TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024127694
公報種別
公開特許公報(A)
公開日
2024-09-20
出願番号
2023109794
出願日
2023-07-04
発明の名称
海洋栄養成分の生合成経路のマイニング方法、装置、機器及び媒体
出願人
中国海洋大学
代理人
個人
,
個人
主分類
G16B
30/00 20190101AFI20240912BHJP(特定の用途分野に特に適合した情報通信技術)
要約
【課題】海洋栄養成分の生合成経路のマイニング方法、装置、機器及び媒体を提供する。
【解決手段】方法は、タンパク質コード領域の予測、目的機能性酵素の同定及び酵素活性の予測と分析という3つの重要な工程を含む。
【効果】DNA三次元構造情報、基質化学特徴情報及びタンパク質三次元構造情報を融合し、モデルの正確性を向上させ、配列決定によって得られたメタプロテオミクスデータと、同定された陽性サンプルとを比較してスクリーニングすることにより、偽陽性確率を大幅に低減し、酵素活性の正確な予測を実現するとともに、重要なアミノ酸残基を逆識別する。
【選択図】図1
特許請求の範囲
【請求項1】
潜在的なゲノムデータに対してDNA形状特徴を融合したタンパク質コード領域を予測する第1工程と、
目的機能性酵素を同定し、アミノ酸配列と特定の基質との親和性を予測することにより、目的機能性酵素の同定を実現する第2工程であって、第2工程の具体的な方法は、
(1)ELECTRAモデルを事前トレーニングし、まずPubChemデータベースから化合物の複合SMILES文字列を抽出し、UniProtデータベースからタンパク質のFASTA配列を抽出し、それぞれ2つのTransformerエンコーダに入力し、一方は生成器ネットワークとして、他方は識別器ネットワークとして機能し、ELECTRA-MモデルとELECTRA-Pモデルをそれぞれ得るステップと、
(2)BRENDAから収集した基質情報とタンパク質配列情報をトレーニングされたELECTRA-MモデルとELECTRA-Pモデルに入力し、特徴テンソルマトリクスを得て、CNNとFCNNを組み合わせてミカエリス定数を予測するステップと、
(3)FCNNを用いてミカエリス定数の値を予測するステップと、を含む第2工程と、
第2工程において同定された陽性同定結果と生物実験配列決定によって得られたメタプロテオミクスデータとを比較してスクリーニングし、タンパク質をコードするポテンシャルを有する陽性同定サンプルを得て、従来技術を利用してタンパク質配列をpdbフォーマットファイルに変換し、即ち、その三次元構造を予測して分子動力学シミュレーションと分析を行う第3工程と、
候補サンプルを選択してランキングするように、それに対して分子動力学と深層学習を組み合わせた予測モデルに基づく酵素活性の予測分析を行う第4工程とを含む、
ことを特徴とする海洋栄養成分の生合成経路のマイニング方法。
続きを表示(約 1,800 文字)
【請求項2】
