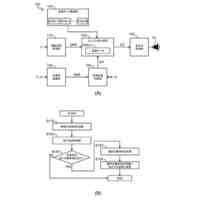
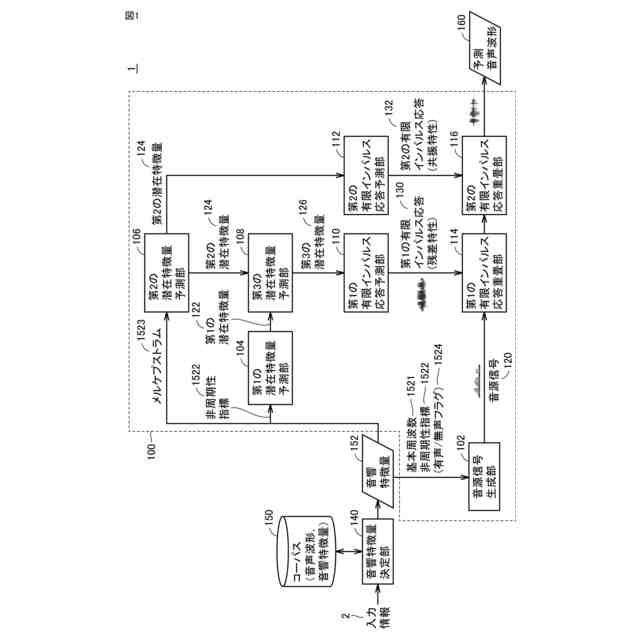
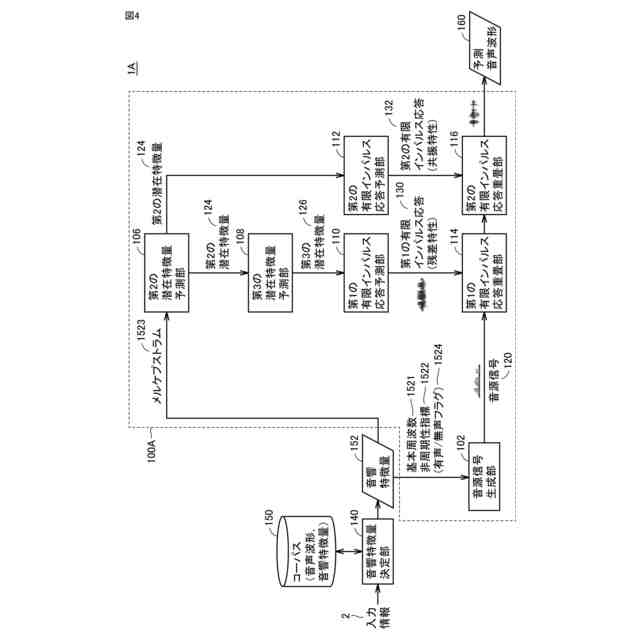
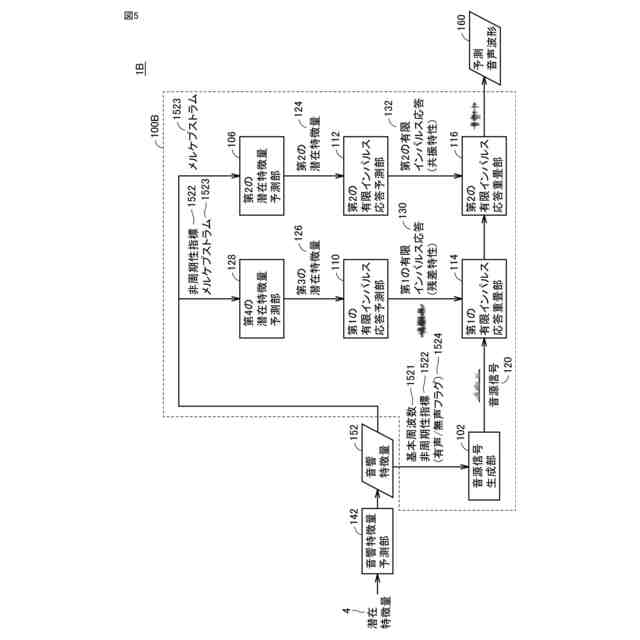
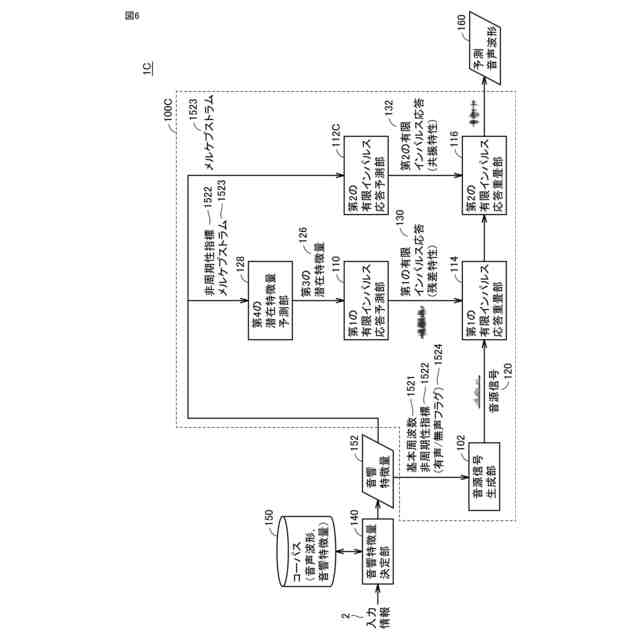
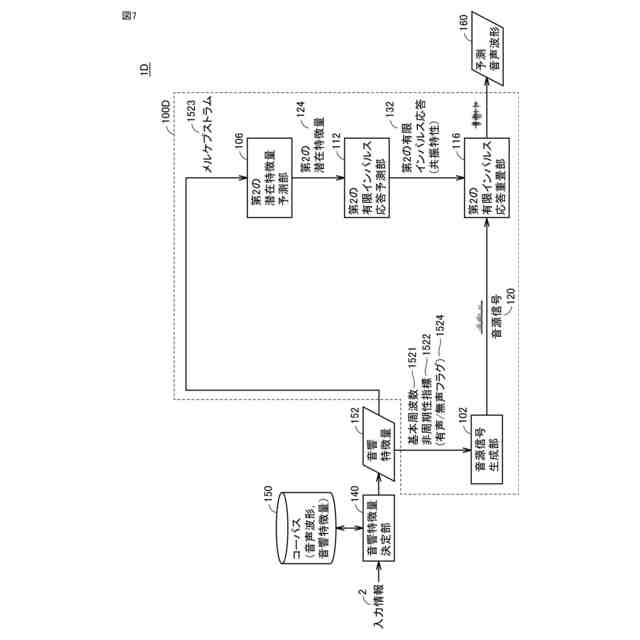
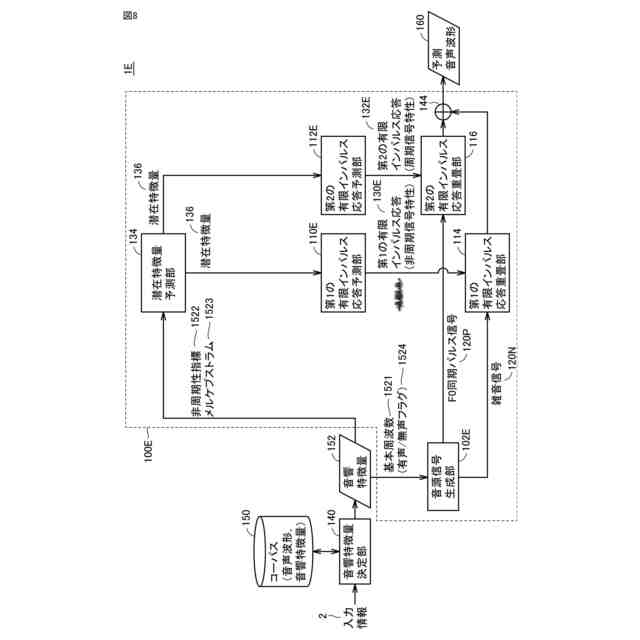
発明の詳細な説明【技術分野】 【0001】 本発明は、入力された音響特徴量に基づいて予測音声波形を出力する音声波形生成システム、音声波形生成方法および音声波形予測プログラム、ならびに、音声波形予測モデルを学習するための学習システム、音声波形予測モデルの学習方法および音声波形予測モデルを学習するための学習プログラムに関する。 続きを表示(約 2,600 文字)【背景技術】 【0002】 近年、深層学習を用いた音声技術の性能は飛躍的に向上している。これに伴って、深層学習を用いた音声技術の普及も急速に広がっている。特に、テキスト音声合成(Text-to-speech synthesis:TTS)技術においては、ニューラルボコーダを採用することで、出力される音声品質は、人の発話とほぼ同様のレベルに達している。 【0003】 一方で、ニューラルボコーダは、従来のテキスト音声合成製品(例えば、非特許文献1に示す信号処理型ボコーダ)と比較して処理速度が遅いという課題も存在する。また、ニューラルボコーダは、従来のテキスト音声合成製品が有していた機能、特に、音高を表す基本周波数(F0)の制御性に制約が存在しており、実用上の課題となっている。 【0004】 例えば、基本周波数依存型拡張畳み込みネットワークの導入により基本周波数を制御することが提案されている(非特許文献2)。 【0005】 また、人の音源と声道情報とが独立であると仮定している発声機構を、モデル化したソースフィルタモデルに基づいた手法により基本周波数を制御することも提案されている(非特許文献3)。 