TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025095177
公報種別
公開特許公報(A)
公開日
2025-06-26
出願番号
2023211014
出願日
2023-12-14
発明の名称
システム、システムが実行する方法、プログラム
出願人
株式会社日立製作所
代理人
弁理士法人ウィルフォート国際特許事務所
主分類
G06N
20/00 20190101AFI20250619BHJP(計算;計数)
要約
【課題】 学習データの形式が(テキストデータ形式以外の)元データ形式である場合において、モデルの品質(精度)を向上させるように学習データセットを編集する。
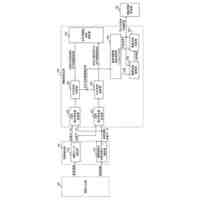
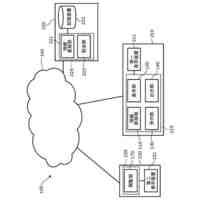
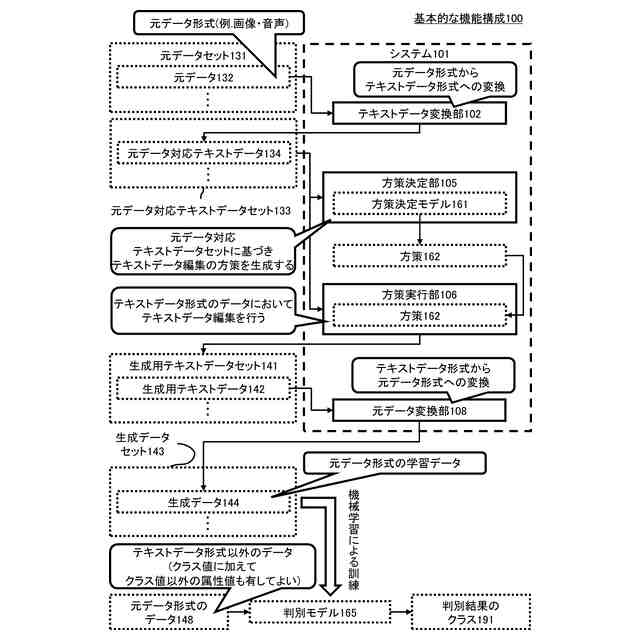
【解決手段】 テキストデータ変換部102は、元データ形式の元データ132を元データ対応テキストデータ134に変換する。方策決定部105は、元データ対応テキストデータセット133と方策決定モデル161に基づいて方策162を生成する。方策実行部106は、方策162に基づいて、元データ対応テキストデータセット133を編集して生成用テキストデータセット141を生成する。元データ変換部108は、生成用テキストデータ142を元データ形式の生成データ144に変換する。生成データ144は、元データ形式のデータ148のクラス191を判別する判別モデル165を機械学習により訓練するための学習データである。
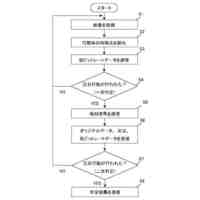
【選択図】 図1
特許請求の範囲
【請求項1】
システムであって、
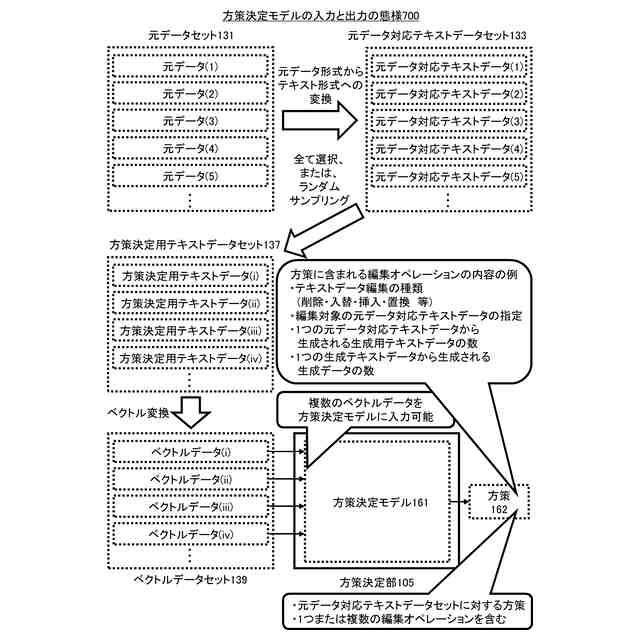
元データセットに含まれる元データ形式の元データのそれぞれを、テキストデータ形式の元データ対応テキストデータのそれぞれに変換するテキストデータ変換部と、
前記元データ対応テキストデータのそれぞれからなる元データ対応テキストデータセットと、方策決定モデルに基づいて、前記元データ対応テキストデータセットに適用される方策を生成する方策決定部と、
前記方策に基づいて、前記元データ対応テキストデータセットを編集して、生成用テキストデータのセットである生成用テキストデータセットを生成する方策実行部と、
前記生成用テキストデータセットに含まれる前記生成用テキストデータのそれぞれを、前記元データ形式の生成データのそれぞれに変換する元データ変換部であって、前記生成データは、前記元データ形式のデータのクラスを判別する判別モデルを機械学習により訓練するための学習データである、前記元データ変換部を有するシステム。
