
フィラー部分を含む第1のテキストに関する情報を取得する工程と、
前記第1のテキストに含まれる第1の言語部分に対応する音声と前記フィラー部分を含まない第2のテキストに含まれる第2の言語部分に対応する音声との一貫性が保証されるように学習される音声合成モデルに基づいて、前記第1のテキストに対応する音声を合成する工程と、
を有する音声合成方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声合成装置、予測装置、音声合成システム、音声合成方法及びプログラムに関する。
続きを表示(約 2,500 文字)
【背景技術】
【0002】
従来、テキストから人間のような自然な音声を人工的に合成するテキスト音声合成(TTS)が知られている(例えば、非特許文献1)。深層学習を用いたTTSの発展により、読み上げ音声については、人間に近い自然な音声の合成が可能となっている(例えば、非特許文献2)。また、非個人性化(Non-personalized)モデルを用いて、流暢なテキストから非流暢性(disfluency)(例えば、フィラー)を含むテキストを生成する技術も知られている(例えば、非特許文献3)。
【先行技術文献】
【非特許文献】
【0003】
Y. Sagisaka, “Speech synthesis by rule using an optimal selection of non-uniform synthesis units,” in Proc. ICASSP, Apr. 1988, pp. 679-682.
J. Shen et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” in Proc. ICASSP, Apr. 2018, pp. 4779-4783.
Yamazaki et al., “Filter prediction based on bidirectional lstm for generation of natural response of spoken dialog” in Proc. GCCE, pages 360-361.
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、以上の従来技術では、非流暢性を含む合成音声(例えば、フィラーを含む自発音声等)の人間らしさを実現するには至っていない。例えば、上記非特許文献3により生成された非流暢性を含むテキストから音声を合成しても、非流暢性の個人性の欠如する結果、非流暢性を含む合成音声の人間らしさを十分に実現できない恐れがある。また、非流暢性を含むテキストから音声を合成する場合、当該テキスト内の言語部分の合成音声の品質が低下する結果、非流暢性を含む合成音声の人間らしさを十分に実現できない恐れがある。