前記第1工程において、まず、タンパク質コード領域の予測関連データセットを構築し、NCBI reference sequencesから関連種のゲノムと転写データセットを構築し、全ての生物学的配列からサンプルを選択し、かつサンプルをネガティブサンプルとしてランダムにシャッフルし、ネガティブサンプルの数をポジティブサンプルの数に等しくし、全てのサンプルを3つの部分に分割して3分割の交差検証を行い、テストデータから配列類似度が50%を超えるサンプルを除去することにより、テストデータのうちの各サンプルと、トレーニングデータのうちの任意のサンプルとの同一性が50%を超えないことを保証し、次に、深層学習モデルを用いてDNA形状情報を融合した配列特徴の抽出を実現し、次に、タンパク質コード領域をラベリングし、各スライドウィンドウの特徴コードベクトルを与えた後、深層学習モデルを構築することにより、配列構造特徴、グローバル配列順序情報、重複しないkmer特徴及びタグ依存関係を統合し、生物学的配列における各位置について、現在の部分列及びその隣接する部分列をDNA形状情報、C4及びgkmにコードし、さらにDNA形状情報及びC2をCNNにコードしてgkmに合併し、最後に双方向リカレントニューラルネットワークに供給してタンパク質コード領域を予測し、予測されたタンパク質コード領域の配列をアミノ酸配列に変換する、
ことを特徴とする請求項1に記載の海洋栄養成分の生合成経路のマイニング方法。
【請求項3】
第4工程において、まず、分子動力学と深層学習に基づく酵素活性予測モデルのトレーニングとテストのデータセットを構築し、分子動力学ソフトウェアを用いて分子動力学シミュレーションを行い、分子動力学シミュレーション後に20psの間隔で各200ns軌跡からスナップショットを後続のDL分析の立体配座データセットとして抽出し、次に、分子動力学シミュレーション立体配座の画素表現を取得し、画素マップを用いてデータセットにおける各立体配座を示し、即ち、マトリクス変換により各立体配座のXYZ座標をRGB座標に変換し、最後に、解釈可能な深層学習アルゴリズムモデルを構築し、酵素活性を予測するとともに、機能する重要なアミノ酸残基を識別することにより、後続の生物学者がウェット実験検証を行う、
ことを特徴とする請求項1に記載の海洋栄養成分の生合成経路のマイニング方法。
【請求項4】
第2工程において、第1工程において同定されたタンパク質配列と目的基質との間のミカエリス定数を予測することにより目的機能性酵素の同定を実現し、第2工程におけるステップ(3)において、過学習を防止するために、各隠れ層の後にバッチ正規化を適用し、かつ各層にL2正則化を使用する、
ことを特徴とする請求項3に記載の海洋栄養成分の生合成経路のマイニング方法。
【請求項5】
タンパク質コード領域の予測モジュールと、目的機能性酵素の同定モジュールと、比較スクリーニング及び活性評価モジュールとを含み、
前記タンパク質コード領域の予測モジュールは、請求項1に記載の海洋栄養成分の生合成経路のマイニング方法における前記第1工程の方法を実行し、
前記目的機能性酵素の同定モジュールは、請求項1に記載の海洋栄養成分の生合成経路のマイニング方法における第2工程の方法を実行し、
