TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2024076437
公報種別
公開特許公報(A)
公開日
2024-06-06
出願番号
2022187934
出願日
2022-11-25
発明の名称
叫び声検知システム、音声分類方法、及び、音声分類モデルの生成方法
出願人
学校法人立命館
代理人
個人
主分類
G10L
15/10 20060101AFI20240530BHJP(楽器;音響)
要約
【課題】第1状況での第1叫び声を、第1状況とは異なる第2状況での第2叫び声とは区別して検知可能な、叫び声検知システムを提供する。
【解決手段】叫び声検知システム1は、入力音声の特徴量を取得する特徴取得器111と、特徴量に基づいて、入力音声を分類する音声分類モデル116と、を備え、音声分類モデルは、第1状況での第1叫び声を、第1状況とは異なる第2状況での第2叫び声とは区別して分類するよう構成されている。
【選択図】図1
特許請求の範囲
【請求項1】
入力音声の特徴量を取得する特徴取得器と、
前記特徴量に基づいて、前記入力音声を分類する音声分類モデルと、
を備え、
前記音声分類モデルは、第1状況での第1叫び声を、前記第1状況とは異なる第2状況での第2叫び声とは区別して分類するよう構成されている
叫び声検知システム。
続きを表示(約 1,200 文字)
【請求項2】
前記第1状況は、叫び声が発せられたときの危険度が前記第2状況とは異なる状況である
請求項1に記載の叫び声検知システム。
【請求項3】
前記第1状況は、叫び声が発せられたときの危険度が前記第2状況よりも高い状況である
請求項1に記載の叫び声検知システム。
【請求項4】
前記特徴取得器は、少なくとも、前記入力音声の音声特徴量を取得するよう構成され、
前記音声分類モデルは、少なくとも前記音声特徴量に基づいて、前記第1叫び声を前記第2叫び声とは区別して分類するよう構成されている
請求項1に記載の叫び声検知システム。
【請求項5】
前記特徴取得器は、前記入力音声を音声認識して得られる言語の言語特徴量を更に取得するよう構成され、
前記音声分類モデルは、前記音声特徴量及び前記言語特徴量に基づいて、前記第1叫び声を前記第2叫び声とは区別して分類するよう構成されている
請求項4に記載の叫び声検知システム。
【請求項6】
前記音声分類モデルは、前記第1叫び声と、前記第2叫び声と、平静音声と、を区別して分類するよう構成されている
請求項1に記載の叫び声検知システム。
【請求項7】
前記音声分類モデルは、第1状況での第1叫び声を、前記第1状況とは異なる第2状況での第2叫び声とは区別して分類するための機械学習が行われた学習モデルである
請求項1に記載の叫び声検知システム。
【請求項8】