続きを表示(約 1,700 文字)
【請求項2】
請求項1に記載のシステムであって、
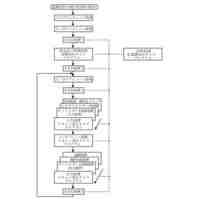
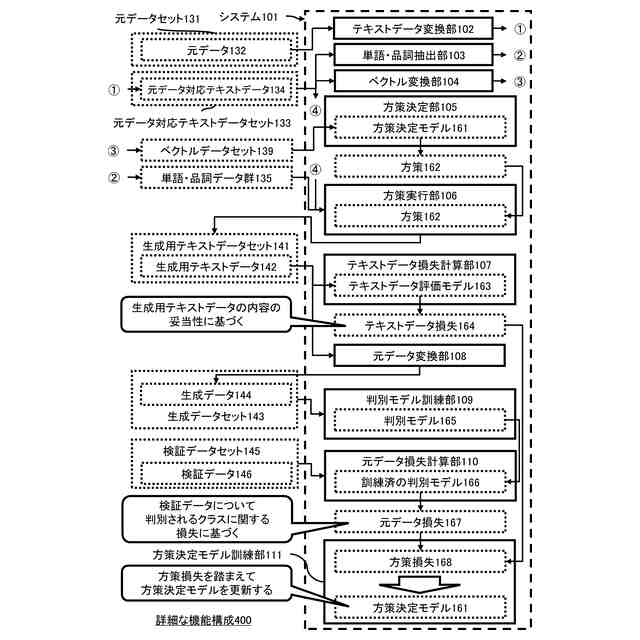
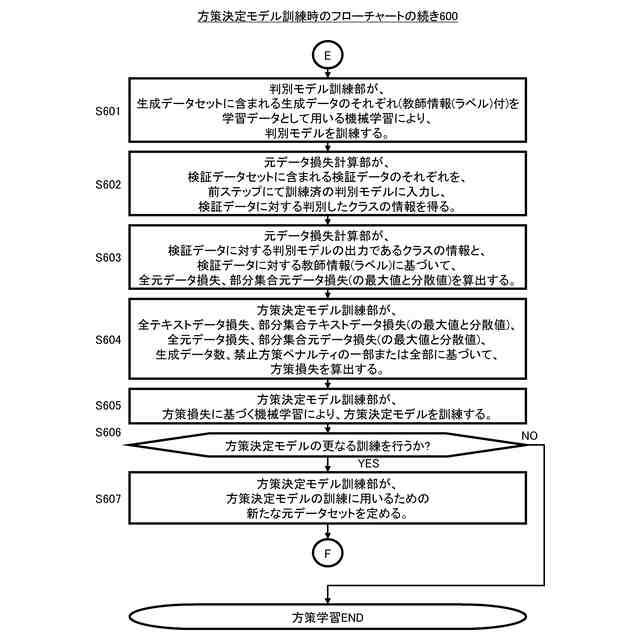
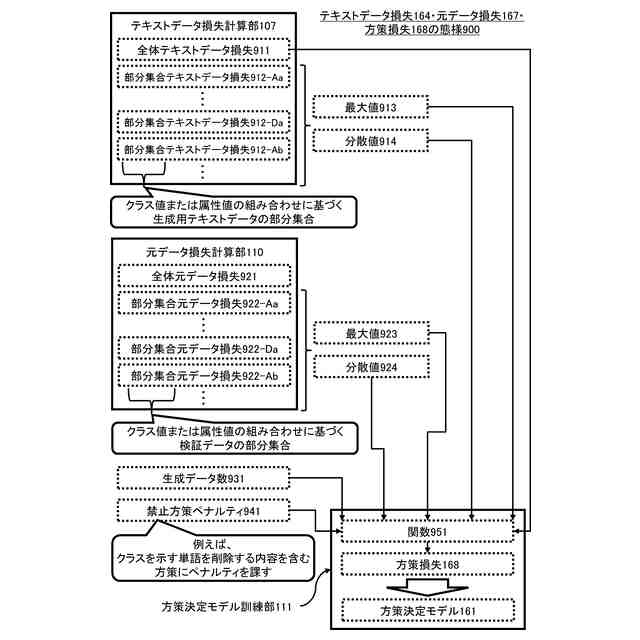
前記生成用テキストデータセットと、テキストデータ評価モデルに基づいて、テキストデータ損失を求めるテキストデータ損失計算部と、
前記生成データのそれぞれを学習データとして用いる機械学習により、前記判別モデルを訓練する判別モデル訓練部と、
前記判別モデル訓練部による訓練済の前記判別モデルにおける、検証データセットに含まれる前記元データ形式の検証データのそれぞれのクラスの判別に関する損失に基づいて、元データ損失を求める元データ損失計算部と、
前記テキストデータ損失と前記元データ損失に基づいて前記方策決定モデルの損失である方策損失を定め、前記方策損失に基づく機械学習により前記方策決定モデルの訓練を行う方策決定モデル訓練部を有するシステム。
【請求項3】
請求項2に記載のシステムであって、
前記方策損失は、前記生成用テキストデータセットに含まれる前記生成用テキストデータの全てに基づく全体テキストデータ損失、前記生成用テキストデータセットに含まれる前記生成用テキストデータの部分集合のそれぞれに基づく部分集合テキストデータ損失の最大値、前記部分集合テキストデータ損失の分散値、前記検証データセットに含まれる前記検証データの全てに基づく全体元データ損失、前記検証データセットに含まれる前記検証データの部分集合のそれぞれに基づく部分集合元データ損失の最大値、または、前記部分集合元データ損失の分散値のいずれかに基づくものである、システム。
【請求項4】
請求項3に記載のシステムであって、
前記生成用テキストデータの部分集合、または、前記検証データの部分集合は、前記生成用テキストデータまたは前記検証データのそれぞれに対応付けられる1つまたは複数の前記クラス、または、前記生成用テキストデータまたは前記検証データのそれぞれに対応付けられる1つまたは複数の属性に関する、クラス値、属性値、または、クラス値または属性値の組み合わせに基づいて形成されるものである、システム。
【請求項5】
請求項3に記載のシステムであって、
