TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025043510
公報種別
公開特許公報(A)
公開日
2025-04-01
出願番号
2023150824
出願日
2023-09-19
発明の名称
無線アクセスネットワークの制御装置
出願人
KDDI株式会社
代理人
弁理士法人大塚国際特許事務所
主分類
H04W
24/02 20090101AFI20250325BHJP(電気通信技術)
要約
【課題】学習効率の低下を防ぐと共に、学習データを収集する装置と機械学習を行う装置との間で伝送される学習データのデータ量が増えすぎることを抑えることができる。
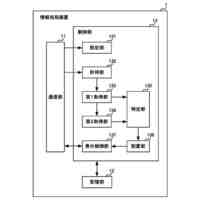
【解決手段】無線アクセスネットワーク(RAN)の制御装置は、学習モデルに基づき前記RANを制御し、前記RANから第1学習データを収集する収集手段と、前記学習モデルに対する機械学習における前記第1学習データの有用性を判定する判定手段と、前記第1学習データの前記有用性に基づき、前記機械学習を行う別の制御装置に送信する第2学習データを前記第1学習データから選択する処理を行う処理手段と、を備えている。
【選択図】図5
特許請求の範囲
【請求項1】
無線アクセスネットワーク(RAN)の制御装置であって、
学習モデルに基づき前記RANを制御し、前記RANから第1学習データを収集する収集手段と、
前記学習モデルに対する機械学習における前記第1学習データの有用性を判定する判定手段と、
前記第1学習データの前記有用性に基づき、前記機械学習を行う別の制御装置に送信する第2学習データを前記第1学習データから選択する処理を行う処理手段と、
を備えている、制御装置。
続きを表示(約 950 文字)
【請求項2】
前記処理手段には伝送速度の上限値が設定されており、
前記処理手段は、前記別の制御装置に送信する前記第2学習データの伝送速度が前記上限値以下となる様に、前記第1学習データの前記有用性の降順で前記第2学習データを前記第1学習データから選択する、請求項1に記載の制御装置。
【請求項3】
前記上限値は、前記別の制御装置によって設定される、請求項2に記載の制御装置。
【請求項4】
前記処理手段には伝送速度の上限値と、前記有用性に基づき選択確率の確率値を判定するための判定情報が設定されており、
前記処理手段は、前記第1学習データの前記有用性に基づき前記第1学習データの前記確率値を判定し、前記別の制御装置に送信する前記第2学習データの伝送速度が前記上限値以下となる様に、前記第1学習データの前記確率値に基づく選択確率で前記第2学習データを前記第1学習データから選択し、