【0005】
そこで、本開示は、非流暢性を含む合成音声の人間らしさを向上可能な音声合成装置、予測装置、音声合成システム、音声合成方法及びプログラムを提供することを目的の一つとする。
【課題を解決するための手段】
【0006】
本開示の一態様に係る音声合成装置は、フィラー部分を含む第1のテキストに関する情報を取得する取得部と、前記第1のテキストに含まれる第1の言語部分に対応する音声と前記フィラー部分を含まない第2のテキストに含まれる第2の言語部分に対応する音声との一貫性が保証されるように学習される音声合成モデルに基づいて、前記第1のテキストに対応する音声を合成する音声合成部と、を備える。
【0007】
本開示の一態様に係る予測装置は、フィラー部分を含まない第2のテキストに関する情報を取得する取得部と、話者又は前記話者が属するグループに依存する予測モデルに基づいて、前記第2のテキストに対して挿入される前記フィラー部分の位置及びワードを予測する予測部と、予測された前記位置及び前記ワードのフィラー部分を含む第1のテキストに関する情報を出力する出力部と、を備える。
【0008】
本開示の一態様に係る音声合成システムは、前記フィラー部分を含まない第2のテキストに関する情報を取得する取得部と、話者又は前記話者が属するグループに依存する予測モデルに基づいて、前記第2のテキストに対して挿入される前記フィラー部分の位置及びワードを予測する予測部と、予測された前記位置及び前記ワードのフィラー部分を含む前記第1のテキストに関する情報を出力する出力部と、を備える予測装置と、前記第1のテキストに関する情報を取得する取得部と、前記第1のテキストに含まれる第1の言語部分に対応する音声と前記フィラー部分を含まない第2のテキストに含まれる第2の言語部分に対応する音声との一貫性が保証されるように学習される音声合成モデルに基づいて、前記第1のテキストに対応する音声を合成する音声合成部と、を備える音声合成装置と、を備える。
【発明の効果】
【0009】
本開示の一態様によれば、非流暢性を含む合成音声の人間らしさを向上できる。
【図面の簡単な説明】
【0010】
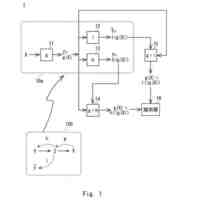
本実施形態に係る自発音声合成モデルの概要を示す図である。
本実施形態に係る予測モデル1の概念図である。