前記比較スクリーニング及び活性評価モジュールは、請求項1に記載の海洋栄養成分の生合成経路のマイニング方法における前記第3工程及び第4工程の方法を実行する、
ことを特徴とする海洋栄養成分の生合成経路のマイニング装置。
【請求項6】
コンピュータプログラムが記憶されているメモリと、プロセッサとを含み、前記コンピュータプログラムは、前記プロセッサによって実行されると、前記プロセッサに請求項1に記載の海洋栄養成分の生合成経路のマイニング方法の工程を実行させる、
ことを特徴とするコンピュータ機器。
【請求項7】
プロセッサによってロードされると、請求項1に記載の海洋栄養成分の生合成経路のマイニング方法を実行するコンピュータプログラムが記憶されている、
ことを特徴とするコンピュータ読み取り可能な記憶媒体。
発明の詳細な説明
【技術分野】
【0001】
本発明は、生物情報学の分野に属し、具体的には、海洋栄養成分の生合成経路のマイニング方法、装置、機器及び媒体に関する。
続きを表示(約 3,800 文字)
【背景技術】
【0002】
従来技術において、ゲノム配列にわたる特定の代謝酵素をコードする遺伝子セットを自動的に識別する一連の計算方法が開発されている。多くの方法は、最初に細菌(場合によっては真菌と植物)に対して開発されたが、利用された原理は、他の生物種に拡張することができる。これらの方法は、それぞれ異なる分類群を対象として、かつそれらを新たな分類空間に拡張するのに必要な条件も異なる。
【0003】
方法ポリシーの観点から見ると、従来の主流な方法は、ある種の活性化合物に関連する生合成遺伝子クラスター(biosynthetic gene clusters、BGCs)を識別することが多い。BGCsにおける酵素をコードする遺伝子の物理的クラスタリングは、生合成経路の識別を大きく促進する。BGCは、遺伝子含有量が大きく変化し、かつその迅速な進化及び頻繁な遺伝子レベルの転移により、一般的に菌株特異性を有するが、それらは、一般的に酵素ファミリー形式の共通特性を確実に有し、これらの酵素ファミリーは、特定の種類の代謝産物の生合成全体にとって重要な生化学反応の触媒を担う。この特性により、ゲノムにおけるBGCを大幅かつ自動的に識別することを可能にしている。antiSMASH、PRISMなどの広く使用されているソフトウェアツールは、タンパク質ドメインの輪郭隠れマルコフモデル(pHMMs)を用いて、特定の経路タイプの特徴を有する酵素ファミリーをコードする遺伝子組み合わせを識別する。これらの2つのツールによって得られる結果は、一般的に非常に類似しているが、antiSMASHの開発は、機能及び比較分析に重点を置いているのに対し、PRISMは、化学構造の組み合わせ予測に特に使用され、質量スペクトルデータとの自動マッチングに使用することができる。pHMMsの使用は、多くの成熟したタイプの生合成メカニズムをコードするBGC(例えば、ポリケタイド合成酵素、NRPSs及び既知のタイプのリボソームを合成して翻訳した後に修飾されたペプチド(ribosomally synthesized and post translation ally modified peptides、RiPPs))を識別するのに非常に信頼できるが、あまり研究されず、全く新しいタイプのBGCを無視するリスクがある。