前記方策損失は、前記全体テキストデータ損失、前記部分集合テキストデータ損失の最大値、前記部分集合テキストデータ損失の分散値、前記全体元データ損失、前記部分集合元データ損失の最大値、及び、前記部分集合元データ損失の分散値それぞれに、係数を乗じた値を足し合わせた値に基づくものである、システム。
【請求項6】
請求項1に記載のシステムであって、
前記方策決定部は、前記元データ対応テキストデータに含まれる前記クラスを示す単語を削除する内容を含まない前記方策を生成する、システム。
【請求項7】
請求項1に記載のシステムであって、
前記方策決定部は、前記元データ対応テキストデータセットに含まれる前記元データ対応テキストデータの一部または全部と、前記方策決定モデルに基づいて、前記元データ対応テキストデータセットに適用される方策を生成する、システム。
【請求項8】
請求項2に記載のシステムであって、
前記方策損失は、前記方策に基づいて生成される前記生成データの数に基づくものである、システム。
【請求項9】
請求項1に記載のシステムであって、
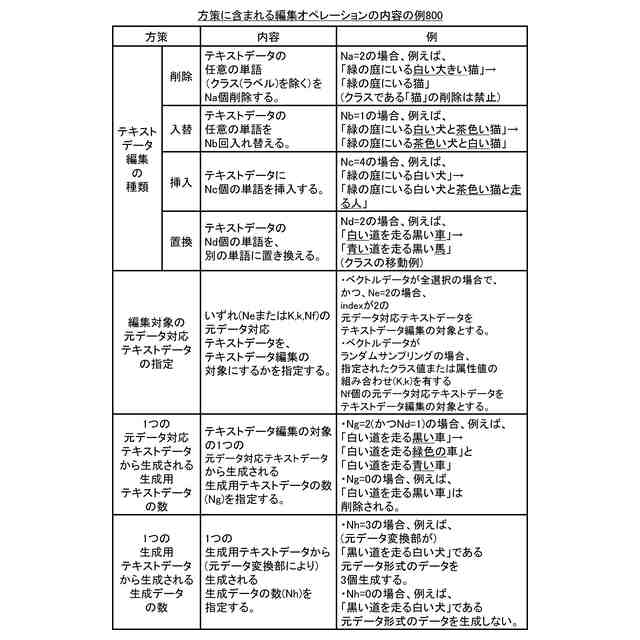
前記方策決定部は、前記元データ対応テキストデータセットに含まれる前記元データ対応テキストデータのいずれを、前記方策実行部が行うテキストデータ編集の対象とするのかを指定する情報を含む前記方策を生成する、システム。
【請求項10】
請求項1に記載のシステムであって、
前記方策決定部は、前記方策実行部がテキストデータ編集により生成する前記生成用テキストデータについて、前記元データ変換部が当該生成用テキストデータに基づき生成する前記生成データの数を指定する情報を含む前記方策を生成する、システム。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本開示は、モデルを機械学習により訓練するために用いる学習データセットを編集する技術(例えば、データ拡張やデータ生成を行う技術)に関するものである。
続きを表示(約 5,400 文字)
【背景技術】
【0002】
機械学習により訓練されるモデルの品質(精度)は、訓練に用いる学習データセットの品質に依存し得る。学習データが有し得る様々な性質のそれぞれについて、当該性質を有する学習データの数がある程度以上存在することが、高品質な学習データセットを形成するためには有用であるとされる。しかしながら、学習データの収集コスト等の理由のため、高品質な学習データセットを形成出来るほどには、充分な数の学習データを収集出来ないことがありうる。例えば、収集した学習データセットにおいて、ある性質を有する学習データは充分以上の数が存在し、別の性質を有する学習データは適切な数だけ存在し、更に別の性質を有する学習データは数が不足しているということがあり得る。
【0003】