前記学習モデルは、前記第1状況での叫び声である第1学習用音声及び前記第2状況での叫び声である第2学習用音声を含む複数の学習用音声それぞれの特徴量と、前記複数の学習用音声それぞれの分類と、を学習データとして機械学習されている
請求項7に記載の叫び声検知システム。
【請求項9】
入力音声の特徴量を求め、
前記特徴量に基づいて前記入力音声を分類する音声分類モデルに、前記特徴量を与えて、前記入力音声の分類結果を得る、
ことを備え、
前記音声分類モデルは、第1状況での第1叫び声を、前記第1状況とは異なる第2状況での第2叫び声とは区別して分類するよう構成されている
コンピュータに実装された音声分類方法。
【請求項10】
第1状況での叫び声である第1学習用音声及び前記第1状況とは異なる第2状況での叫び声である第2学習用音声を含む複数の学習用音声それぞれの特徴量と、前記複数の学習用音声それぞれの分類と、を学習データとして機械学習することによって、前記第1状況での叫び声を、前記第2状況での叫び声とは区別して分類するための音声分類モデルを得る、ことを備える
音声分類モデルの生成方法。
発明の詳細な説明
【技術分野】
【0001】
本開示は、叫び声検知システム、音声分類方法、及び、音声分類モデルの生成方法に関する。
続きを表示(約 1,300 文字)
【背景技術】
【0002】
特開2011-53557号公報(以下、特許文献1)に開示されているように、従来の検出装置は、受け付けた音声信号が悲鳴であるか否かを検出するものであった。
【先行技術文献】
【特許文献】
【0003】
特開2011-53557号公報
【発明の概要】
【0004】
人の叫び声には、驚いた状況での叫び声、歓声、助けを求める叫び声、など、状況によって異なる場合がある。しかしながら、特許文献1のような従来の検出装置では、状況の異なる叫び声も一律に「悲鳴」として検出されてしまう。本開示は、第1状況での第1叫び声を、第1状況とは異なる第2状況での第2叫び声とは区別して検知可能な、叫び声検知システム、音声分類方法、及び、音声分類モデルの生成方法を提供することを目的の1つとする。
【0005】
ある実施の形態に従うと、叫び声検知システムは、入力音声の特徴量を取得する特徴取得器と、特徴量に基づいて、入力音声を分類する音声分類モデルと、を備え、音声分類モデルは、第1状況での第1叫び声を、第1状況とは異なる第2状況での第2叫び声とは区別して分類するよう構成されている。
【0006】
ある実施の形態に従うと、音声分類方法は、入力音声の特徴量を求め、特徴量に基づいて入力音声を分類する音声分類モデルに、特徴量を与えて、入力音声の分類結果を得る、ことを備え、音声分類モデルは、第1状況での第1叫び声を、第1状況とは異なる第2状況での第2叫び声とは区別して分類するよう構成されている。
【0007】
