TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025071488
公報種別
公開特許公報(A)
公開日
2025-05-08
出願番号
2023181692
出願日
2023-10-23
発明の名称
音声認識装置およびプログラム
出願人
日本放送協会
代理人
個人
,
個人
,
個人
,
個人
主分類
G10L
15/16 20060101AFI20250428BHJP(楽器;音響)
要約
【課題】再学習を必要とせずに未知語の認識を可能とするための音声認識装置およびプログラムを提供する。
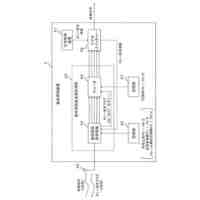
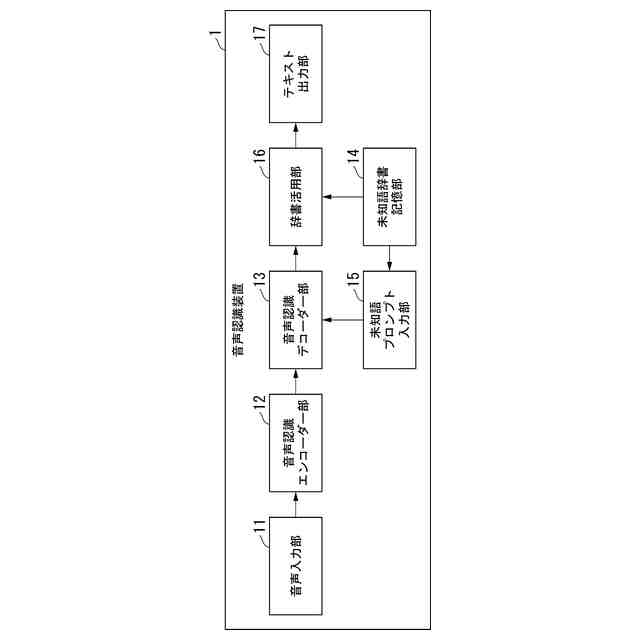
【解決手段】未知語辞書記憶部は、未知語に関して音声表現記号列と認識結果出力用記号列との対応関係を表す辞書データを記憶する。未知語プロンプト入力部は、前記未知語辞書記憶部に記憶された前記辞書データを参照することにより、未知語に関する音声表現記号列を含んだプロンプトを生成して出力する。音声認識デコーダー部は、音声認識エンコーダー部から出力されるエンコード結果情報と、前記プロンプトとに基づき、認識結果テキストを求めて出力する。辞書活用部は、前記認識結果テキストに未知語箇所であることを表す特殊トークンが含まれる場合に、前記認識結果テキスト内の当該特殊トークンの箇所を、辞書データから取得した認識結果出力用記号列で置換する。
【選択図】図1
特許請求の範囲
【請求項1】
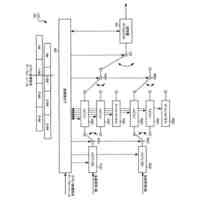
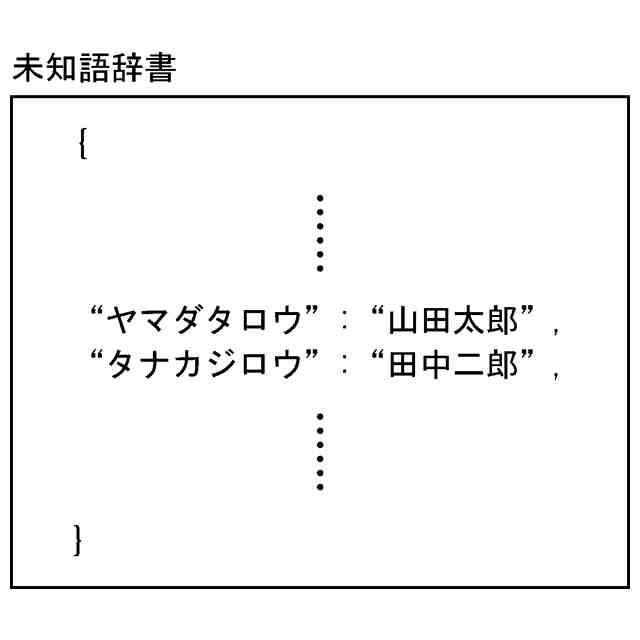
未知語に関して音声表現記号列と認識結果出力用記号列との対応関係を表す辞書データを記憶する未知語辞書記憶部と、
前記未知語辞書記憶部に記憶された前記辞書データを参照することにより、未知語に関する音声表現記号列を含んだプロンプトを生成して出力する未知語プロンプト入力部と、
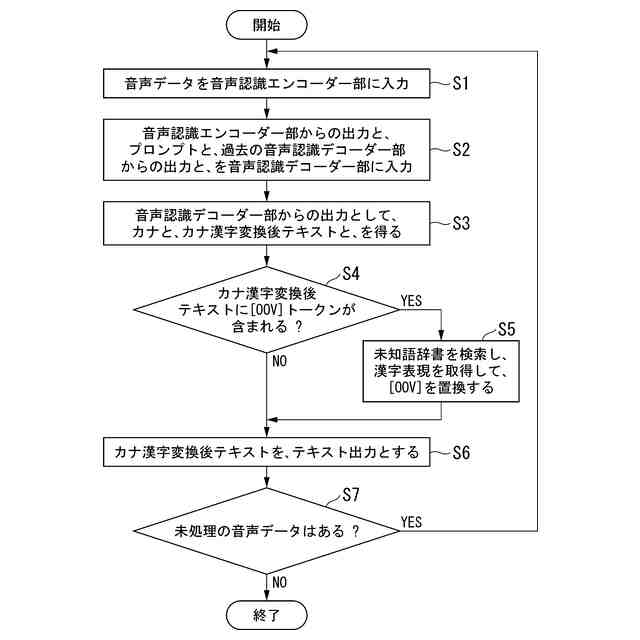
音声を入力して前記音声に対応するエンコード結果情報を出力する音声認識エンコーダー部と、
前記音声認識エンコーダー部から出力される前記エンコード結果情報と、前記未知語プロンプト入力部から渡される前記プロンプトとに基づき、認識結果テキストを求めて出力する音声認識デコーダー部と、