確率ベースのBGC予測方法(例えば、Cluster Finder(anti SMASHにも集積)とDeepBGC)又はゲノム間の代謝に関連する非共線遺伝子ブロックを識別する比較ゲノミクス方法は、非標準BGCを検出する可能性がより高いが、偽陽性率が高い。また、RiPPについて、既知のタイプにおける遠隔メンバー酵素(配列相同性比較で認識できないメンバー酵素)又は全く新しいタイプの酵素をコードして生成するBGCsを識別する専用ツールが登場している。そのうちの一部(例えば、BAGEL)は、antiSMASH及びPRISMと同様のpHMMに基づく検出技術を使用する。他の研究では、デコイベースの方法(特定のクエリ酵素をコードする遺伝子を用いて、それらのホモログを含む遺伝子座を識別する)又は機械学習方法を使用して、潜在的な前駆体ペプチドをコードする遺伝子を識別し、メタボロミクスに基づくマッチングを使用して分類単位に固有のオペロンを識別することにより、特定の代謝機能をコードすると考えられる。公開利用可能なゲノムについては、antiSMASHによって識別されたBGCをIMG-ABCとantiSMASH-DBなどのオンラインデータベースにおいてインタラクティブに閲覧することができる。
【0004】
しかしながら、単一の遺伝子クラスターに位置するのではなく、複数の染色体に分布するゲノムによってコードされる生物の生合成経路の例が数多くある。ゲノムマイニング方法を生命の木の未開発部分に拡張した場合に、その代謝産物生合成ゲノムのクラスタリング程度は、まだ観察する必要がある。
【0005】
アルゴリズム発展プロセスの観点から見ると、早期に配列比較方式によって保存配列を発見する方法は、機能配列を発見する主な手段とされるが、配列関連研究の深化に伴い、様々な配列マイニングアルゴリズムが登場している。生物学的配列におけるモチーフマイニング(又はモチーフ発見)は、類似した、保存された配列要素(「motif」)のグループを見つける問題として定義されてもよい。これらの配列元素は、通常、ヌクレオチド配列において短くかつ類似し、共通の生物学的機能を有する。初期のmotifマイニング方法は、主に列挙方法と確率方法の2つの主なタイプに分けられる。第1タイプは、簡単な単語列挙に基づくものである。例えば、Sinhaらによって開発された酵母モチーフファインダー(Yeast Motif Finder、YMF)アルゴリズムは、一致性表現を用いて酵母ゲノムにおける少数の縮重位置を有する短いモチーフを検出する。YMFは、主に、探索空間の全てのモチーフ配列(motif)を列挙する第1ステップと、全てのmotifのz-scoreを計算して、スコアが最も高いmotifを見つける第2ステップとに分けられる。
【0006】