ある実施の形態に従うと、音声分類モデルの生成方法は、第1状況での叫び声である第1学習用音声及び第1状況とは異なる第2状況での叫び声である第2学習用音声を含む複数の学習用音声それぞれの特徴量と、複数の学習用音声それぞれの分類と、を学習データとして機械学習することによって、第1状況での叫び声を、第2状況での叫び声とは区別して分類するための音声分類モデルを得る、ことを備える。
【0008】
更なる詳細は、後述の実施形態として説明される。
【図面の簡単な説明】
【0009】
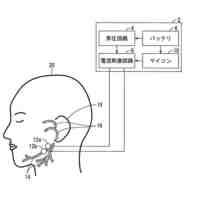
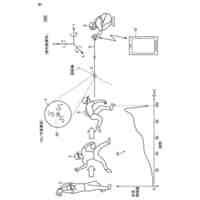
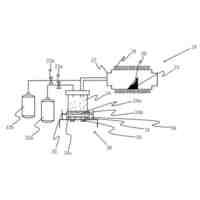
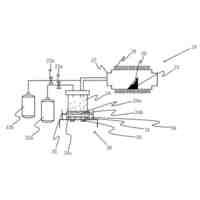
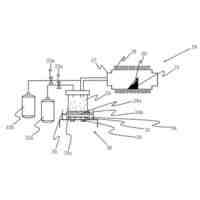
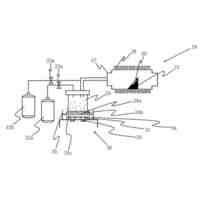
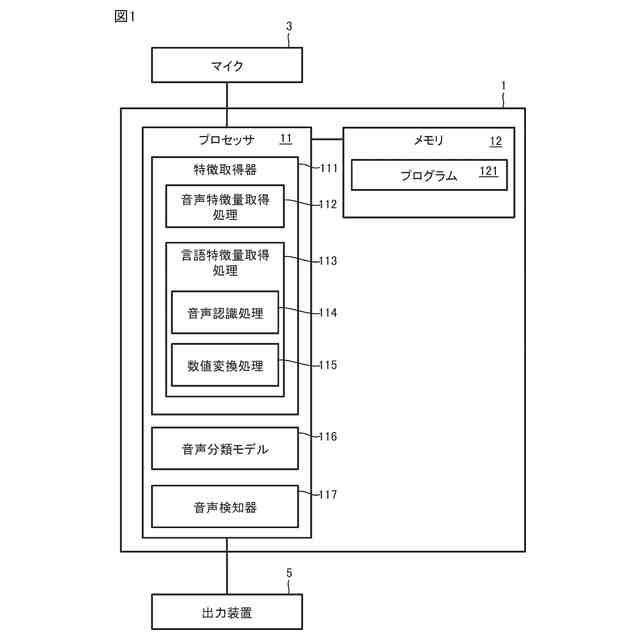
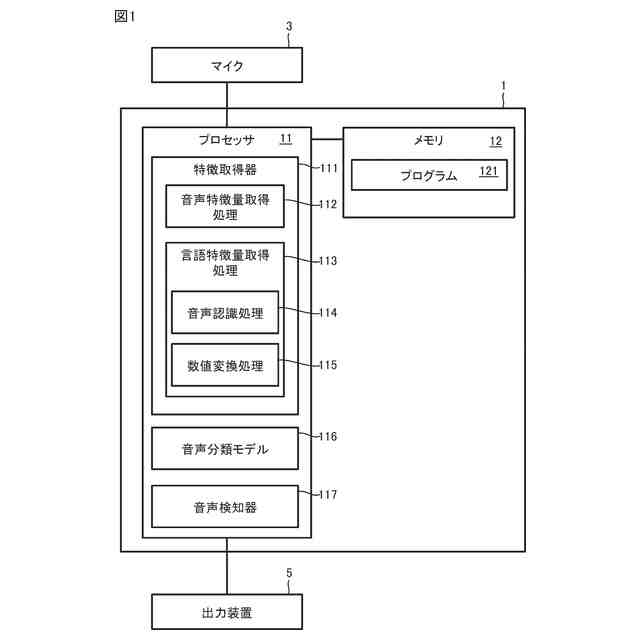
図1は、実施の形態に係る叫び声検知システム(以下、システムと略する)の概略図である。
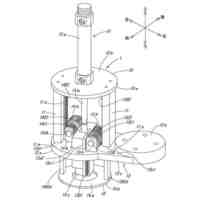
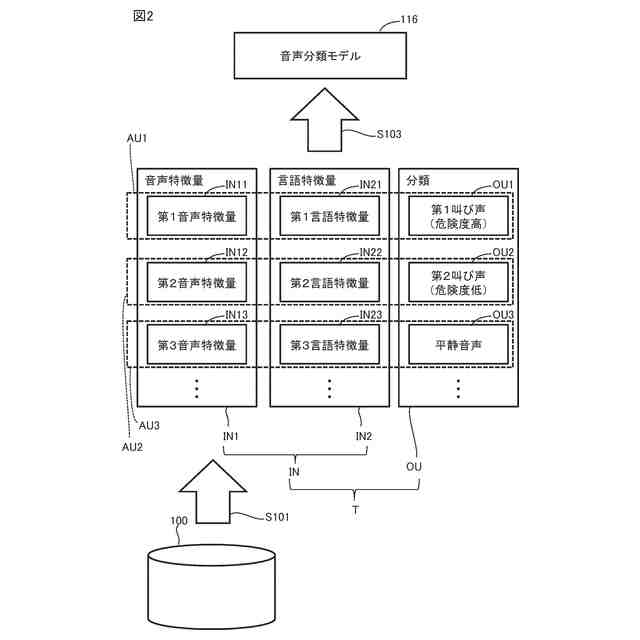
図2は、システムの有する、音声分類モデルの生成方法の一例を表した図である。
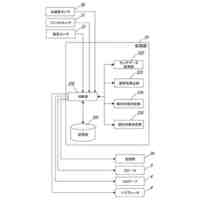
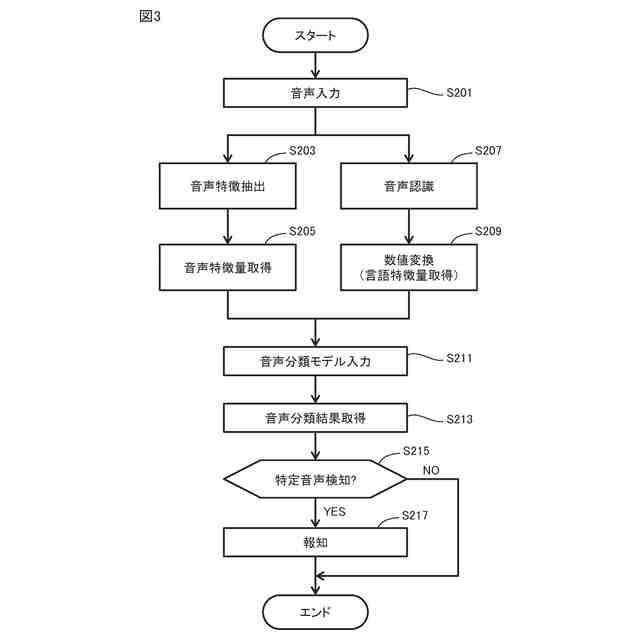
図3は、システムでの叫び声検知方法の流れの一例を表したフローチャートである。
図4は、音声分類モデルの生成に用いた、データベースの生成方法の流れの一例を表したフローチャートである。
図5は、図4のステップS303の一例を表した図である。
図6は、図4のステップS307の一例を表した図である。
図7は、図4のステップS309の一例を説明するための図である。
【発明を実施するための形態】
【0010】
<1.叫び声検知システム、音声分類方法、及び、音声分類モデルの生成方法の概要>
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
学校法人立命館
味覚向上装置
5か月前
学校法人立命館
ロボットハンド
6か月前
学校法人立命館
神経発達症群のモデル動物
6か月前
学校法人立命館
運動誘導装置、運動誘導方法
1か月前
学校法人立命館
乾癬の予防、治療又は改善剤
6か月前
学校法人立命館
