TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025035715
公報種別
公開特許公報(A)
公開日
2025-03-14
出願番号
2023142940
出願日
2023-09-04
発明の名称
音声認識装置およびプログラム
出願人
日本放送協会
代理人
個人
,
個人
,
個人
,
個人
主分類
G10L
15/06 20130101AFI20250307BHJP(楽器;音響)
要約
【課題】テキストのみに基づいて(つまり、音声に依らずに)トランスデューサー音声認識モデルの中間層の情報を生成することのできる音声認識装置を提供する。
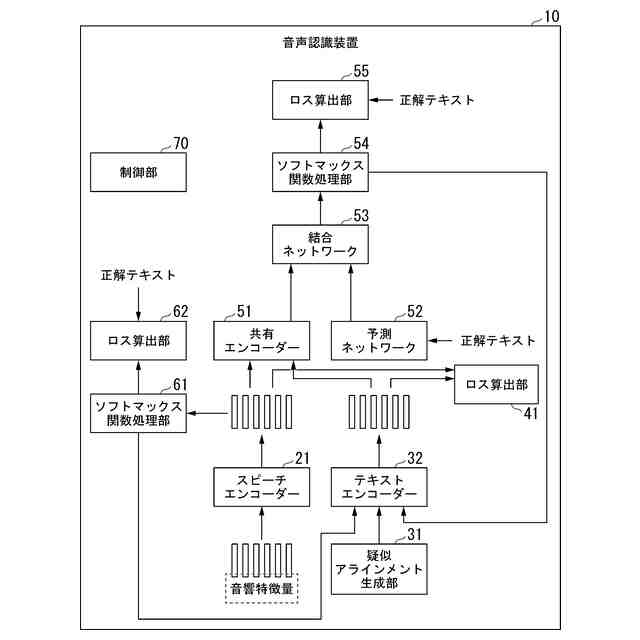
【解決手段】第1エンコーダーは、音響特徴量に基づいて中間層特徴量を算出する。第2エンコーダーは、前記中間層特徴量に基づいて最終層特徴量を算出して。第1ロス算出部は、最終層特徴量と正解テキストとに基づいて、第1ロスを算出する。第2ロス算出部は、中間層特徴量と正解テキストとに基づいて、第2ロスを算出する。第1ロスおよび第2ロスに基づいて、第1および第2エンコーダーの学習を行えるようにする。テキストエンコーダーは、テキストに基づいてテキスト特徴量を算出する。第3ロス算出部は、中間層特徴量とテキスト特徴量とに基づいて、第3ロスを算出する。第3ロスに基づいて、前記テキストエンコーダーの学習を行えるようにする。
【選択図】図1
特許請求の範囲
【請求項1】
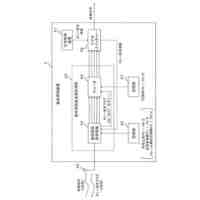
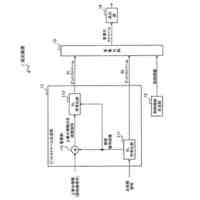
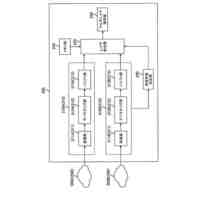
入力される音響特徴量に基づいて中間層特徴量を算出して出力する第1エンコーダーと、
前記第1エンコーダーから出力される前記中間層特徴量に基づいて最終層特徴量を算出して出力する第2エンコーダーと、
前記第2エンコーダーから出力される前記最終層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第1ロスを算出する第1ロス算出部(55)と、
前記第1エンコーダーから出力される前記中間層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第2ロスを算出する第2ロス算出部(62)と、
入力されるテキストに基づいて、テキスト特徴量を算出して出力するテキストエンコーダーと、
前記第1エンコーダーが出力した前記中間層特徴量と、前記テキストエンコーダーが出力した前記テキスト特徴量とに基づいて、第3ロスを算出する第3ロス算出部(41)と
を備え、
前記第1ロスに基づいて、前記第2エンコーダーが持つネットワークのパラメーターと、前記第1エンコーダーが持つネットワークのパラメーターと、を調整可能として、
前記第2ロスに基づいて、前記第1エンコーダーが持つネットワークのパラメーターを調整可能として、
前記第3ロスに基づいて、前記テキストエンコーダーが持つネットワークのパラメーターを調整可能とした、
音声認識装置。
続きを表示(約 1,300 文字)
【請求項2】
入力されるテキスト文字列に基づいて、前記テキスト文字列に含まれる記号がn
c
回(n
c
≧1)連続するように繰り返す操作を行うとともに、前記テキスト文字列に含まれる記号間にn
b
