TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2023183848
公報種別
公開特許公報(A)
公開日
2023-12-28
出願番号
2022097621
出願日
2022-06-16
発明の名称
クラスタリング装置、クラスタリング方法及びプログラム
出願人
日本電信電話株式会社
,
学校法人神奈川大学
代理人
個人
,
個人
,
個人
主分類
G06F
17/16 20060101AFI20231221BHJP(計算;計数)
要約
【課題】疎データを効率的にクラスタリングする装置、方法及びプログラムを提供する。
【解決手段】オブジェクトを表す1以上の特徴とその特徴量で構成されるオブジェクト特徴ベクトルを複数のクラスタにクラスタリングするクラスタリング装置は、特徴を識別する特徴識別子毎に、クラスタを識別するクラスタ識別子と該クラスタに属するオブジェクト特徴ベクトルの平均を表すmean特徴ベクトルの特徴識別子に関する第1の非零特徴量とを対応付けた組を格納する配列要素で構成されるデータを記憶し、データに基づいて、オブジェクト特徴ベクトルの第2の非零特徴量と第2の非零特徴量の特徴識別子とを対応付けた組でオブジェクト特徴ベクトルを表したスパース表現のオブジェクト特徴ベクトルと、各クラスタのmean特徴ベクトルとの類似度を計算し、類似度に基づいて、オブジェクト特徴ベクトルを、複数のクラスタのうちの一のクラスタに割り当てる。
【選択図】図7
特許請求の範囲
【請求項1】
オブジェクトを表す1以上の特徴と前記1以上の特徴の各々の値である1以上の特徴量とで構成されるオブジェクト特徴ベクトルを複数のクラスタにクラスタリングするクラスタリング装置であって、
前記特徴を識別する特徴識別子毎に、前記クラスタを識別するクラスタ識別子と該クラスタに属するオブジェクト特徴ベクトルの平均を表すmean特徴ベクトルの前記特徴識別子に関する第1の非零特徴量とを対応付けた組を格納する配列要素で構成されたデータを記憶部に記憶させるように構成されている記憶制御部と、
前記データに基づいて、前記オブジェクト特徴ベクトルの第2の非零特徴量と該第2の非零特徴量の特徴識別子とを対応付けた組で前記オブジェクト特徴ベクトルを表したスパース表現のオブジェクト特徴ベクトルと、各クラスタの前記mean特徴ベクトルとの類似度を計算するように構成されている類似度計算部と、
前記類似度に基づいて、前記オブジェクト特徴ベクトルを、前記複数のクラスタのうちの一のクラスタに割り当てるように構成されている割当部と、
を有し、
前記データは、
前記特徴識別子が第1の閾値未満の前記配列要素を表す第1の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値以上の前記配列要素を表す第2の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値未満の前記配列要素を表す第3の配列要素とで構成されている、クラスタリング装置。
続きを表示(約 2,300 文字)
【請求項2】
前記データは、
前記特徴識別子が第1の閾値未満の前記配列要素を表す第1の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値以上の前記配列要素を表す第2の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値未満の前記配列要素を表す第3の配列要素とが転置ファイルで構成されている、請求項1に記載のクラスタリング装置。