以上の事情から、従来より、学習データセットを編集する技術が知られている。学習データセットを編集する技術として、例えば、データ拡張の技術やデータ生成の技術がある。データ拡張の技術とは、学習データセットに含まれる、ある学習データを変更(編集)することにより、新たな学習データを作成または追加する技術である。データ生成の技術とは、データ拡張により学習データを生成する技術に加え、学習データセットに含まれない新規の学習データを生成する技術を含むものである。
学習データセットを編集する技術(例えば、データ拡張の技術やデータ生成の技術)として、例えば、非特許文献1に開示された技術と非特許文献2に開示された技術がある。非特許文献1は、画像データのクラスを判別すること(画像データを分類すること(image classification))を実現するための学習データについて、自動的なデータ拡張(AutoAugment)を行う技術を開示している。非特許文献2は、テキストデータ形式のデータのクラスを判別すること(テキストデータ形式のデータを分類すること(text classification))を実現するための学習データについて、テキストデータにおける自動的なデータ拡張(Text AutoAugment)を行う技術を開示している。
【先行技術文献】
【非特許文献】
【0004】
Vanchinbal Chinbat, Seung-Hwan Bae, "GA3N : Generative adversarial AutoAugment network", Pattern Recognition, Elsevier Ltd., 2022, no.127, 11pages
Shuhuai Ren, Jinchao Zhang, Lei Li, Xu Sun, Jie Zhou, "Text AutoAugment : Learning Composition Augmentation Policy for Text Classification", [online], 2021, arXiv, arxiv.org, [令和5年11月20日検索], インターネット<URL: https://arxiv.org/pdf/2109.00523.pdf>
【発明の概要】
【発明が解決しようとする課題】
【0005】
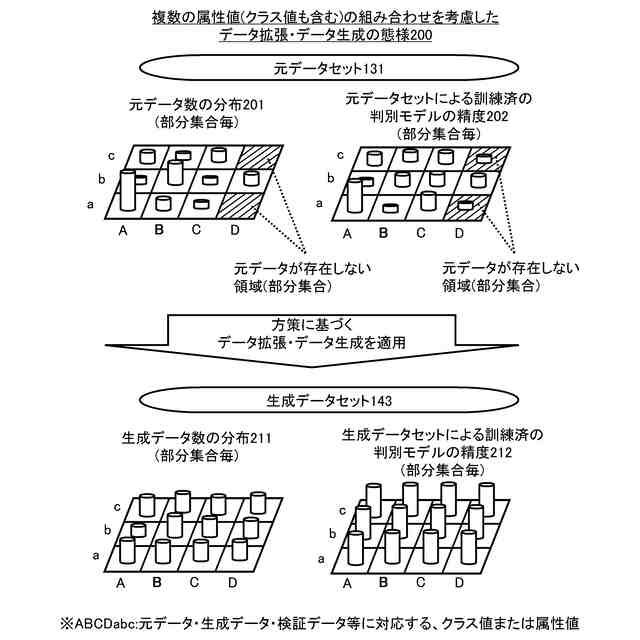
機械学習により訓練されるモデルは、複数の属性値(クラス値を含む。)の組み合わせを有するデータを取り扱うことがある。