前記判定情報に基づく前記確率値は、前記有用性が高い程、高くなる、請求項1に記載の制御装置。
【請求項5】
前記上限値及び前記判定情報の少なくとも一方は、前記別の制御装置によって設定される、請求項4に記載の制御装置。
【請求項6】
前記処理手段には前記有用性の閾値が設定されており、
前記処理手段は、前記有用性が前記閾値より高い前記第1学習データを前記第2学習データとして選択する、請求項1に記載の制御装置。
【請求項7】
前記閾値は、前記別の制御装置によって設定される、請求項6に記載の制御装置。
【請求項8】
前記第1学習データの前記有用性は、当該第1学習データに含まれる前記学習モデルへの入力データに基づく前記学習モデルの出力の誤差に基づき判定される、請求項1に記載の制御装置。
【請求項9】
前記第1学習データの前記有用性は、前記誤差が大きい程、高くなる、請求項8に記載の制御装置。
【請求項10】
前記第1学習データの前記有用性は、当該第1学習データの時間差分誤差が大きい程、高くなる、請求項1に記載の制御装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本開示は、無線アクセスネットワーク(RAN)の制御技術に関する。
続きを表示(約 2,800 文字)
【背景技術】
【0002】
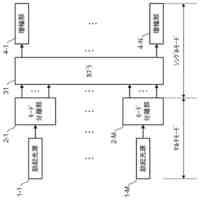
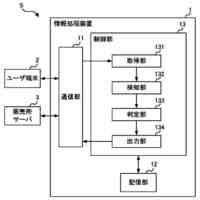
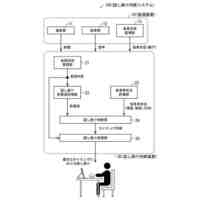
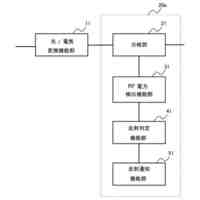
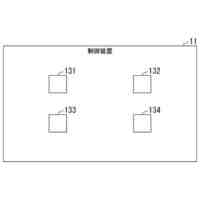
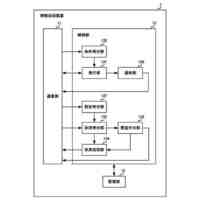
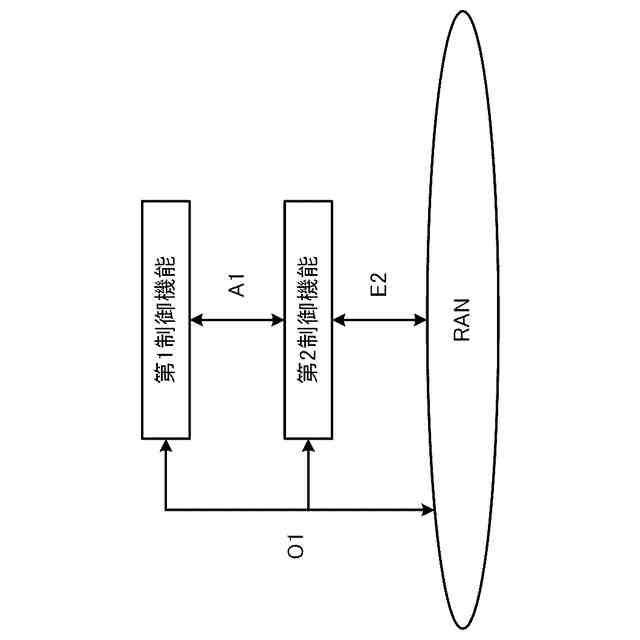
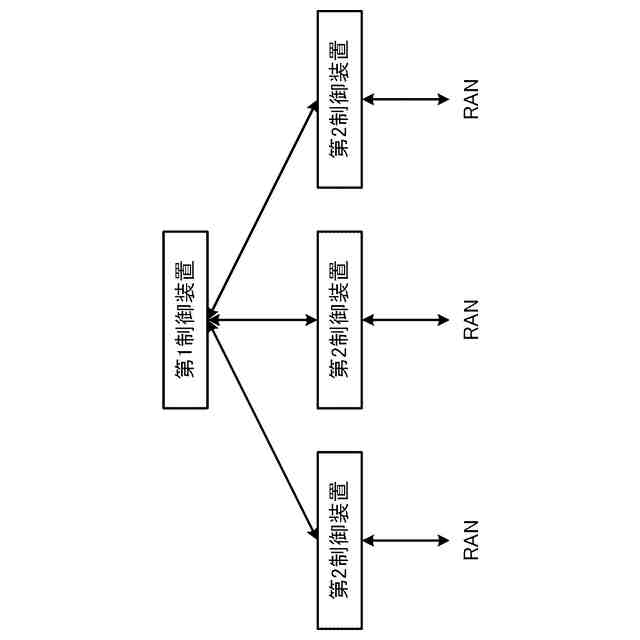
図1は、オープン無線アクセスネットワーク(O-RAN)アライアンスが提案するRANの制御構成を示している。図1に示す様に、長周期的な制御を行う第1制御機能と、短周期的な制御を行う第2制御機能と、が定義されている。O-RANにおいて、第1制御機能は、非リアルタイムRANインテリジェントコントローラ(Non-RT RIC)と呼ばれ、第2制御機能は、ニアリアルタイムRANインテリジェントコントローラ(Near-RT RIC)と呼ばれる。