回(n
b
≧0)連続するブランク記号を挿入する操作を行うことによって疑似的記号列を生成する疑似アラインメント生成部、
をさらに備え、
前記テキスト文字列に基づいて、学習済みの前記第2エンコーダーの再学習を行う際には、
前記テキストエンコーダーは、前記テキスト文字列に基づいて前記疑似アラインメント生成部が生成した前記疑似的記号列を前記テキストとして、当該テキストに基づいてテキスト特徴量を算出して出力し、
前記第2エンコーダーは、前記第1エンコーダーから出力される前記中間層特徴量に代えて、前記テキストエンコーダーから出力される前記テキスト特徴量に基づいて、前記最終層特徴量を算出して出力する、
請求項1に記載の音声認識装置。
【請求項3】
前記疑似アラインメント生成部は、記号の連続回数n
c
について所定の統計から決定される確率密度関数P
c
(n)に基づいて前記n
c
の値を決定するとともに、ブランク記号の連続回数n
b
について所定の統計から決定される確率密度関数P
b
(n)に基づいて前記n
b
の値を決定する、
請求項2に記載の音声認識装置。
【請求項4】
入力される音響特徴量に基づいて中間層特徴量を算出して出力する第1エンコーダーと、
前記第1エンコーダーから出力される前記中間層特徴量に基づいて最終層特徴量を算出して出力する第2エンコーダーと、
前記第2エンコーダーから出力される前記最終層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第1ロスを算出する第1ロス算出部(55)と、
前記第1エンコーダーから出力される前記中間層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第2ロスを算出する第2ロス算出部(62)と、
入力されるテキストに基づいて、テキスト特徴量を算出して出力するテキストエンコーダーと、
前記第1エンコーダーが出力した前記中間層特徴量と、前記テキストエンコーダーが出力した前記テキスト特徴量とに基づいて、第3ロスを算出する第3ロス算出部(41)と
を備え、
前記第1ロスに基づいて、前記第2エンコーダーが持つネットワークのパラメーターと、前記第1エンコーダーが持つネットワークのパラメーターと、を調整可能として、
前記第2ロスに基づいて、前記第1エンコーダーが持つネットワークのパラメーターを調整可能として、
前記第3ロスに基づいて、前記テキストエンコーダーが持つネットワークのパラメーターを調整可能とした、
音声認識装置、としてコンピューターを機能させるためのプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識装置およびプログラムに関する。
続きを表示(約 2,900 文字)
【背景技術】
【0002】
ストリーミング音声認識に適した音声認識モデルとして、Transducer(トランスデューサー)と呼ばれるモデルが存在する。非特許文献1では、Transducerの技術が記載されている。
【先行技術文献】
【非特許文献】
【0003】
Kanishka Rao,Hasim Sak,Rohit Prabhavalkar,“Exploring architectures, data and units for streaming end-to-end speech recognition with RNN-transducer”,in Proc. IEEE ASRU, 2017,pp. 193-199.