例えば、画像データに含まれる物の種類を示すクラス(例えば、車、人、動物(例.犬、猫、馬)、非生物(例.ボール)のそれぞれを示すクラス)を判別するための判別モデル(分類モデル、識別モデル)では、当該判別モデルが取り扱う画像データのそれぞれは、複数の属性値(クラス値を含む。)の組み合わせを有し得る。具体的には、判別モデルが取り扱う画像データは、クラスの判別対象の物(例えば、車、人、動物(例.犬、猫、馬)、非生物(例.ボール))の種類を示すクラス値を有するとともに、クラス値とはならない属性値を有することがあり得る。ここで、クラス値とはならない属性値は、例えば、クラスの判別対象の物の(クラスよりも細かい)詳細な種類・形状・大きさ・色を示す属性値や、クラスの判別対象ではない物(例えば、背景)の種類(例えば、道路・庭・空)・形状・大きさ・色を示す属性値であり得る。例えば、「白い道を走る黒い車」を示す画像データは、属性値として、クラス値である「車」と、クラス値以外の属性値である「車の色としての黒色」「背景としての道」「道の色としての白色」の組み合わせを有する。また、例えば、「灰色の道を走る黒い車」を示す画像データは、属性値として、クラス値である「車」と、クラス値以外の属性値である「車の色としての黒色」「背景としての道」「道の色としての灰色」の組み合わせを有する。
以上は、画像データを取り扱う判別モデルの例であったが、他にも、例えば、音声データを取り扱う判別モデルでも同様のことがあり得る。例えば、判別モデルが取り扱う音声データにおいて、人が発する音声が示す内容がクラス値として扱われ、それ以外(例えば、音声の大きさ・音声の波長・音声以外の音(例えば、音楽や雑音)の大きさ・音声以外の音の波長)がクラス値以外の属性値として扱われることがあり得る。以下では、例えば、画像データや音声データ等の、テキストデータ形式以外のデータの形式は「元データ形式」と呼ばれることがある。
【0006】
複数の属性値(クラス値を含む。)の組み合わせを有する元データ形式のデータを取り扱うモデルの品質(精度)を高めるためには、当該モデルのための学習データセットにおいて、複数の属性値(クラス値を含む。)の組み合わせのそれぞれの学習データの数をある程度以上存在させるとともに、当該組み合わせ間の学習データの数を均衡させることが有用である。または、学習データセットにおいて、複数の属性値(クラス値を含む。)の組み合わせ間の学習データの数に不均衡があるとしても、当該組み合わせ間で(学習データにより訓練される)モデルが提供する品質(精度)をある程度均衡させることが有用である。つまり、複数の属性値(クラス値を含む。)の組み合わせのうち、特定の組み合わせを有するデータについて、モデルの品質(精度)が許容出来ない程度に低くならないようになっていることが有用である。