【0003】
第1制御機能と第2制御機能は、A1インタフェースを介して接続される。第2制御機能は、E2インタフェースを介してRANの構成要素である中央ユニット(CU)や分散ユニット(DU)等を制御する。なお、CUやDUを制御するとは、CUやDUがその処理において使用する各種のパラメータ値をCUやDUに通知・設定することや、CUやDUに対して何らかの動作の実行を指示すること等を含む。さらに、以下の説明において"RAN"との用語を、その構成要素の総称として使用する。したがって、例えば、"RANを制御する"とは、RANの構成要素であるCUやDU等を制御することを意味する。第1制御機能、第2制御機能及びRANは、さらに、O1インタフェースで接続される。O1インタフェースは、RANが計測/検知して蓄積するトラフィックデータ、パフォーマンスデータ、障害データ等の送信に使用され得る。
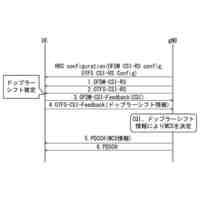
【0004】
非特許文献1は、RANの制御に対して機械学習を利用する構成を開示している。具体的には、非特許文献1は、RAN等から収集した様々な学習データに基づき機械学習を行って学習モデルを生成し、当該学習モデルを使用して推論を行い、推論結果に従ってRANを制御することを開示している。非特許文献1が開示する複数の構成の内の1つにおいては、第1制御機能が学習モデルを生成する。そして、第2制御機能は、第1制御機能が生成した学習モデルを使用してRANを制御する。
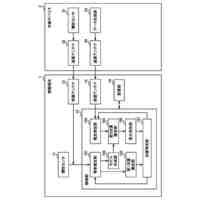
【0005】
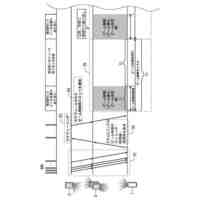
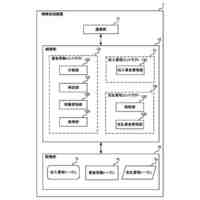
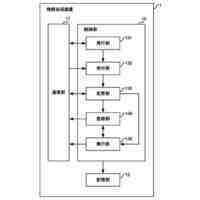
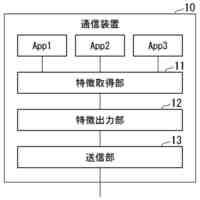
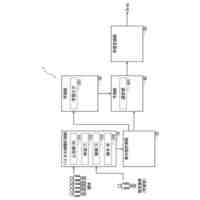
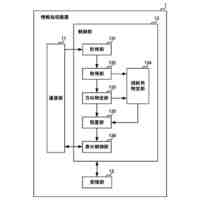
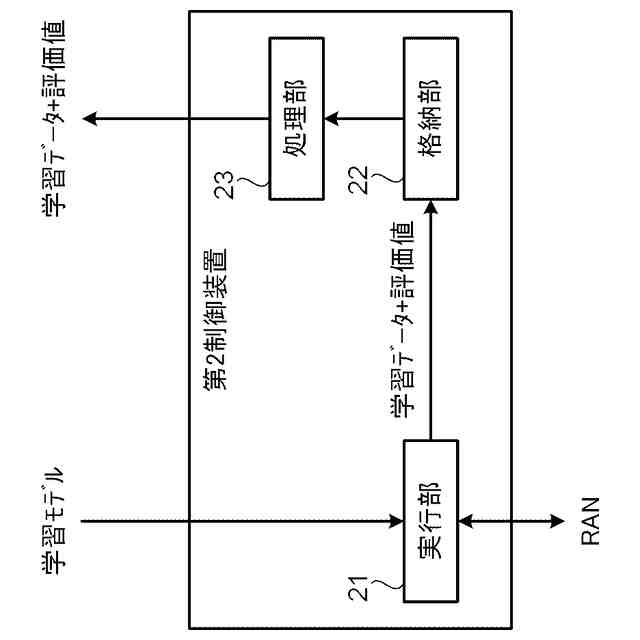
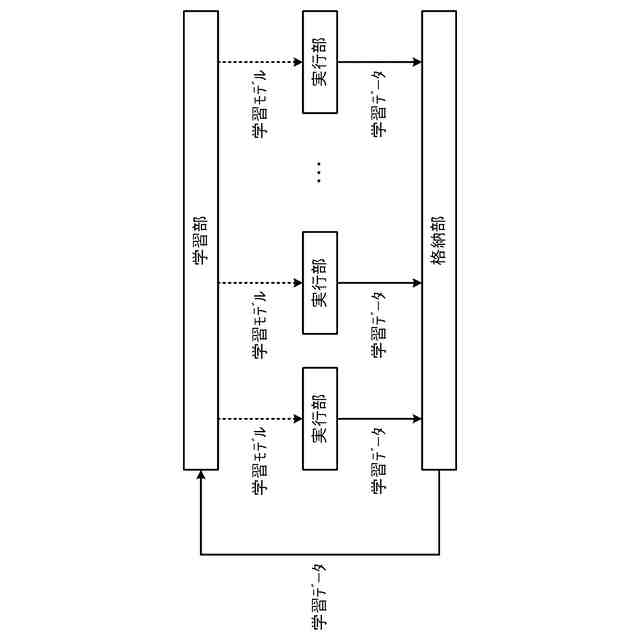
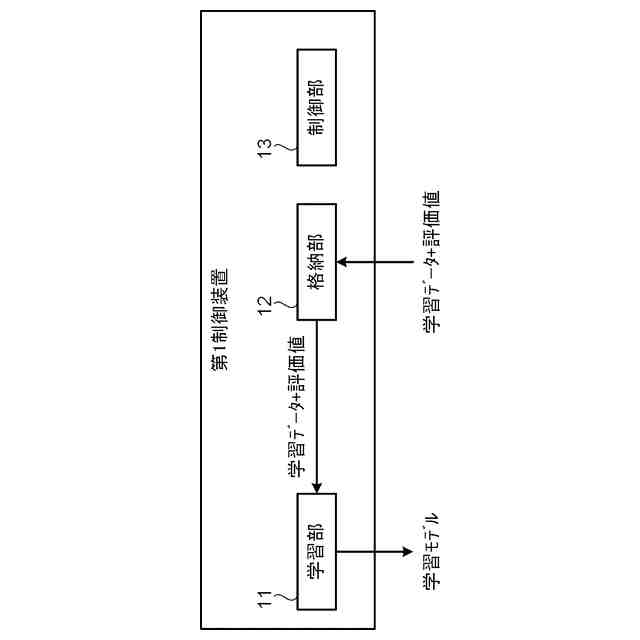
