TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025008226
公報種別
公開特許公報(A)
公開日
2025-01-20
出願番号
2023110203
出願日
2023-07-04
発明の名称
プログラム、情報処理装置及び情報処理方法
出願人
株式会社東芝
代理人
弁理士法人酒井国際特許事務所
主分類
G06T
7/00 20170101AFI20250109BHJP(計算;計数)
要約
【課題】画像に複数の対象物が含まれている場合でも、より少ない処理量で、より精度の高い処理結果を得る。
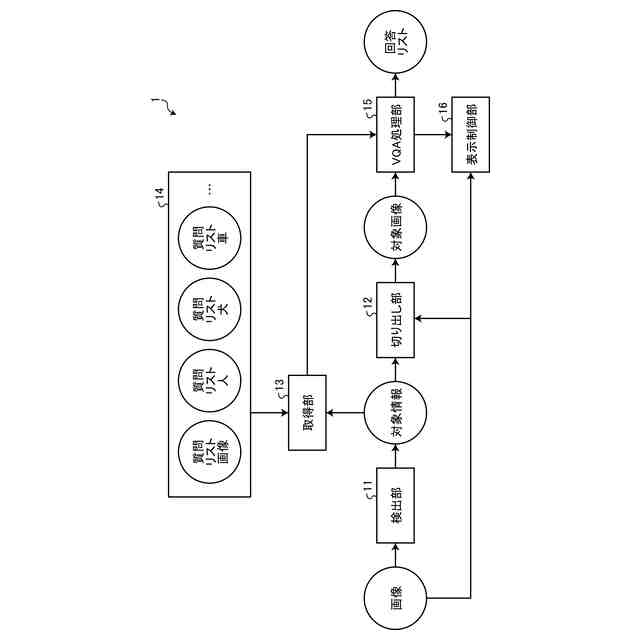
【解決手段】実施形態のプログラムは、コンピュータを、検出部と切り出し部と取得部とVQA処理部として機能させる。検出部は、画像から、検出対象を含む対象領域と、前記検出対象を識別する対象識別情報とを含む対象情報を、少なくとも1つ検出する。切り出し部は、前記画像から、少なくとも1つの前記対象領域を切り出すことによって、少なくとも1つの対象画像を生成する。取得部は、前記対象識別情報に応じた少なくとも1つの質問を取得する。VQA処理部は、前記少なくとも1つの対象画像毎に、前記少なくとも1つの質問によるVQA(Visual Question Answering)処理を実行する。
【選択図】図5
特許請求の範囲
【請求項1】
コンピュータを、
画像から、検出対象を含む対象領域と、前記検出対象を識別する対象識別情報とを含む対象情報を、少なくとも1つ検出する検出部と、
前記画像から、少なくとも1つの前記対象領域を切り出すことによって、少なくとも1つの対象画像を生成する切り出し部と、
前記対象識別情報に応じた少なくとも1つの質問を取得する取得部と、
前記少なくとも1つの対象画像毎に、前記少なくとも1つの質問によるVQA(Visual Question Answering)処理を実行するVQA処理部、
として機能させるためのプログラム。
続きを表示(約 1,700 文字)
【請求項2】
前記コンピュータは、
前記検出対象の種別を示す対象種別毎に、少なくとも1つの質問を記憶する記憶部を更に備え、
前記対象識別情報は、前記対象種別を示す情報を含み、
前記取得部は、前記対象識別情報に含まれる対象識別に応じた少なくとも1つの質問を、前記記憶部から取得する、
請求項1に記載のプログラム。
【請求項3】
前記検出部は、前記記憶部から読み出された対象種別の検出対象を含む対象領域と、前記対象識別情報とを含む対象情報を、前記画像から少なくとも1つ検出する、
請求項2に記載のプログラム。
【請求項4】