列挙に基づくモチーフマイニング方法の実行速度を加速するために、接尾辞木、並列処理などのいくつかの特殊な方法が使用される。また、LMMO、Direct FS、ABC、DiscMLA、CisFinder、Weeder、Fmotif及びMCESなどの配列マイニングアルゴリズムは、モデルにおいてこのポリシーを使用している。確率ベースのモチーフマイニング方法では、いくつかのパラメータを必要とする確率モデルを構築する。これらの方法は、結合領域における各部位に塩基分布を提供することにより、モチーフの有無を区別する。これらの方法は、通常、位置固有のスコアマトリクス(position specific scoring matrix、PSSM/PWM)又はmotifマトリクスによって分布を構築する。PWMは、各位置におけるmotifの優先度を示すm×nサイズのマトリクスである(mは、特定のタンパク質結合部位の長さを示し、nは、ヌクレオチド塩基のタイプを示す)。
【0007】
近年、深層学習は、様々な応用シーンにおいて大きな成功を収めている。これにより、研究者は、これをDNA/RNAモチーフマイニングに適用しようと試みる。DNA/RNAモチーフマイニングは、遺伝子機能研究の基礎であり、研究者は、過去数十年にわたり、モチーフマイニングのために新しい効率的で正確なアルゴリズムを設計することに取り組んでいる。関連する研究結果は、深層学習を代表とするアルゴリズムが良い成績を達成することを示している。従来の配列マイニング深層学習方法は、畳み込みニューラルネットワーク(convolutional neural network、CNN)に基づくモデル、リカレントニューラルネットワーク(recurrent neural network、RNN)に基づくモデル、及びハイブリッドCNN-RNNに基づくモデルの3種類に大別される。従来の深層学習方法を分析して比較することにより、データが十分である場合、より複雑なモデルの方が単純なモデルよりも優れたパフォーマンスを発揮することが多いことが分かる。
【0008】
しかしながら、従来の深層学習に基づく主流なゲノミクスデータマイニング方法は、ある特定のタスク(例えば、抗生物質耐性遺伝子の予測)に対してエンドツーエンド深層学習モデルを設計することが多く、汎用性が低く、柔軟性が低いという問題がある。また、ゲノムデータから目的化合物の生合成経路をマイニングすることは、依然として挑戦性があり、全体のデータ量が豊富であるが、単一機能性酵素に関連するデータ量が不十分である可能性があるなどの問題がある。また、ゲノミクスのデータ量が膨大であり、マイニングアルゴリズムの効率に対する要求が高いという前提で、効率と精度をどのようにバランスさせるかなどの問題がある。
【発明の概要】
【発明が解決しようとする課題】
【0009】
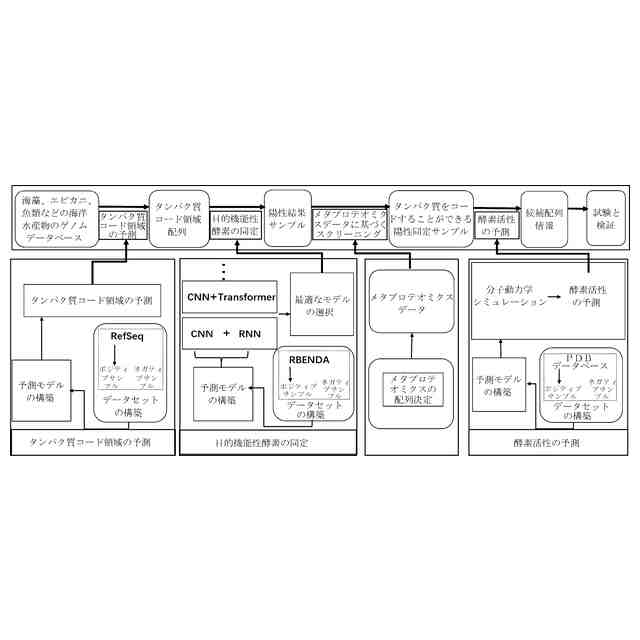
上記問題に対して、本発明は、大量の海洋水産物のゲノムデータに基づいて、自然言語処理ニューラルネットワークモデルと組み合わせて、目的化合物の合成関連酵素をコードする遺伝子の識別及び優先ランキングを実現する海洋栄養成分の生合成経路のマイニング方法、装置、機器及び媒体を設計開発する。各合成ステップに必要な特定の機能性酵素を遺伝子発現により生成し、最終的に合成経路をシミュレーション生成する。また、フローにおける(1)タンパク質コード領域の予測、(2)目的機能性酵素の同定、及び(3)酵素活性の予測と分析という3つの重要な工程の関連技術を最適化することにより、パイプラインの有効性を向上させる。