前記音声認識デコーダー部から出力される前記認識結果テキストに未知語箇所であることを表す特殊トークンが含まれる場合に、前記未知語辞書記憶部が記憶する前記辞書データを参照することにより、当該特殊トークンに対応する認識結果出力用記号列を取得し、前記認識結果テキスト内の当該特殊トークンの箇所を当該認識結果出力用記号列で置換する辞書活用部と、
を備える音声認識装置。
続きを表示(約 1,900 文字)
【請求項2】
前記音声認識エンコーダー部および前記音声認識デコーダー部はそれぞれニューラルネットワークを用いて構成され、学習データに基づいて、前記音声認識エンコーダー部および前記音声認識デコーダー部のそれぞれが持つ内部パラメーターの値を更新できるように構成した、
請求項1に記載の音声認識装置。
【請求項3】
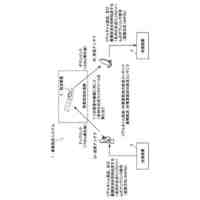
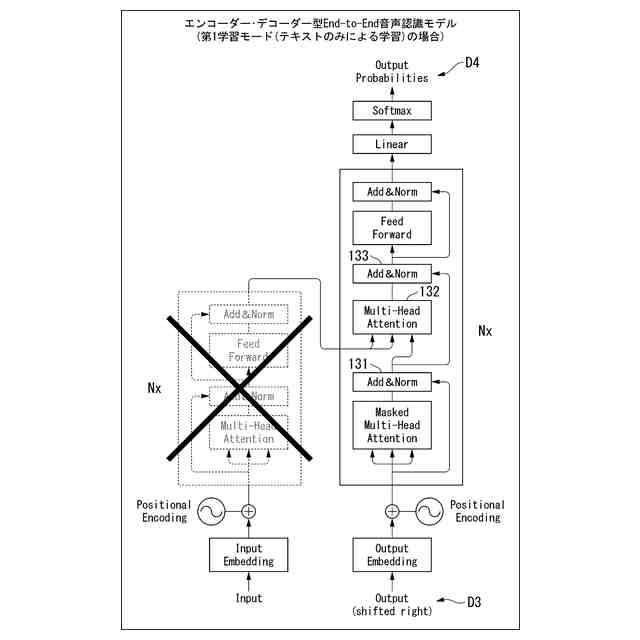
第1学習モードにおいて、
前記音声認識デコーダー部に対して入力する音声表現記号列と、前記音声認識デコーダー部からの出力の正解である認識結果出力用記号列と、の対の集合を学習データとして使用して学習を行うものであり、
前記音声認識デコーダー部に対して未知語プロンプト入力部から渡されるプロンプトがない場合には、正解の認識結果出力用記号列は未知語箇所であることを表す特殊トークンを含まず、
前記音声認識デコーダー部に対して未知語プロンプト入力部から渡されるプロンプトがある場合で且つ前記音声認識デコーダー部に対して入力する音声表現記号列が当該プロンプトに対応する語を含む場合には、正解の認識結果出力用記号列は未知語箇所であることを表す特殊トークンを含み、
前記音声認識デコーダー部に対して未知語プロンプト入力部から渡されるプロンプトがある場合で且つ前記音声認識デコーダー部に対して入力する音声表現記号列が当該プロンプトに対応する語を含まない場合には、正解の認識結果出力用記号列は未知語箇所であることを表す特殊トークンを含まない、
請求項2に記載の音声認識装置。
【請求項4】
第2学習モードにおいて、
前記音声認識エンコーダー部に対して入力する音声と、前記音声認識デコーダー部からの出力の正解である前記認識結果テキストと、の対の集合を学習データとして使用して学習を行うものであり、
前記認識結果テキストは、前記音声表現記号列と前記認識結果出力用記号列のペアである、