本実施形態に係るグループに依存する予測モデル1の一例を示す図である。
本実施形態に係るグループ化の一例を示す図である。
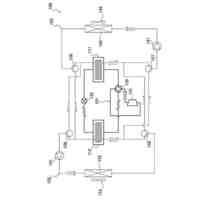
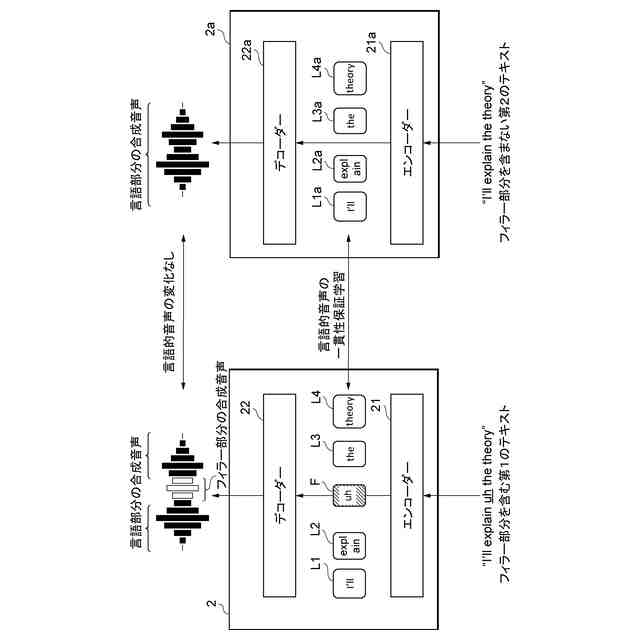
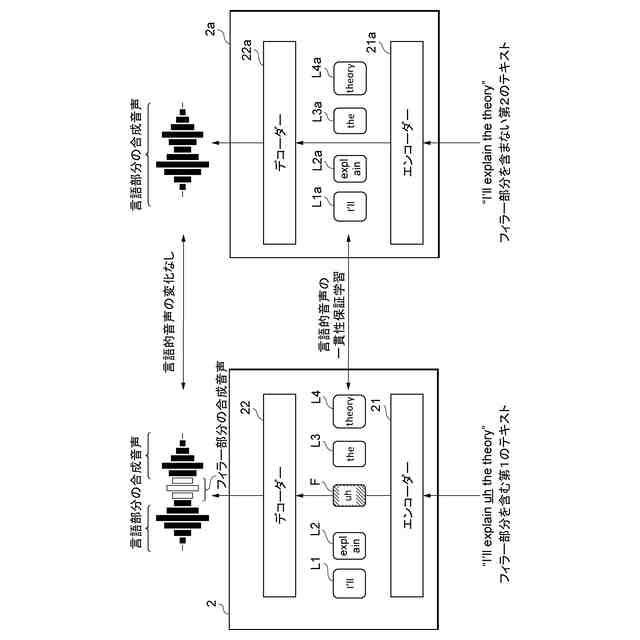
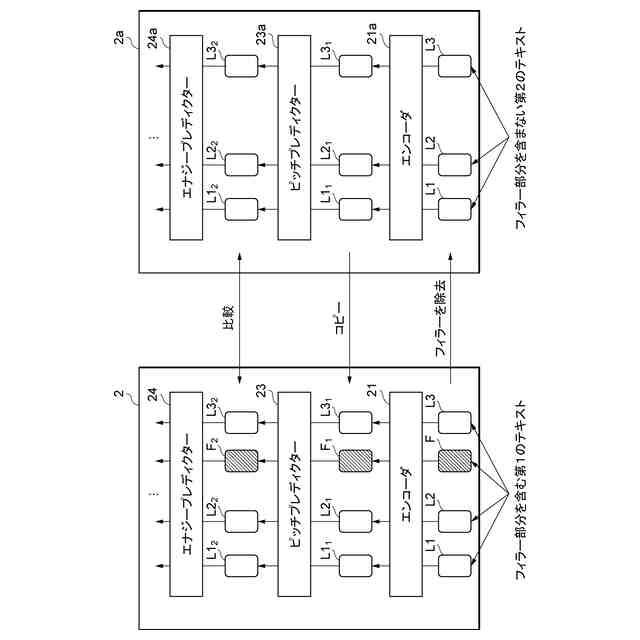
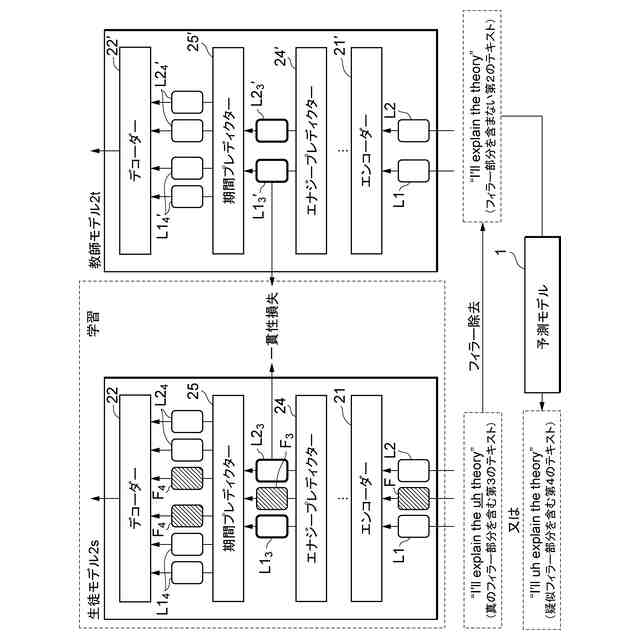
本実施形態に係る音声合成モデル2の一例を示す図である。
本実施形態に係る音声合成モデル2の品質改善に向けた事前調査の一例を示す図である。
本実施形態に係る音声合成モデル2の一貫性保証学習の一例を示す図である。
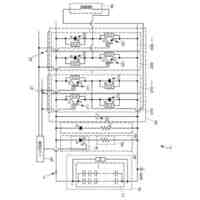
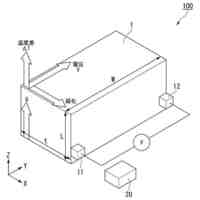
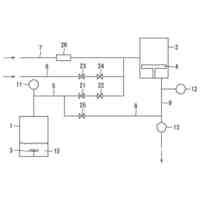
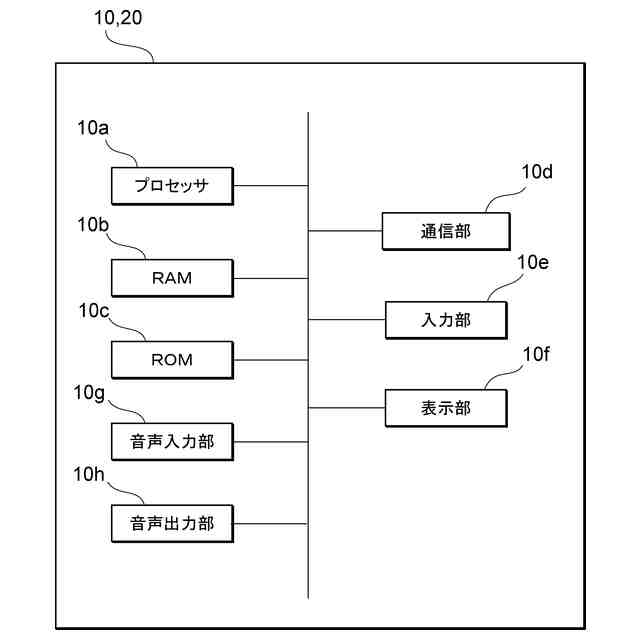
本実施形態に係る音声合成システムを構成する装置の物理構成の一例を示す図である。
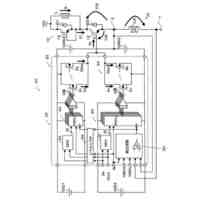
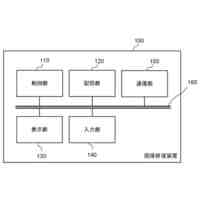
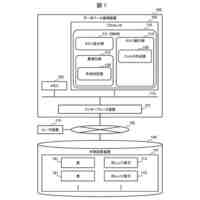
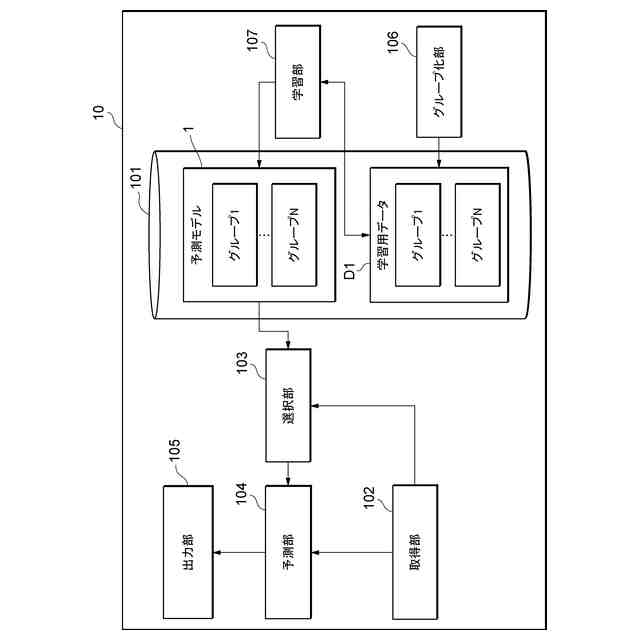
本実施形態に係る予測装置10の機能構成の一例を示す図である。
本実施形態に係る音声合成装置20の機能構成の一例を示す図である。
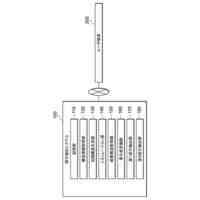
本実施形態に係るグループ依存の予測モデル1を用いた予測装置10及び従来例に係る装置による予測精度の評価の結果を示す図である。
本実施形態に係る音声合成モデル2を用いた音声合成装置20及び従来例に係る装置による合成音声の評価の結果を示す図である。
本実施形態に係る音声合成システムの動作の一例を示すフローチャートである。
【発明を実施するための形態】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
国立大学法人 東京大学
磁場発生装置
1か月前
国立大学法人 東京大学
ゲート駆動装置
1か月前
国立大学法人 東京大学
半導体レーザ装置
2か月前