非特許文献2は、高い学習効率を得ることができる分散強化学習を開示している。図2に示す様に、分散強化学習において、学習部は、格納部に格納されている学習データに基づき機械学習を行って学習モデルを生成する。学習部は、分散して配置された複数の実行部に学習モデルを配布する。各実行部は、それぞれ"制御対象"に関連付けられる。実行部は、制御対象の"現在の状態"に基づき学習モデルを使用して制御対象に対する制御内容を決定し、決定した"制御内容"に基づき当該制御対象の制御を実行する。実行部は、この制御の結果としての制御対象の"次の状態"を判定して、制御目標の"達成度"を評価する。なお、分散強化学習において、上記説明の"制御対象"、"現在の状態"、"次の状態"、"制御内容"及び"達成度"は、それぞれ、"Enviroment"(環境)、"State"、"Next State"、"Actiоn"(行動)及び"Reward"(報酬)と呼ばれる。
【0006】
そして、実行部は、達成度と、現在の状態と、次の状態と、に基づき、時間差分誤差(Tempоral difference errоr)と呼ばれる評価値を求める。なお、以下の説明において、時間差分誤差をTD誤差と表記し、その値をTD誤差値と表記する。TD誤差値は、制御の結果として得られた"達成度"と"次の状態"に基づき判定される価値との和から、制御前の"現在の状態"に基づき判定される価値を減じたものとして定義される。TD誤差値が大きいことは、"次の状態"での制御目標の達成度が低いこと、つまり、"現在の状態"に基づく学習モデルの出力の精度が低いこと、或いは、"現在の状態"に基づく学習モデルの出力誤差が大きいことを意味する。
【0007】
実行部は、"現在の状態"、"次の状態"、"制御内容"及び"達成度"を学習データとして、学習部による次の学習のために格納部に格納する。この際、実行部は、当該学習データついて求めたTD誤差値を当該学習データに付与する。上記の通り、学習データのTD誤差値が大きいことは、当該学習データに含まれる学習モデルへの入力データ(現在の状態)による学習モデルの出力の精度が低いことを意味する。したがって、TD誤差値の大きい学習データを機械学習に使用することで学習モデルが大きく更新されて学習効果が高くなる。このため、学習部は、格納部に格納されている学習データの内、より大きいTD誤差値が付与されている学習データを優先して機械学習に使用する。これにより、学習部による学習効率を高くすることができる。
【先行技術文献】
【非特許文献】
【0008】
O-RAN Alliance,"AI/ML workflow description and requirements",O-RAN.WG2.AIML-v01.03,2021年7月