【請求項3】
前記データは、
前記特徴識別子が第1の閾値未満の前記配列要素を表す第1の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値以上の前記配列要素を表す第2の配列要素とが転置ファイルで構成されており、
前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値未満の前記配列要素を表す第3の配列要素が標準的な転置ファイルで構成されている、請求項1に記載のクラスタリング装置。
【請求項4】
前記類似度計算部は、
前記スパース表現のオブジェクト特徴ベクトルに含まれる第2の非零特徴量の特徴識別子が前記第1の閾値未満である場合、前記第2の非零特徴量と、前記データを構成する配列要素のうち、前記特徴識別子に対応する配列要素に格納されている第1の非零特徴量と積を計算することで、前記類似度を計算し、
前記スパース表現のオブジェクト特徴ベクトルに含まれる第2の非零特徴量の特徴識別子が前記第1の閾値以上、かつ、前記第2の非零特徴量との類似度の計算対象となる第1の非零特徴量が前記第2の閾値以上である場合、前記第2の非零特徴量と前記第1の非零特徴量との積を計算することで、前記類似度を計算すると共に、前記スパース表現のオブジェクト特徴ベクトルの部分的なノルムを計算し、
前記スパース表現のオブジェクト特徴ベクトルに含まれる第2の非零特徴量の特徴識別子が前記第1の閾値以上、かつ、前記第2の非零特徴量との類似度の計算対象となる第1の非零特徴量が前記第2の閾値未満である場合、前記スパース表現のオブジェクト特徴ベクトルと該オブジェクト特徴ベクトルが現在属しているクラスタのmean特徴ベクトルとの類似度が、前記ノルムから計算される類似度上限値以下であるときに、前記第2の非零特徴量と前記第1の非零特徴量との積を計算することで、前記類似度を計算するように構成されている、請求項1に記載のクラスタリング装置。
【請求項5】
前記データは、
前記第1の配列要素及び前記第2の配列要素のそれぞれにおいて、前記割当部による割り当ての前後でクラスタに属するオブジェクト特徴ベクトルに変更あったクラスタを示す変更クラスタに対応するmean特徴ベクトルの第1の非零要素が含まれる組が格納される配列要素と、前記割当部による割り当ての前後でクラスタに属するオブジェクト特徴ベクトルが不変であったクラスタを示す不変クラスタに対応するmean特徴ベクトルの第1の非零要素が含まれる組が格納される配列要素とが区別可能に存在し、
前記類似度計算部は、
前記スパース表現のオブジェクト特徴ベクトルが属するクラスタが不変クラスタである場合、前記スパース表現のオブジェクト特徴ベクトルに含まれる第2の非零特徴量と、前記変更クラスタに対応するmean特徴ベクトルの第1の非零要素との積を計算することで、前記類似度を計算するように構成されている、請求項1乃至3の何れか一項に記載のクラスタリング装置。
【請求項6】
1つ前のイテレーションにおける前記類似度計算部による類似度の計算結果と前記割当部による割当結果とに基づいて、前記第2の閾値を最適化するように構成されている最適化部を更に有する請求項1に記載のクラスタリング装置。
【請求項7】
オブジェクトを表す1以上の特徴と前記1以上の特徴の各々の値である1以上の特徴量とで構成されるオブジェクト特徴ベクトルを複数のクラスタにクラスタリングするクラスタリング装置が、