例えば、画像データのクラスを判別する判別モデルを訓練するための学習データセットにおいて、クラス値(例えば、車、人、動物(例.犬、猫、馬)、非生物(例.ボール)のいずれかを示す値)のそれぞれに対する学習データが充分存在することだけでは、訓練後の判別モデルによるクラスの判別精度が充分にならないことがあり得る。例えば、車が含まれる画像データが入力された判別モデルが「車」というクラスを判別出来るように、判別モデルを訓練することを想定する。この想定においては、車が含まれる画像データである学習データとして、車の色・背景にあるもの(例えば、道、庭・空)・背景の色といった(クラス値ではない)様々な属性値を有する学習データを満遍なく取り揃えることが有用である。取り揃えが不十分であると、学習データの数が不十分な属性値(クラス値を含む。)の組み合わせについて、判別モデルによるクラスの判別精度が低くなることがあり得る。例えば、「黒い道を走る白い車」を示す画像データが判別モデルに入力されると「車」というクラスを正しく判別出来る反面、「白い道を走る黒い車」を示す画像データが判別モデルに入力されても「車」というクラスを正しく判別出来ないことがあり得る。
【0007】
しかしながら、モデルで取り扱われるデータや、モデルを機械学習により訓練するための学習データが、複数の属性値(クラス値を含む。)の組み合わせを有する元データ形式のデータ(例えば、画像データや音声データ)である場合に、従来から知られている学習データセットを編集する技術は適したものとはなっていない。
例えば、非特許文献1に開示された技術は、学習データである画像データを編集する(データ拡張する)ことにより、新たな学習データである新たな画像データを生成するものである。非特許文献1に開示された技術は、自動的なデータ拡張(AutoAugment)を用いて、画像データのクラスを判別する(画像データを分類する)精度を向上させようとはしている。しかしながら、非特許文献1に開示された技術においては、画像データが有するクラス値以外の属性値への配慮に乏しい。つまり、非特許文献1に開示された技術においては、複数の属性値(クラス値を含む。)の組み合わせのそれぞれについて、学習データの数をある程度以上存在させるとともに、当該組み合わせ間の学習データの数を均衡させるか、または、当該組み合わせ間で、(学習データにより訓練される)モデルが提供する品質(精度)をある程度均衡させることへの配慮に乏しい。
また、非特許文献2に開示された技術は、学習データであるテキストデータ形式のデータを編集する(データ拡張する)ことにより、新たな学習データである新たなテキストデータ形式のデータを生成するものである。非特許文献2に開示された技術では、モデルで取り扱われるデータや、モデルを機械学習により訓練するための学習データが、終始、テキストデータ形式のデータである。