請求項3に記載の音声認識装置。
【請求項5】
前記未知語辞書記憶部が記憶する前記辞書データは、複数の未知語に関して音声表現記号列と認識結果出力用記号列との対応関係を表すものであり、
前記未知語プロンプト入力部は、前記複数の未知語のそれぞれに特有の前記特殊トークンと関連付けた前記プロンプトを生成して出力するものであり、
前記音声認識デコーダー部は、前記未知語プロンプト入力部から渡される前記プロンプトに基づき、認識結果テキストを求めて出力するものであり、
前記辞書活用部は、前記音声認識デコーダー部から出力される前記認識結果テキストに未知語箇所であることを表す特殊トークンが含まれる場合に、当該特殊トークンが前記複数の未知語のうちのどの未知語に対応するものであるかを識別して前記辞書データを参照することにより、当該特殊トークンに対応する認識結果出力用記号列を取得し、前記認識結果テキスト内の当該特殊トークンの箇所を当該認識結果出力用記号列で置換する
請求項1に記載の音声認識装置。
【請求項6】
前記複数の未知語のそれぞれに特有の前記特殊トークンは、前記辞書データにおける特定の未知語の位置を表すインデックス値の情報を含むものである、
請求項5に記載の音声認識装置。
【請求項7】
未知語に関して音声表現記号列と認識結果出力用記号列との対応関係を表す辞書データを記憶する未知語辞書記憶部と、
前記未知語辞書記憶部に記憶された前記辞書データを参照することにより、未知語に関する音声表現記号列を含んだプロンプトを生成して出力する未知語プロンプト入力部と、
音声を入力して前記音声に対応するエンコード結果情報を出力する音声認識エンコーダー部と、
前記音声認識エンコーダー部から出力される前記エンコード結果情報と、前記未知語プロンプト入力部から渡される前記プロンプトとに基づき、認識結果テキストを求めて出力する音声認識デコーダー部と、
前記音声認識デコーダー部から出力される前記認識結果テキストに未知語箇所であることを表す特殊トークンが含まれる場合に、前記未知語辞書記憶部が記憶する前記辞書データを参照することにより、当該特殊トークンに対応する認識結果出力用記号列を取得し、前記認識結果テキスト内の当該特殊トークンの箇所を当該認識結果出力用記号列で置換する辞書活用部と、
を備える音声認識装置、としてコンピューターを機能させるプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識装置およびプログラムに関する。