前記特徴を識別する特徴識別子毎に、前記クラスタを識別するクラスタ識別子と該クラスタに属するオブジェクト特徴ベクトルの平均を表すmean特徴ベクトルの前記特徴識別子に関する第1の非零特徴量とを対応付けた組を格納する配列要素で構成されたデータを記憶部に記憶させる記憶制御手順と、
前記データに基づいて、前記オブジェクト特徴ベクトルの第2の非零特徴量と該第2の非零特徴量の特徴識別子とを対応付けた組で前記オブジェクト特徴ベクトルを表したスパース表現のオブジェクト特徴ベクトルと、各クラスタの前記mean特徴ベクトルとの類似度を計算する類似度計算手順と、
前記類似度に基づいて、前記オブジェクト特徴ベクトルを、前記複数のクラスタのうちの一のクラスタに割り当てる割当手順と、
を実行し、
前記データは、
前記特徴識別子が第1の閾値未満の前記配列要素を表す第1の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値以上の前記配列要素を表す第2の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値未満の前記配列要素を表す第3の配列要素とで構成されている、クラスタリング方法。
【請求項8】
コンピュータを、請求項1に記載のクラスタリング装置として機能させるプログラム。
発明の詳細な説明
【技術分野】
【0001】
本開示は、クラスタリング装置、クラスタリング方法及びプログラムに関する。
続きを表示(約 3,100 文字)
【背景技術】
【0002】
膨大な量の情報を効率的に処理するための方法の1つとして、k-means法に代表されるクラスタリング手法が知られている。クラスタリング手法では、各々の情報の間の関係性(類似度、非類似度、距離等)を表す尺度により、複数の情報を1つにまとめたり、与えられた情報群を複数の集合に分割したりできる。以下、クラスタリングの対象となる「情報」を「オブジェクト」と呼ぶ。
【0003】
k-means法は、例えば、オブジェクトの特徴を表すベクトルデータ(以下、オブジェクト特徴ベクトルという。)をx
i
として、データ集合X={x
0
,x
1
,・・・,x
N-1
}とクラスタ数Kとが与えられたときに、データ集合XをK個のクラスタに分割する手法である。k-means法では、例えば、クラスタC
j
に属する各オブジェクト特徴ベクトルx
i
の平均を表すベクトルμ
j
(以下、mean特徴ベクトルという。)との内積を目的関数として、その目的関数を最大化するように、各オブジェクト特徴ベクトルx
i
が割り当てられるクラスタC
j
が決定される。一方で、k-means法の厳密解を計算するには多くの計算量を要するため、Lloyd法と呼ばれる発見的手法が良く用いられる。
【0004】
ところで、近年では、オブジェクト特徴ベクトルが高次元かつ疎(スパース)なデータで表されることが多い。例えば、文書、購入者(又はユーザ)と購入品(又はアイテム)との関係を表す購買履歴、bag-of-visual wordsで表される画像等をオブジェクトとした場合、これらのオブジェクトは高次元かつ疎なオブジェクト特徴ベクトルで表現されることが多い。以下、大量の高次元かつ疎なデータの集合を大規模高次元疎データ集合と呼ぶ。
【0005】
Lloyd法は初期状態設定ステップ、割当ステップ、更新ステップ及び終了判定ステップで構成されるが、割当ステップでは各オブジェクト特徴ベクトルx
i
と各mean特徴ベクトルμ
j