つまり、非特許文献2に開示された技術は、例えば、画像データや音声データといった、(テキストデータ形式以外の形式である)元データ形式のデータを取り扱うものではない。また、非特許文献2に開示された技術は、テキストデータにおける自動的なデータ拡張(Text AutoAugment)を行うにあたって、複数の属性値(クラス値を含む。)の組み合わせのそれぞれについて、学習データの数をある程度以上存在させるとともに、当該組み合わせ間の学習データの数を均衡させるか、または、当該組み合わせ間で、(学習データにより訓練される)モデルが提供する品質(精度)をある程度均衡させることへの配慮に乏しい。
【0008】
以上を踏まえて、モデルで取り扱われるデータの形式や、モデルを機械学習により訓練するための学習データの形式が、(テキストデータ形式以外の形式である)元データ形式である場合において、モデルの品質(精度)を向上させるように学習データセットを編集することを、本開示の目的の1つとしてよい。
【課題を解決するための手段】
【0009】
上記目的のうちの少なくとも1つを達成するために、本開示が備えうる特徴は、例えば次のとおりである。
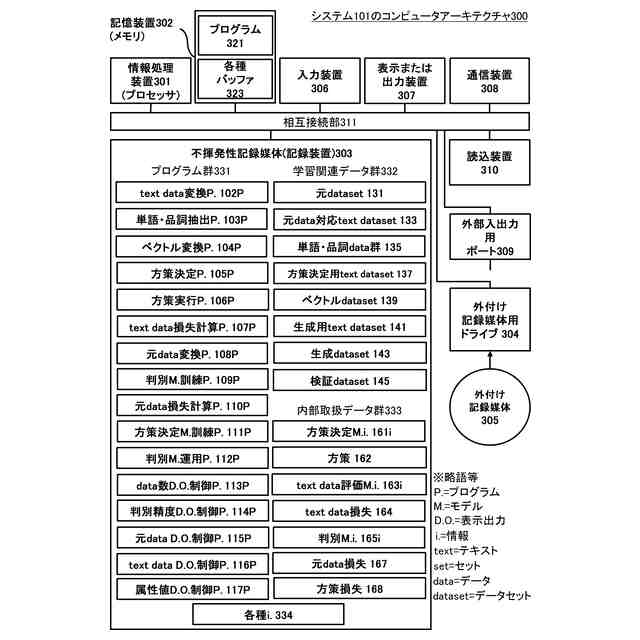
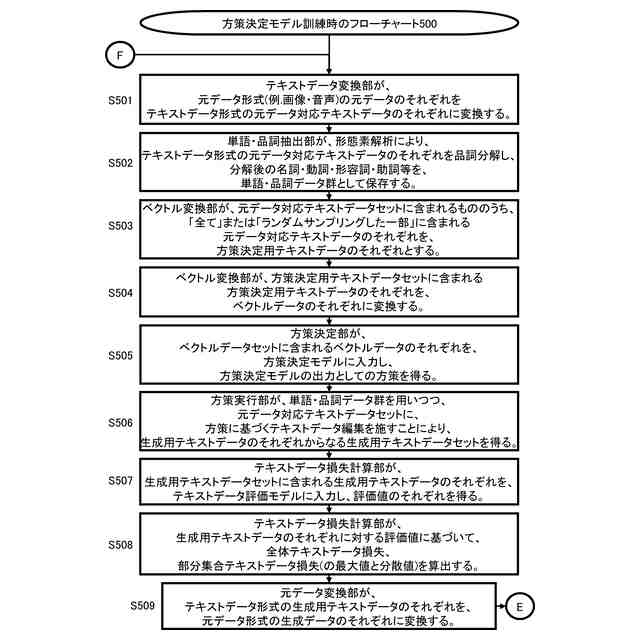
本開示の1つは、システムである。システムは、テキストデータ変換部と方策決定部と方策実行部と元データ変換部を有する。テキストデータ変換部は、元データセットに含まれる元データ形式の元データのそれぞれを、テキストデータ形式の元データ対応テキストデータのそれぞれに変換する。方策決定部は、元データ対応テキストデータのそれぞれからなる元データ対応テキストデータセットと、方策決定モデルに基づいて、元データ対応テキストデータセットに適用される方策を生成する。方策実行部は、方策に基づいて、元データ対応テキストデータセットを編集して、生成用テキストデータのセットである生成用テキストデータセットを生成する。元データ変換部は、生成用テキストデータセットに含まれる生成用テキストデータのそれぞれを、元データ形式の生成データのそれぞれに変換する。生成データは、元データ形式のデータのクラスを判別する判別モデルを機械学習により訓練するための学習データである。
【発明の効果】
【0010】
本開示は、モデルを機械学習により訓練するための学習データである元データ形式の生成データ(セット)を生成するに際して、元データ形式の元データをテキストデータ形式の元データ対応テキストデータ(セット)に変換した上で、元データ対応テキストデータ(セット)に対してテキストデータ編集を行う。その上で、本開示は、テキストデータ形式の生成用テキストデータ(セット)を元データ形式の生成データ(セット)に変換する。つまり、本開示は、学習データの実質的な編集処理を、元データ形式のままで行うのではなく、テキストデータ形式に変換してから行う。