続きを表示(約 2,200 文字)
【背景技術】
【0002】
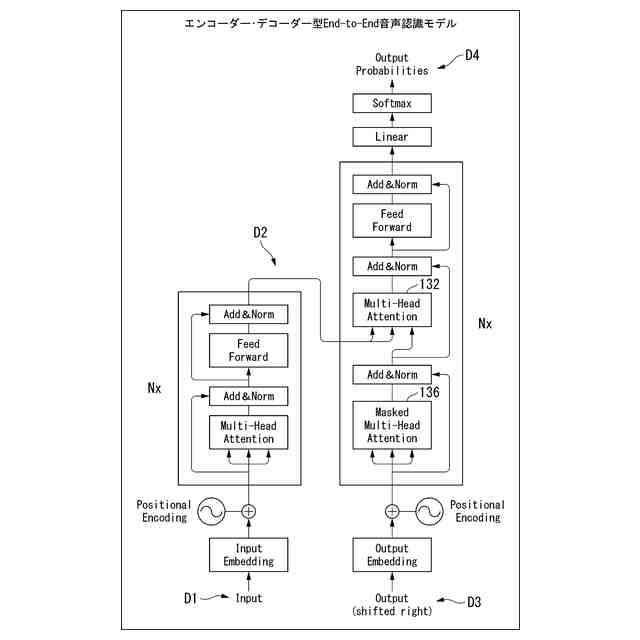
ニューラルネットワークを用いたEnd-to-Endな音声認識では、単一の深層学習モデルによって入力と出力をつなぐような、非常にシンプルな構造のネットワークを構成する。この1つシンプルな構造のモデルの学習を行うことにより、入力と出力との間の関係に基づくタスクを実現することができる。つまり、音響モデルや言語モデルなどといった複数のモデルから成る従来の音声認識の手法と比べて、シンプルに装置を構成することができる。なお、End-to-Endな音声認識では、あらかじめ正解語彙を規定して学習を行う。
【0003】
非特許文献1には、大規模言語モデルを用いて行うニューラル機械翻訳の処理において、翻訳前言語(ソース言語)における表現と、翻訳後言語(ターゲット言語)における表現の関係(例:“Japan means 日本”)をプロンプトとして与える技術が開示されている。この非特許文献1の技術を用いることにより、言語翻訳の精度が向上するとされている。
【0004】
非特許文献2では、ドメイン固有のテキストプロンプトを用いることにより、特定ドメインにおける音声認識の精度を向上させるドメイン適応法が提案されている。
【0005】
非特許文献3には、End-to-Endな音声認識の技術について記載されている。
【先行技術文献】
【非特許文献】
【0006】
Hongyuan Lu,Haoyang Huang,Dongdong Zhang,Haoran Yang,Wai Lam,Furu Wei,“Chain-of-Dictionary Prompting Elicits Translation in Large Language Models”,arXiv:2305.06575v3 [cs.CL],24 May 2023.
Yuang Li,Yu Wu,Jinyu Li,Shujie Liu,“PROMPTING LARGE LANGUAGE MODELS FOR ZERO-SHOT DOMAIN ADAPTATION IN SPEECH RECOGNITION”,arXiv:2306.16007v1 [cs.CL],28 Jun 2023.
記事「End-to-Endな音声認識」,URL https://olaris.jp/poststag/Ds00Wfma,2021年11月19日.