との内積を計算する必要があるため、割当ステップの時間計算量が支配的である。このため、割当ステップの時間計算量を削減することが求められている。
【0006】
Lloyd法の割当ステップは、オブジェクト特徴ベクトルの集合をクエリオブジェクト集合、mean特徴ベクトルの集合を被探索データオブジェクト集合と見做せば、最類似探索問題と等価である。大規模高次元疎データ集合の最類似探索問題を高速に解くことが可能な代表的な手法の1つに、データ構造として転置ファイル(inverted file)(又は、転置インデックス(inverted index)とも呼ばれる。)を使用する方法が知られている。例えば、非特許文献1及び2では、転置ファイルを効率的に利用した高速化手法が提案されている。また、非特許文献3では、mean特徴ベクトル集合の転置ファイルで表現した高速化手法が提案されている。なお、転置ファイルを利用した手法ではないが、非特許文献4では、類似度の上限値(又は、距離の下限値)を用いて、Lloyd法を加速する手法(Ding法と呼ぶ。)が提案されている。
【先行技術文献】
【非特許文献】
【0007】
M. Fontoura, V. Josifovski, J. Liu, S. Venkatesan, X. Zhu, and J. Zien, "Evaluation strategies for top-k queries over memory-resident inverted indexes," Proc. VLDB Endowment, vol. 5, no. 12, 2011.
Y. Li, J. Wang, B. Pullman, N. Bandeira, and Y. Papakonstantinou, "Index-based, high-dimensional, cosine threshold querying with optimality guarantees," Proc. Int. Conf. Database Theory (ICDT), 2019.
Kazuo Aoyama and Kazumi Saito, "Structured inverted-file k-means clustering for high-dimensional sparse data," arXiv: 2103.16141, https://arxiv.org/abs/2103.16141.
Y. Ding, Y. Zhao, X. Shen, M. Musuvathi, and T. Mykowicz, "Yinyang K-means: A drop-in replacement of the classic K-means with consistent speedup," Proc. Int. Conf. Machine Learning (ICML), 2015.
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかしながら、大規模高次元疎データ集合に対するクラスタリング手法の更なる高速化が望まれている。
【0009】
本開示は、上記の点に鑑みてなされたもので、疎データを効率的にクラスタリングする技術を提供する。
【課題を解決するための手段】
【0010】