D.Horgan,et.al.,"Distributed prioritized experience replay",arXiv:1803.00933.,2018年4月
【発明の概要】
【発明が解決しようとする課題】
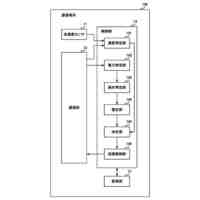
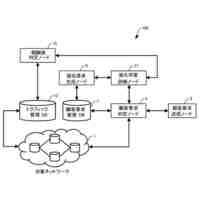
【0009】
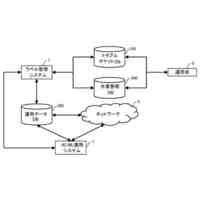
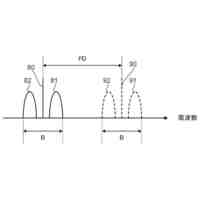
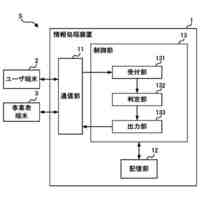
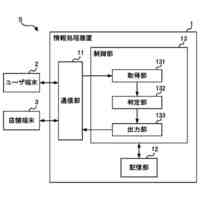
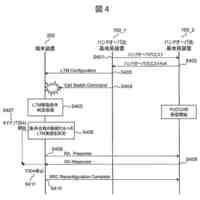
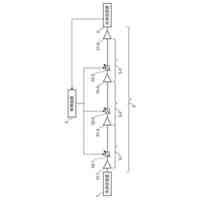
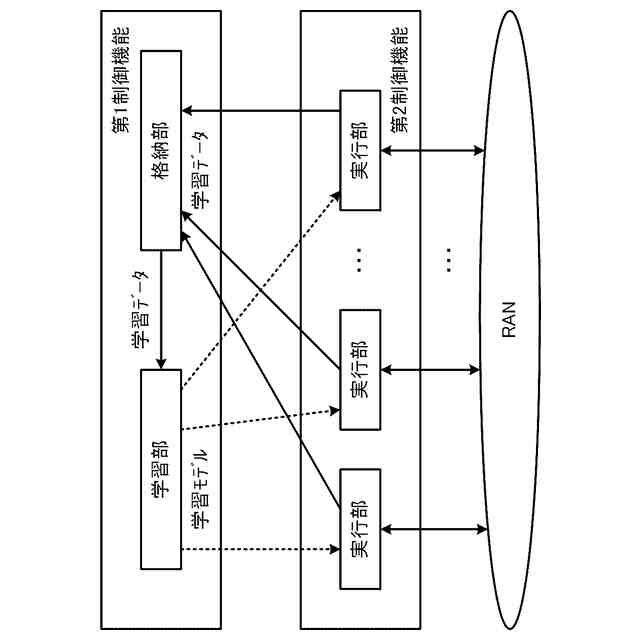
図3は、分散強化学習をO-RANに適用した場合の構成を示している。学習モデルに基づきRANを制御する実行部は、第2制御機能に配置され、学習モデルを生成する学習部と、実行部が収集する学習データを格納する格納部は、第1制御機能に配置される。しかしながら、図3の構成では、第2制御機能の各実行部からの学習データのデータ量が膨大となり過ぎる。例えば、第1制御機能がカバーする領域に250万台のユーザ装置(UE)があり、RANから取得される学習データのサイズが1つのUE当たり356バイトであり、第1制御機能がカバーする領域にある第2制御機能の各実行部が1秒間に20回の周期で学習データを第1制御機能に送信するものとする。この場合、第1制御機能は、毎秒142.4ギガビットのデータを受信することになり、現実的ではない。例えば、第2制御機能の各実行部が学習データを送信する周期を長くすることで、第1制御機能が受信する学習データのデータ量を減らすことができるが、学習効率を低下させ得る。
【0010】
本開示は、学習効率の低下を防ぐと共に、学習データを収集する装置と機械学習を行う装置との間で伝送される学習データのデータ量が増えすぎることを抑える技術を提供するものである。
【課題を解決するための手段】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
KDDI株式会社
光増幅器
3日前
KDDI株式会社
伸展マスト