ここで、データが有する属性値(クラス値を含む。)の組み合わせの情報が編集される際に、当該データが元データ形式のままで編集処理が行われるよりは、当該データがテキストデータ形式にされた上で編集処理が行われるほうが、意図どおりの編集、柔軟な編集、または、的確な編集が実現されやすい。つまり、本開示は、元データ形式のデータを取り扱うモデルのための学習データであったとしても、学習データが有する属性値(クラス値を含む。)の組み合わせの情報に対して、意図どおりの編集、柔軟な編集、または、的確な編集を行うことが出来る。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
対話装置
15日前
個人
物品給付年金
1か月前
個人
政治のAI化
1か月前
個人
情報処理装置
15日前
個人
記入設定プラグイン
3日前
個人
情報処理装置
11日前
個人
プラグインホームページ
29日前
個人
情報入力装置
15日前
キヤノン株式会社
通信装置
1か月前
個人
物価スライド機能付生命保険
15日前
個人
マイホーム非電子入札システム
15日前
株式会社BONNOU
管理装置
8日前
キヤノン株式会社
画像処理装置
1か月前
個人
全アルゴリズム対応型プログラム
1か月前
個人
決済手数料0%のクレジットカード
18日前
シャープ株式会社
電子機器
1か月前
サクサ株式会社
カードの制動構造
17日前
大同特殊鋼株式会社
輝線検出方法
1か月前
パテントフレア株式会社
交差型バーコード
1か月前
株式会社アジラ
データ転送システム
1か月前
村田機械株式会社
割当補助システム
21日前
株式会社ライト
情報処理装置
8日前
ミサワホーム株式会社
宅配ロッカー
1か月前
トヨタ自動車株式会社
情報処理装置
21日前
トヨタ自動車株式会社
欠け検査装置
1か月前
ミサワホーム株式会社
情報処理装置
1か月前
応研株式会社
業務支援システム
29日前
住友重機械工業株式会社
力覚伝達装置
10日前
オベック実業株式会社
端末用スタンド
1か月前
トヨタ自動車株式会社
管理装置
1か月前
Sansan株式会社
組織図生成装置
24日前
個人
システム、データおよびプログラム
4日前
個人
株管理システム
1か月前
シャープ株式会社
通信装置
28日前
株式会社半導体エネルギー研究所
会計システム
1日前
株式会社カプコン
データおよびシステム
1か月前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