本開示の一態様によるクラスタリング装置は、オブジェクトを表す1以上の特徴と前記1以上の特徴の各々の値である1以上の特徴量とで構成されるオブジェクト特徴ベクトルを複数のクラスタにクラスタリングするクラスタリング装置であって、前記特徴を識別する特徴識別子毎に、前記クラスタを識別するクラスタ識別子と該クラスタに属するオブジェクト特徴ベクトルの平均を表すmean特徴ベクトルの前記特徴識別子に関する第1の非零特徴量とを対応付けた組を格納する配列要素で構成されたデータを記憶部に記憶させるように構成されている記憶制御部と、前記データに基づいて、前記オブジェクト特徴ベクトルの第2の非零特徴量と該第2の非零特徴量の特徴識別子とを対応付けた組で前記オブジェクト特徴ベクトルを表したスパース表現のオブジェクト特徴ベクトルと、各クラスタの前記mean特徴ベクトルとの類似度を計算するように構成されている類似度計算部と、前記類似度に基づいて、前記オブジェクト特徴ベクトルを、前記複数のクラスタのうちの一のクラスタに割り当てるように構成されている割当部と、を有し、前記データは、前記特徴識別子が第1の閾値未満の前記配列要素を表す第1の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値以上の前記配列要素を表す第2の配列要素と、前記特徴識別子が前記第1の閾値以上かつ前記第1の非零特徴量が第2の閾値未満の前記配列要素を表す第3の配列要素とで構成されている。
【発明の効果】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
GPSロガー
11日前
個人
情報処理システム
1か月前
個人
デトろぐシステム
10日前
個人
防災情報システム
1か月前
日本精機株式会社
表示装置
24日前
個人
管理装置
3日前
個人
指先受の付いたマウス。
27日前
個人
介護者指名システム
1か月前
個人
都市経営シミュレーション
16日前
個人
管理装置
5日前
個人
特徴検討支援システム
3日前
個人
契約管理サーバ
2日前
有限会社マイコム
制御盤のAI見積
1か月前
株式会社Haul
採用支援方法
1か月前
エムケー精工株式会社
洗車場システム
1か月前
キヤノン株式会社
情報処理装置
1か月前
個人
支援システム及び支援方法
18日前
國立臺灣大學
操作補助システム
17日前
株式会社テクロス
情報処理装置
9日前
株式会社にしがき
会員権システム
1か月前
株式会社Asuka
本人認証方法
1か月前
個人
災害情報表示システム
1か月前
株式会社奥村組
削孔位置検出方法
2日前
トヨタ自動車株式会社
車両
3日前
個人
すべて大吉となるおみくじ制作装置
23日前
トヨタ自動車株式会社
表認識方法
1か月前
株式会社美好屋商店
広告システム
16日前
株式会社野村総合研究所
検証装置
9日前
日本電気株式会社
システム及び方法
2日前
トヨタ自動車株式会社
記号認識装置
6日前
個人
マイナンバーポイントの直販システム
12日前
株式会社mov
情報処理装置
1か月前
トヨタ自動車株式会社
情報処理装置
6日前
トヨタ自動車株式会社
画像処理装置
1か月前
トヨタ自動車株式会社
情報処理装置
1か月前
日本信号株式会社
料金精算システム
23日前
続きを見る
他の特許を見る

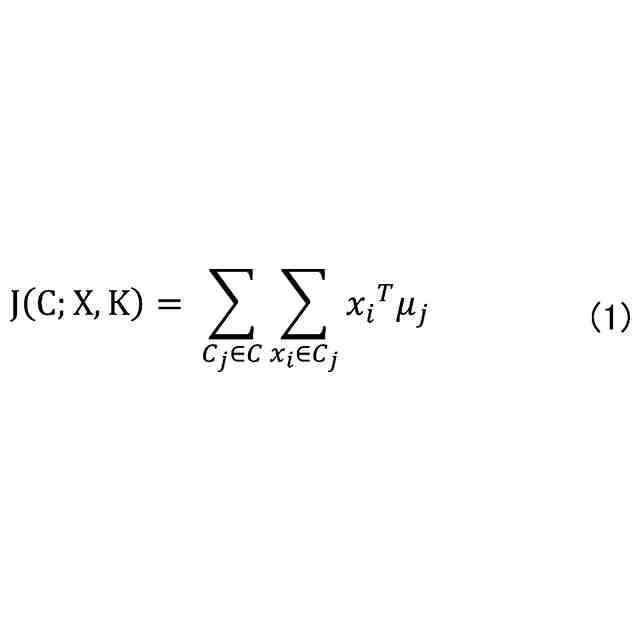
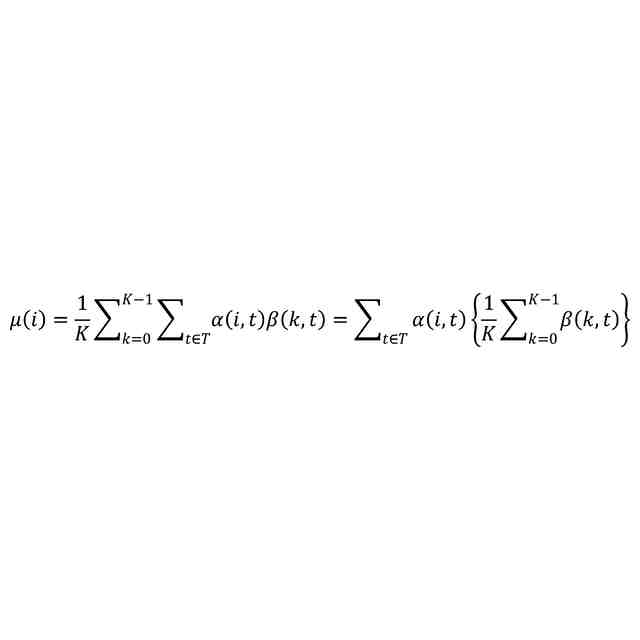
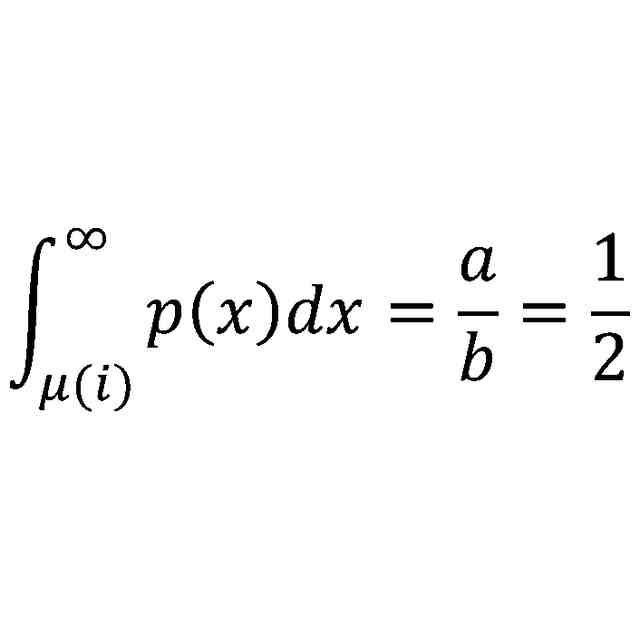

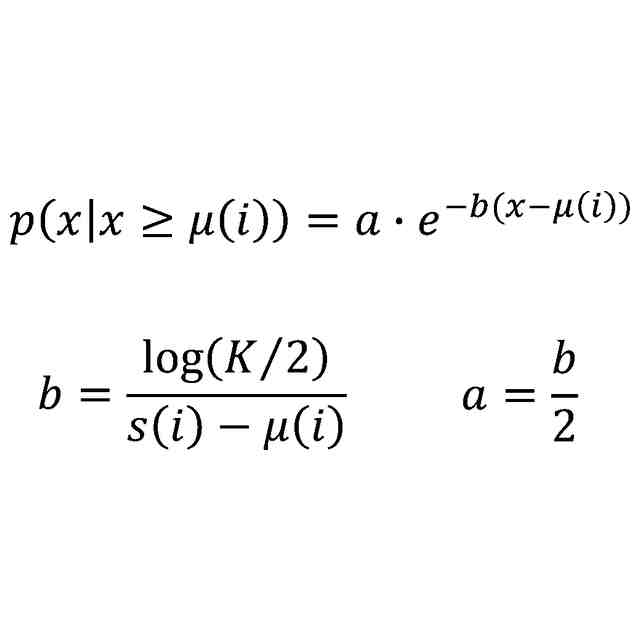
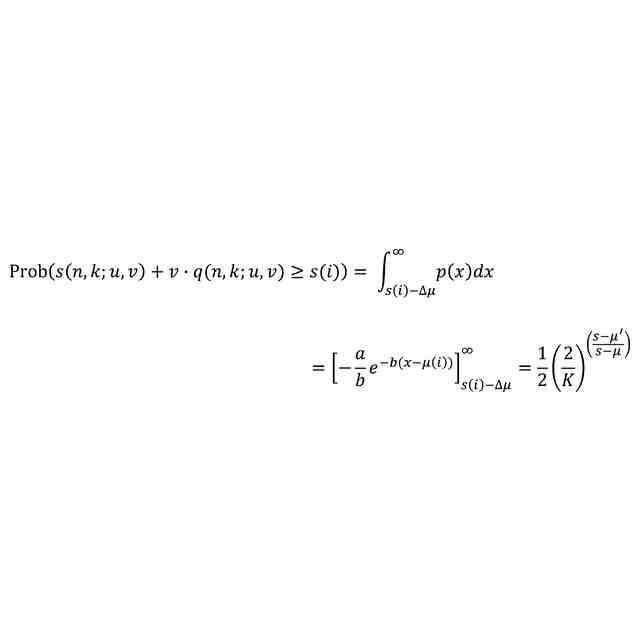


 特許ウォッチ
特許ウォッチ