【発明の概要】
【発明が解決しようとする課題】
【0007】
End-to-Endな音声認識処理の、あらかじめ正解語彙を規定して学習を行うという特徴により、学習時に登場しなかった未知語(例えば、人名や地名等)が推論時に出てきてしまった場合、正しく認識できないケースが多い。しかしながら、音声認識処理を行う場面によっては、人名や地名等が特に間違いの許されない重要な認識対象である場合もある。End-to-Endな処理であるがゆえに、新語彙を追加するための学習をさせようと試みると、ニューラルネットワークの膨大な内部パラメーターの再学習に多大な計算コストを要する。また、既に行われた学習のときに得られた認識能力を著しく欠損する恐れもある。
【0008】
本発明は、上記の課題認識に基づいて行なわれたものであり、膨大な再学習を必要とせずに未知語の認識を可能とするための音声認識装置およびプログラムを提供しようとするものである。
【課題を解決するための手段】
【0009】
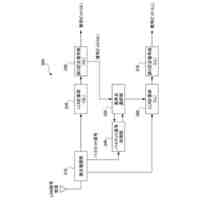
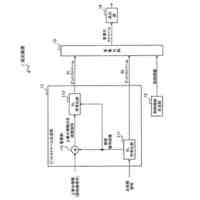
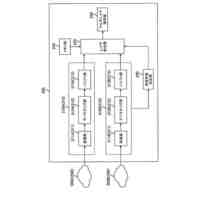
[1]上記の課題を解決するため、本発明の一態様による音声認識装置は、未知語に関して音声表現記号列と認識結果出力用記号列との対応関係を表す辞書データを記憶する未知語辞書記憶部と、前記未知語辞書記憶部に記憶された前記辞書データを参照することにより、未知語に関する音声表現記号列を含んだプロンプトを生成して出力する未知語プロンプト入力部と、音声を入力して前記音声に対応するエンコード結果情報を出力する音声認識エンコーダー部と、前記音声認識エンコーダー部から出力される前記エンコード結果情報と、前記未知語プロンプト入力部から渡される前記プロンプトとに基づき、認識結果テキストを求めて出力する音声認識デコーダー部と、前記音声認識デコーダー部から出力される前記認識結果テキストに未知語箇所であることを表す特殊トークンが含まれる場合に、前記未知語辞書記憶部が記憶する前記辞書データを参照することにより、当該特殊トークンに対応する認識結果出力用記号列を取得し、前記認識結果テキスト内の当該特殊トークンの箇所を当該認識結果出力用記号列で置換する辞書活用部と、を備えるものである。
【0010】
[2]また、本発明の一態様は、上記[1]の音声認識装置において、前記音声認識エンコーダー部および前記音声認識デコーダー部はそれぞれニューラルネットワークを用いて構成され、学習データに基づいて、前記音声認識エンコーダー部および前記音声認識デコーダー部のそれぞれが持つ内部パラメーターの値を更新できるように構成したものである。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
日本放送協会
撮像装置
6か月前
日本放送協会
配線構造
2か月前
日本放送協会
液晶表示装置
10か月前
日本放送協会
マイクロホン
4か月前
日本放送協会
光学計測装置
4か月前
日本放送協会
無線通信装置
3か月前
日本放送協会
磁性細線メモリ
2か月前
日本放送協会
光制御デバイス
11か月前
日本放送協会
映像伝送システム
2か月前
日本放送協会
磁性細線デバイス
6か月前
日本放送協会
レンズアダプター
8か月前
日本放送協会
無線伝送システム
5か月前
日本放送協会
有機光電変換素子
11か月前
日本放送協会
角度選択フィルター
26日前
日本放送協会
垂直分離型撮像素子
10か月前
日本放送協会
データ管理システム
5か月前
日本放送協会
3次元映像表示装置
2か月前
日本放送協会
良撮影位置推定装置
1か月前
日本放送協会
撮像素子及び撮像装置
11か月前
日本放送協会
受信装置及び送出装置
7か月前
日本放送協会
送信装置及び受信装置
8か月前
日本放送協会
衛星放送受信システム
8か月前
日本放送協会
送信装置及び受信装置
6か月前
日本放送協会
送信装置及び受信装置
8か月前
日本放送協会
送信装置及び受信装置
11か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
同軸切替器の着脱機構
9か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
11か月前
日本放送協会
送出装置及び受信装置
11か月前
日本放送協会
端末装置及びプログラム
7か月前
日本放送協会
磁壁移動型空間光変調器
7か月前
日本放送協会
受信装置及びプログラム
7か月前
日本放送協会
再生装置及びプログラム
9か月前
日本放送協会
受信装置及びプログラム
1か月前
日本放送協会
縮小装置及びプログラム
11か月前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