前記検出部は、前記画像に対する質問文をユーザーから受け付け、前記質問文から前記対象種別を特定し、特定された前記対象種別の検出対象を含む対象領域と、前記対象識別情報とを含む対象情報を、少なくとも1つ検出する、
請求項2又は3に記載のプログラム。
【請求項5】
前記コンピュータを、
前記対象領域を、前記対象種別及び前記質問の少なくとも一方に応じて変形する変形部、として更に機能させ、
前記切り出し部は、前記画像から、少なくとも1つの前記対象領域、または、前記変形部によって変形された少なくとも1つの前記対象領域を切り出すことによって、少なくとも1つの対象画像を生成する、
請求項2又は3に記載のプログラム。
【請求項6】
前記取得部は、前記対象画像毎に適用される少なくとも1つの質問に、質問識別情報を付与し、
前記VQA処理部は、前記対象識別情報と、前記質問識別情報と、前記質問識別情報により識別される質問の回答と、が関連付けられたVQA処理結果情報を出力する、
請求項1乃至3のいずれか1項に記載のプログラム。
【請求項7】
前記コンピュータを、
前記VQA処理結果情報が、前記VQA処理結果情報に含まれる前記対象識別情報によって識別される検出対象に付与された表示情報を、表示装置に表示する表示制御部、
として更に機能させる請求項6に記載のプログラム。
【請求項8】
前記画像は、動画に含まれるフレームであり、
前記検出部は、前記フレームから前記対象情報を少なくとも1つ検出し、
前記コンピュータを、
前記フレーム毎に生成された前記対象画像に、VQA処理を実行することによって得られた質問の回答を投票し、前記投票の結果に基づいて、前記対象画像毎の前記質問の回答を決定する投票部、
として更に機能させる請求項1乃至3のいずれか1項に記載のプログラム。
【請求項9】
画像から、検出対象を含む対象領域と、前記検出対象を識別する対象識別情報とを含む対象情報を、少なくとも1つ検出する検出部と、
前記画像から、少なくとも1つの前記対象領域を切り出すことによって、少なくとも1つの対象画像を生成する切り出し部と、
前記対象識別情報に応じた少なくとも1つの質問を取得する取得部と、
前記少なくとも1つの対象画像毎に、前記少なくとも1つの質問によるVQA(Visual Question Answering)処理を実行するVQA処理部と、
を備える情報処理装置。
【請求項10】
情報処理装置が、画像から、検出対象を含む対象領域と、前記検出対象を識別する対象識別情報とを含む対象情報を、少なくとも1つ検出するステップと、
前記情報処理装置が、前記画像から、少なくとも1つの前記対象領域を切り出すことによって、少なくとも1つの対象画像を生成するステップと、
前記情報処理装置が、前記対象識別情報に応じた少なくとも1つの質問を取得するステップと、
前記情報処理装置が、前記少なくとも1つの対象画像毎に、前記少なくとも1つの質問によるVQA(Visual Question Answering)処理を実行するステップと、