2日前
KDDI株式会社
基地局及び通信端末
2日前
KDDI株式会社
ラベル管理システム
7日前
KDDI株式会社
光送信装置及び光受信装置
8日前
KDDI株式会社
情報処理方法及びプログラム
7日前
KDDI株式会社
参照信号の設定方法及び装置
今日
KDDI株式会社
参照信号の設定方法及び装置
今日
KDDI株式会社
情報処理装置及び情報処理方法
今日
KDDI株式会社
情報処理装置及び情報処理方法
1日前
KDDI株式会社
情報処理装置及び情報処理方法
1日前
KDDI株式会社
情報処理装置及び情報処理方法
1日前
KDDI株式会社
無線システム及び通信制御方法
1日前
KDDI株式会社
情報処理装置及び情報処理方法
6日前
KDDI株式会社
話し掛け判断装置及びプログラム
1日前
KDDI株式会社
通信装置、通信方法及びプログラム
1日前
KDDI株式会社
端末装置、および無線通信システム
今日
KDDI株式会社
端末装置、および無線通信システム
今日
KDDI株式会社
反射光検出装置および反射光検出方法
3日前
KDDI株式会社
リンクアダプテーション方法及び装置
今日
KDDI株式会社
リンクアダプテーション方法及び装置
今日
KDDI株式会社
無線通信システムおよびその制御方法
1日前
KDDI株式会社
無線通信システムおよびその制御方法
1日前
KDDI株式会社
通信システム、情報端末及びプログラム
3日前
KDDI株式会社
通信端末、距離測定方法及びプログラム
2日前
KDDI株式会社
基地局装置、端末装置及び無線通信方法
2日前
KDDI株式会社
通信システム、情報端末及びプログラム
3日前
KDDI株式会社
基地局装置、端末装置及び無線通信方法
2日前
KDDI株式会社
制御装置、通信システムおよび制御方法
1日前
KDDI株式会社
学習支援システム、方法及びプログラム
今日
KDDI株式会社
光通信システムの制御装置及びプログラム
7日前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
6日前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
今日
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
6日前
KDDI株式会社
顧客要求制御システムおよび強化学習モデル
6日前
KDDI株式会社
情報処理装置、情報処理方法及びプログラム
今日
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