【課題を解決するための手段】
【0010】
本発明は、以下の技術手段により実現される。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
中国海洋大学
海底横方向探査導入装置及び導入方法
8日前
中国海洋大学
海洋栄養成分の生合成経路のマイニング方法、装置、機器及び媒体
4か月前
中国海洋大学
マルチスケール多孔質構造を有する複合エアロゲルとその製造方法、海水淡水化装置
4か月前
個人
N式トータルシステム
2か月前
富士通株式会社
リスクと診断
3か月前
株式会社M-INT
情報処理システム
2か月前
株式会社タカゾノ
作業時間計測システム
3か月前
医療法人社団梅華会
医療の支援装置
14日前
個人
透析医療に関する回答方法及びその装置
18日前
株式会社サンクスネット
リスク判定システム
21日前
株式会社日立製作所
情報システム
1か月前
株式会社Smart119
情報処理システム
3か月前
アルケア株式会社
コミュニケーションシステム
21日前
個人
弾塑性有限要素法におけるデータ同化の演算方法
2か月前
株式会社JVCケンウッド
表示装置及び表示方法
14日前
公立大学法人大阪
診断装置
1日前
株式会社グローバルビジョン
検体検査管理システム
15日前
公益財団法人がん研究会
画像診断報告書作成システム
2か月前
個人
服薬指導支援システム、及び、服薬指導支援方法
18日前
ロゴスサイエンス株式会社
ヘルスケアシステムおよびその方法
1か月前
トヨタ自動車株式会社
情報処理装置
1か月前
トヨタ自動車株式会社
情報処理装置
1か月前
株式会社バシラックス
零売サービス提供システム
2か月前
大和ハウス工業株式会社
消費カロリー推定システム
29日前
個人
プログラムおよび情報処理装置
2か月前
株式会社AIVICK
食品提供装置及びプログラム
2か月前
KDDI株式会社
摂食監視装置、方法及びプログラム
4か月前
トヨタ自動車株式会社
画像解析装置
8日前
個人
重症化予測装置、重症化予測方法、及びプログラム
3か月前
株式会社メドレー
プログラム、システム及び方法
21日前
セコム株式会社
表示装置及びプログラム
3か月前
セコム株式会社
表示装置及びプログラム
3か月前
株式会社Windy
薬局等を活用したオンライン問診システム
2か月前
株式会社日立製作所
配列情報処理装置および方法
15日前
富士通株式会社
演算プログラム、演算方法、および情報処理装置
3か月前
アイホン株式会社
コミュニケーションシステム
3か月前
続きを見る
他の特許を見る

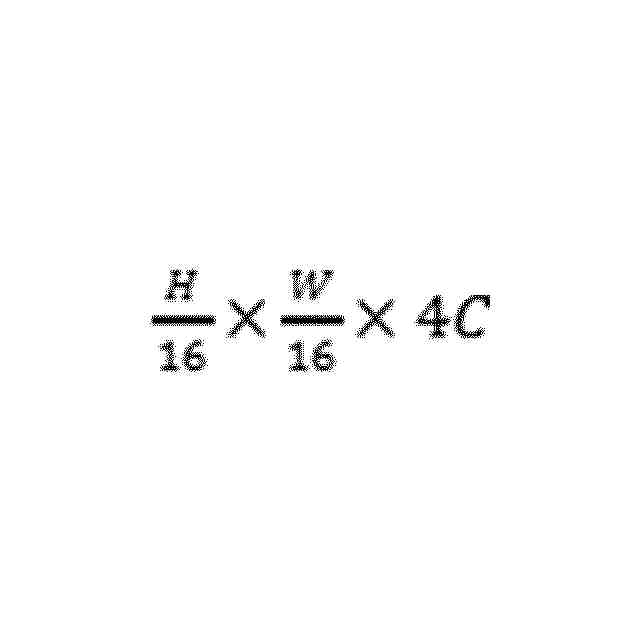
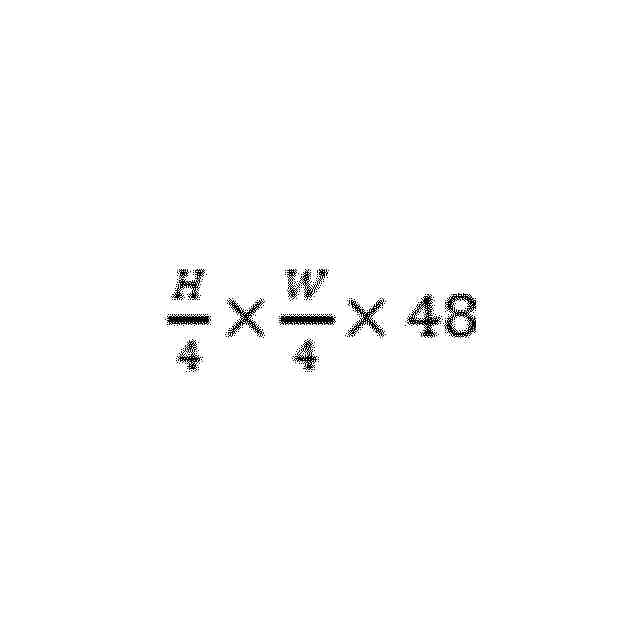
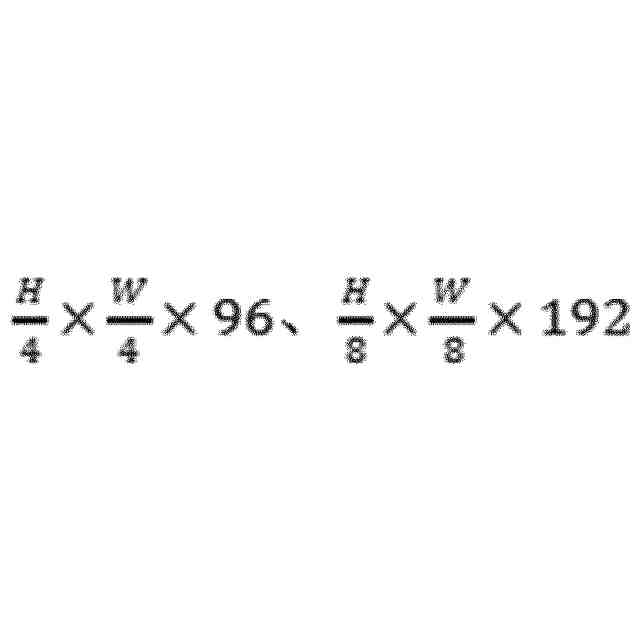
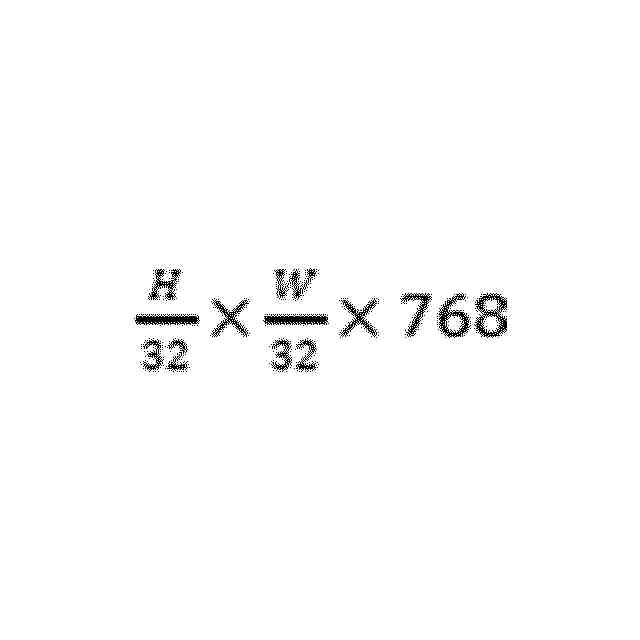
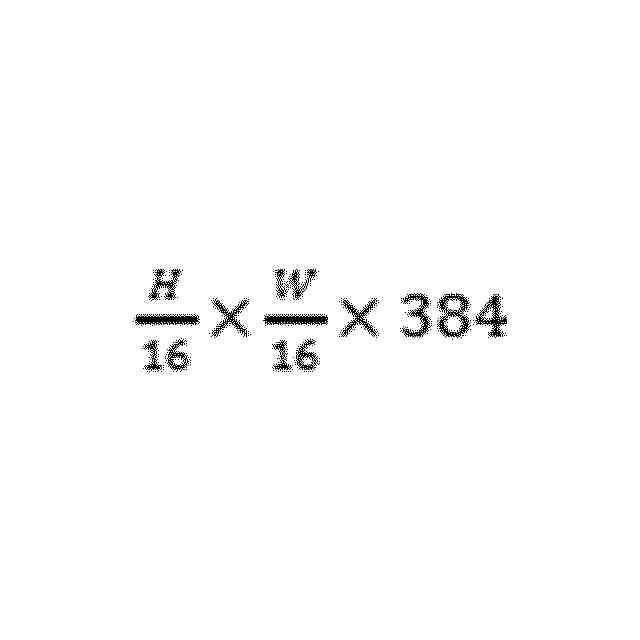
 特許ウォッチ
特許ウォッチ