を含む情報処理方法。
発明の詳細な説明
【技術分野】
【0001】
本発明の実施形態はプログラム、情報処理装置及び情報処理方法に関する。
続きを表示(約 2,700 文字)
【背景技術】
【0002】
画像質問応答(Visual Question Answering:VQA)のAI(Artificial Intelligence)技術が従来から知られている。VQAは、一枚の画像と、当該画像に関連する質問と、が与えられた時に、正しい答えを返すタスクである。このタスクは、画像に関する知識、及び、テキストに関する知識、双方を正しく取り扱う必要のあるクロスモーダルなタスクとなっている。
【先行技術文献】
【非特許文献】
【0003】
GLIP BLIP,[online],[令和5年6月15日検索],インターネット〈URL:https://huggingface.co/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA>
Faster R-CNN,Girshick Ross,Proceedings of the IEEE international conference on computer vision. 2015
Visual Question Answering,[online],[令和5年6月15日検索],インターネット〈URL:https://visualqa.org/>
MSCOCO,[online],[令和5年6月15日検索],インターネット〈URL:https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/>
Anderson, Peter, et al. “Bottom-up and top-down attention for image captioning and visual question answering.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018
Gu,Xiuye,et al.“Open-vocabulary object detection via vision and language knowledge distillation.” arXiv preprint arXiv:2104.13921 (2021)
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、従来の技術では、画像に複数の対象物が含まれている場合に、より少ない処理量で、より精度の高い処理結果を得ることが難しかった。
【課題を解決するための手段】
【0005】