国立大学法人 東京大学
冷却試料ステージ装置
17日前
国立大学法人 東京大学
測定装置及び測定方法
2か月前
国立大学法人 東京大学
魚類の生殖腺発育促進剤
2か月前
国立大学法人 東京大学
気泡による情報表示媒体
1か月前
国立大学法人 東京大学
バレット食道の治療用組成物
17日前
株式会社デンソー
蓄放熱材料
1か月前
国立大学法人 東京大学
ゲノムへのランダム変異導入法
2か月前
株式会社小松製作所
熱交換器
16日前
国立大学法人 東京大学
タンパク質送達用pH応答性担体
1か月前
国立大学法人 東京大学
pH応答性タンパク質送達用担体
1か月前
国立大学法人 東京大学
多系統萎縮症治療用の医薬組成物
1か月前
国立大学法人 東京大学
学習方法、学習装置、及びプログラム
1か月前
国立大学法人 東京大学
熱電変換モジュールおよび熱流センサ
24日前
日本特殊陶業株式会社
超音波発生装置
2か月前
国立大学法人 東京大学
プログラム、画像修復装置及び画像修復方法
9日前
国立大学法人 東京大学
ニオブシリサイド基合金およびその製造方法
2か月前
ダイキン工業株式会社
熱交換器及び冷凍装置
1か月前
ローム株式会社
制御回路及び非接触給電装置
2か月前
国立大学法人信州大学
放射性廃液の処理方法および放射性物質捕捉剤
1か月前
ダイキン工業株式会社
フッ素原子含有化合物
2か月前
国立大学法人 東京大学
凝集誘起増強型ラマンプローブ又は蛍光プローブ
2か月前
国立大学法人 東京大学
情報処理システム、情報処理方法及びプログラム
2か月前
国立大学法人 東京大学
電磁波吸収体、及び電磁波吸収体形成用ペースト
1か月前
住友金属鉱山株式会社
二酸化炭素の固定化方法
16日前
ダイキン工業株式会社
電力システム及び電気機器
1か月前
国立大学法人 東京大学
グルコース経路活性化による膵島細胞の増殖活性化
2日前
国立大学法人 東京大学
情報処理システム、情報処理方法およびプログラム
2か月前
国立大学法人 東京大学
極性基含有オレフィン共重合体、及びその製造方法
3日前
ダイキン工業株式会社
原子層堆積法による成膜方法
2か月前
国立大学法人 東京大学
超音波デバイス、制御装置、プログラム及びシステム
1か月前
株式会社日立製作所
データベース管理装置及び方法
2か月前
国立大学法人 東京大学
因子抽出システム、因子抽出方法、因子抽出プログラム
2か月前
株式会社HanaVax
外来性遺伝子発現組換えイネ
1か月前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