【0006】 さらに、上述の2つの技術を組み合わせることで、処理を高速化する手法が提案されている(非特許文献4)。 【先行技術文献】 【非特許文献】 【0007】 Morise, M., Yokomori, F., and Ozawa, K., "WORLD: A Vocoder-Based High-Quality Speech Synthesis System for Real-Time Applications", IEICE Transactions on Information and Systems, vol. 99, no. 7, pp. 1877-1884, 2016. doi:10.1587/transinf.2015EDP7457. Y. -C. Wu, T. Hayashi, P. L. Tobing, K. Kobayashi and T. Toda, "Quasi-Periodic WaveNet: An Autoregressive Raw Waveform Generative Model With Pitch-Dependent Dilated Convolution Neural Network", in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1134-1148, 2021, doi: 10.1109/TASLP.2021.3061245. X. Wang, S. Takaki and J. Yamagishi, "Neural Source-Filter Waveform Models for Statistical Parametric Speech Synthesis", in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 402-415, 2020, doi: 10.1109/TASLP.2019.2956145. Yoneyama, Reo et al. "Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder", ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2022): 1-5. S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I.-S. Kweon, and S. Xie, "ConvNeXt V2: Co-designing and scaling convnets with masked autoencoders", Proc. CVPR, pp. 16133-16142,2023. 【発明の概要】 【発明が解決しようとする課題】 【0008】 ニューラルボコーダでは、上述したような様々な工夫により基本周波数の制御を実現しているが、従来の信号処理型ボコーダと比較すると、十分な基本周波数の制御性は得られない。例えば、基本周波数の制御範囲について見ると、信号処理型ボコーダの制御範囲には制限がない一方で、ニューラルボコーダの制御範囲は0.5~2倍程度と狭い。また、処理速度について見ると、高速なニューラルボコーダであっても、信号処理型ボコーダの1/5倍以下と遅い。十分な処理速度が得られない理由として、既存のニューラルボコーダにおいては、音声波形のベースとなる音源信号に対して、深いニューラルネットワークを直接適用していることが考えられる。また、既存のニューラルボコーダにおいては、ネットワーク構造が基本周波数に依存しているため、制御可能な範囲も基本周波数に依存することになる。 【0009】 本発明は、ニューラルボコーダの音声品質を維持しつつ、信号処理型ボコーダと同程度の処理速度および基本周波数の制御性を有する音声波形生成技術を提供することを目的とする。 【課題を解決するための手段】 【0010】 ある実施の形態に従う音声波形生成システムは、入力された音響特徴量に基づいて予測音声波形を出力する音声波形予測部を含む。音声波形予測部は、基本周波数に同期する成分を含む音源信号を生成する音源信号生成部と、音響特徴量の少なくとも一部に基づいて、少なくとも1つの有限インパルス応答を予測する有限インパルス応答予測部と、音源信号に少なくとも1つの有限インパルス応答を重畳する有限インパルス応答重畳部とを含む。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する

 特許ウォッチ
特許ウォッチ