実施形態のプログラムは、コンピュータを、検出部と切り出し部と取得部とVQA処理部として機能させる。検出部は、画像から、検出対象を含む対象領域と、前記検出対象を識別する対象識別情報とを含む対象情報を、少なくとも1つ検出する。切り出し部は、前記画像から、少なくとも1つの前記対象領域を切り出すことによって、少なくとも1つの対象画像を生成する。取得部は、前記対象識別情報に応じた少なくとも1つの質問を取得する。VQA処理部は、前記少なくとも1つの対象画像毎に、前記少なくとも1つの質問によるVQA(Visual Question Answering)処理を実行する。
【図面の簡単な説明】
【0006】
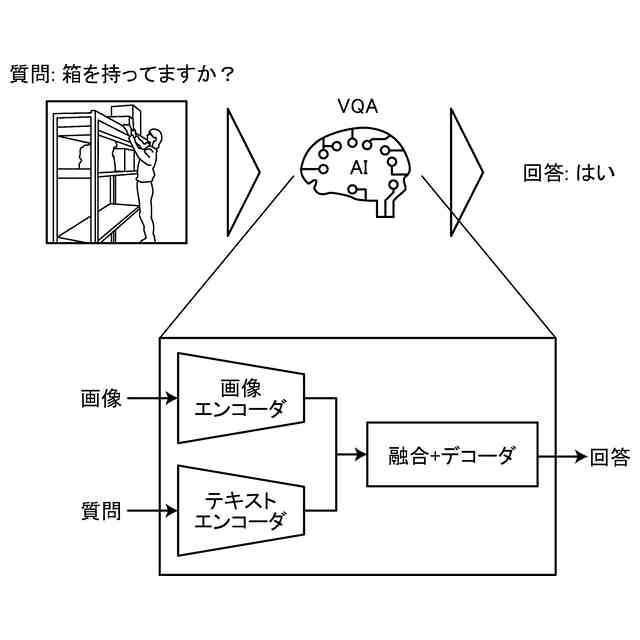
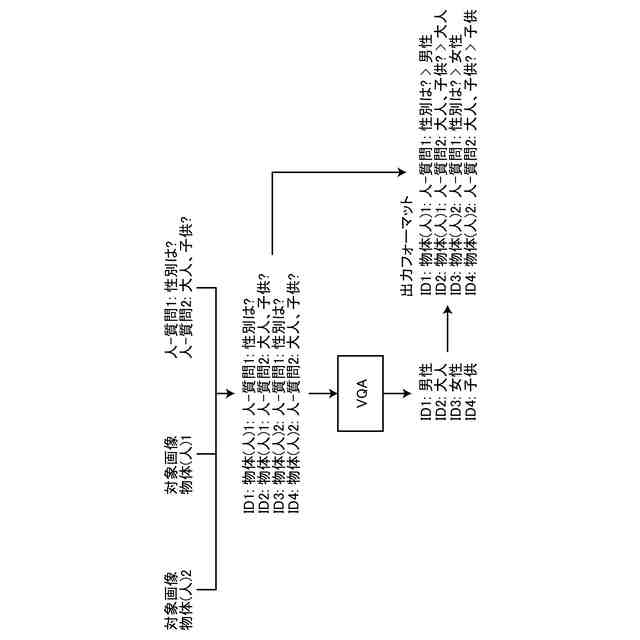
VQAの例を示す概略図。
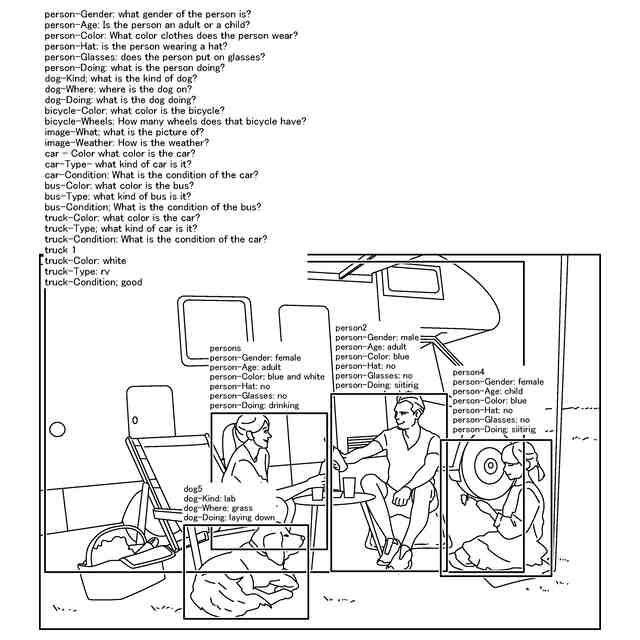
VQAを用いた画像解析システムの例を示す図。
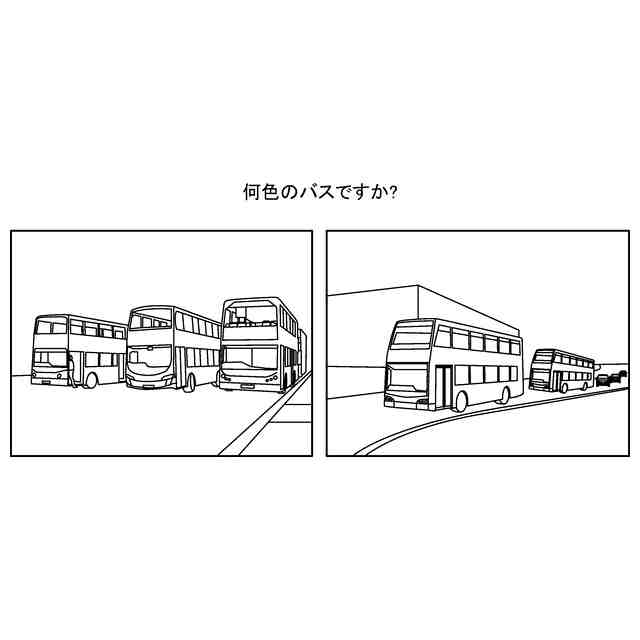
VQAの課題の例1を説明するための図。
VQAの課題の例2を説明するための図。
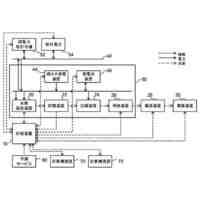
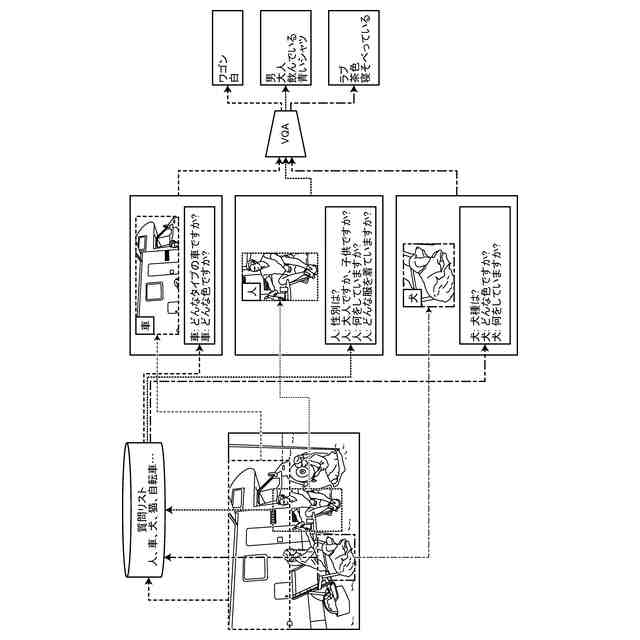
第1実施形態の情報処理装置の機能構成の例を示す図。
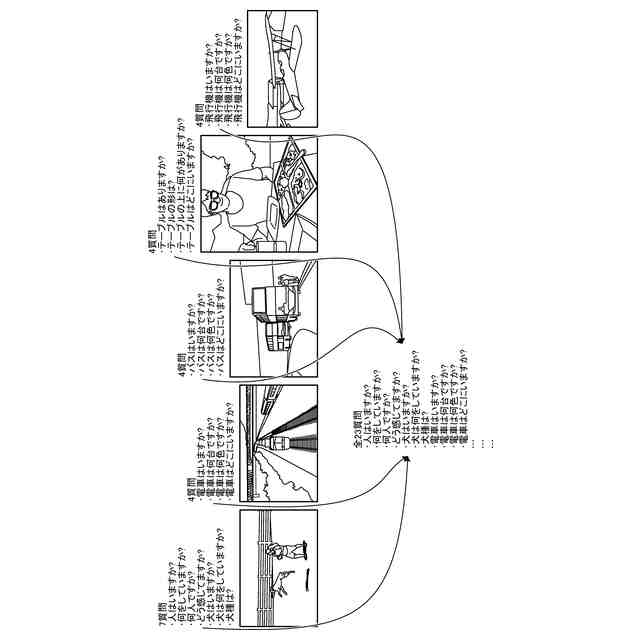
第1実施形態のVQA処理部の処理例を示す概要図。
第1実施形態の質問を識別する質問IDのフォーマットの例を示す図。
第1実施形態のVQA処理の概要を示す図。
第1実施形態の表示情報の例を示す図。
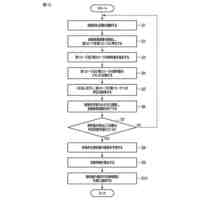
第1実施形態の情報処理方法の例を示すフローチャート。
第1実施形態による効果の例1について説明するための図。
第1実施形態による効果の例2について説明するための図。
第2実施形態の情報処理装置の機能構成の例を示す図。
第2実施形態の投票処理の例を示す概要図。
第2実施形態の投票数と認識精度との関係を示す図。
第2実施形態の情報処理方法の例を示すフローチャート。
第2実施形態のステップS18における投票処理の例を示すフローチャート。
第2実施形態のステップS18における確定処理の例を示すフローチャート。
第3実施形態の情報処理装置の機能構成の例を示す図。
第3実施形態の変形部の処理例を説明するための図。
第4実施形態の情報処理装置の機能構成の例を示す図。
第1乃至第5実施形態の情報処理装置のハードウェア構成の例を示す図。
【発明を実施するための形態】
【0007】