流路構造、流路構造製造方法
10日前
トヨタ自動車株式会社
色処理方法
2か月前
学校法人立命館
周波数シンセサイザ及び無線通信装置
5か月前
学校法人立命館
コマンド入力装置、コマンド入力方法
3か月前
株式会社東洋レーベル
入眠促進装置
6日前
住友化学株式会社
植物の代謝物含量調節剤
5か月前
学校法人立命館
配管パイプ型微生物燃料電池及び配管システム
4か月前
学校法人立命館
筋組織カルシウム蓄積を抑制するビタミンD作用
1か月前
学校法人立命館
生体リズム推定システム及び生体リズム推定方法
5か月前
学校法人立命館
感情推定装置、感情推定方法、感情推定プログラム
3か月前
Patentix株式会社
霧化装置及び製膜装置。
1か月前
学校法人立命館
異種タンパク質の大量生産が可能なナス科植物の四重変異体
3日前
学校法人立命館
薄膜の膜厚を測定する測定方法、測定装置および測定プログラム
3か月前
学校法人立命館
設計システム、コンピュータ実装方法、及びコンピュータプログラム
2か月前
学校法人立命館
心理的距離推定装置、心理的距離推定方法、心理的距離推定プログラム
3か月前
学校法人立命館
アピイン生産のための新規遺伝子およびそれを用いたアピインの生産方法
4か月前
学校法人立命館
メッシュ生成システム、コンピュータ実装方法及びコンピュータプログラム
9日前
学校法人立命館
信号検証方法、受信機、コンピュータプログラム、及び位置指紋の生成方法
5か月前
Patentix株式会社
積層構造体、半導体装置、電子機器及びシステム
1か月前
Patentix株式会社
積層構造体、半導体装置、電子機器及びシステム
1か月前
日工株式会社
モルタルの製造方法およびフレッシュコンクリートの製造方法
4か月前
Patentix株式会社
積層構造体、半導体装置、電子機器及びシステム
1か月前
Patentix株式会社
積層構造体、半導体装置、電子機器及びシステム
1か月前
Patentix株式会社
積層構造体、半導体装置、電子機器及びシステム
1か月前
Patentix株式会社
積層構造体、半導体装置、電子機器及びシステム
1か月前
美津濃株式会社
解析方法、解析装置、解析システム、および解析プログラム
4か月前
Patentix株式会社
積層構造体、半導体装置、電子機器及びシステム
1か月前
学校法人立命館
モデルの作成支援システム、コンピュータ実装方法及びコンピュータプログラム
2か月前
Patentix株式会社
結晶、積層構造体、半導体装置、電子機器及びシステム
1か月前
Patentix株式会社
結晶、積層構造体、半導体装置、電子機器及びシステム
1か月前
Patentix株式会社
結晶膜、積層構造体、半導体装置、電子機器及びシステム
1か月前
続きを見る
他の特許を見る




 特許ウォッチ
特許ウォッチ