以下に添付図面を参照して、プログラム、情報処理装置及び情報処理方法の実施形態を詳細に説明する。
【0008】
(第1実施形態)
はじめに、VQAの概要について説明する。
【0009】
図1はVQAの例を示す概略図である。VQAは、任意の質問に応じて、画像から内容を判断し、回答するAIである。VQAの最大の特徴は、質問が自由形式の自然言語テキストで与えられることである。これにより、理論上、テキストで表現できる事柄ならば、あらゆることに対応できる汎用性の高さを持っている。
【0010】
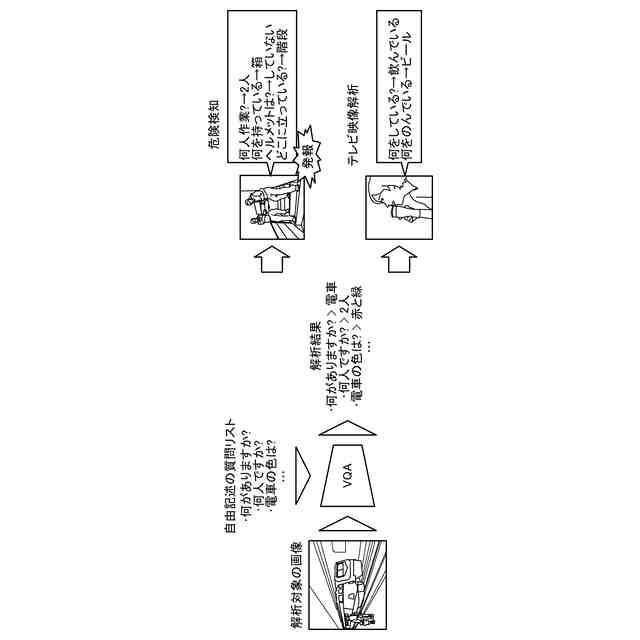
図2はVQAを用いた画像解析システムの例を示す図である。解析対象の画像に対して、事前に準備された質問リストを適用することで、あらゆる画像を解析可能なシステムを構築できる。例えば、図2に示すように、危険検知をするシステム(注意喚起の自動化システム)、及び、テレビ映像解析をするシステム(任意シーンの自動抽出システム)等が構築できる。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社東芝
弁
15日前
株式会社東芝
台車
1か月前
株式会社東芝
センサ
1か月前
株式会社東芝
センサ
1か月前
株式会社東芝
固定子
1か月前
株式会社東芝
回転電機
1か月前
株式会社東芝
計画装置
2か月前
株式会社東芝
開閉装置
1か月前
株式会社東芝
搬送装置
1か月前
株式会社東芝
遠心送風機
29日前
株式会社東芝
光スイッチ
1か月前
株式会社東芝
半導体装置
5日前
株式会社東芝
光デバイス
2か月前
株式会社東芝
直流遮断器
1か月前
株式会社東芝
駅務システム
2か月前
株式会社東芝
電力変換装置
14日前
株式会社東芝
対策提示装置
27日前
株式会社東芝
駆動システム
2か月前
株式会社東芝
電力変換装置
2か月前
株式会社東芝
電力変換装置
1か月前
株式会社東芝
ディスク装置
5日前
株式会社東芝
蓋の開閉装置
1か月前
株式会社東芝
紙葉類処理装置
28日前
株式会社東芝
電動機制御装置
1か月前
株式会社東芝
電気車制御装置
1か月前
株式会社東芝
潤滑油供給装置
1か月前
株式会社東芝
オゾン発生装置
2か月前
株式会社東芝
有価物回収方法
1か月前
株式会社東芝
電子計算機装置
27日前
株式会社東芝
磁気ディスク装置
1か月前
株式会社東芝
投込式水位伝送器
15日前
株式会社東芝
液体の貯蔵タンク
2か月前
株式会社東芝
積雪検出システム
1か月前
株式会社東芝
半導体モジュール
2日前
株式会社東芝
ガス絶縁開閉装置
2か月前
株式会社東芝
画像取得システム
1か月前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