【発明の概要】
【発明が解決しようとする課題】
【0004】
音声認識モデルの認識精度は、モデルの学習を行う際の学習データにも依存する。あるドメインに属する学習データを用いて音声認識モデルの学習を行った場合には、他のドメインの音声を認識しようとしたときの精度には限界があると考えられる。そこで、他のドメイン(ターゲットドメインと呼ぶ)の情報を用いて音声認識モデルの再学習(ドメイン適応)を行うことができれば、そのターゲットドメインにおける音声認識精度を向上させることができると期待される。
【0005】
ターゲットドメインの情報を用いて音声認識モデルの再学習は、ターゲットドメインに属するテキストに基づいて行うことが考えられる。そのための一形態として、ターゲットドメインに属するテキストに基づいて音声認識モデルの中間層の情報(特徴量、中間層のエンコーダーから出力されるベクトル等)を生成できるようにすることが考えられる。
【0006】
本発明は、上記の課題認識に基づいて為されたものであり、テキストのみを用いた学習を行えるようにするために、テキストのみに基づいて(つまり、音声に依らずに)トランスデューサー音声認識モデルの中間層の情報(エンコーダーからの中間層出力)を生成することのできる音声認識装置、およびそのプログラムを提供しようとするものである。
【課題を解決するための手段】
【0007】
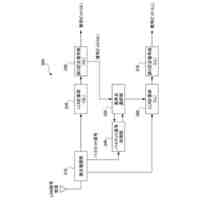
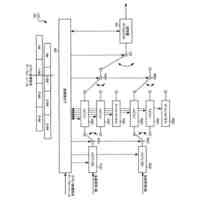
[1]上記の課題を解決するため、本発明の一態様による音声認識装置は、入力される音響特徴量に基づいて中間層特徴量を算出して出力する第1エンコーダーと、前記第1エンコーダーから出力される前記中間層特徴量に基づいて最終層特徴量を算出して出力する第2エンコーダーと、前記第2エンコーダーから出力される前記最終層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第1ロスを算出する第1ロス算出部(55)と、前記第1エンコーダーから出力される前記中間層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第2ロスを算出する第2ロス算出部(62)と、入力されるテキストに基づいて、テキスト特徴量を算出して出力するテキストエンコーダーと、前記第1エンコーダーが出力した前記中間層特徴量と、前記テキストエンコーダーが出力した前記テキスト特徴量とに基づいて、第3ロスを算出する第3ロス算出部(41)とを備え、前記第1ロスに基づいて、前記第2エンコーダーが持つネットワークのパラメーターと、前記第1エンコーダーが持つネットワークのパラメーターと、を調整可能として、前記第2ロスに基づいて、前記第1エンコーダーが持つネットワークのパラメーターを調整可能として、前記第3ロスに基づいて、前記テキストエンコーダーが持つネットワークのパラメーターを調整可能とした、音声認識装置である。
【0008】
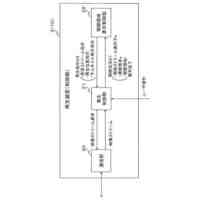
[2]また、本発明の一態様は、上記[1]の音声認識装置において、入力されるテキスト文字列に基づいて、前記テキスト文字列に含まれる記号がn
c
回(n
c
≧1)連続するように繰り返す操作を行うとともに、前記テキスト文字列に含まれる記号間にn
b
回(n
b
≧0)連続するブランク記号を挿入する操作を行うことによって疑似的記号列を生成する疑似アラインメント生成部、をさらに備え、前記テキスト文字列に基づいて、学習済みの前記第2エンコーダーの再学習を行う際には、前記テキストエンコーダーは、前記テキスト文字列に基づいて前記疑似アラインメント生成部が生成した前記疑似的記号列を前記テキストとして、当該テキストに基づいてテキスト特徴量を算出して出力し、前記第2エンコーダーは、前記第1エンコーダーから出力される前記中間層特徴量に代えて、前記テキストエンコーダーから出力される前記テキスト特徴量に基づいて、前記最終層特徴量を算出して出力する、というものである。
【0009】
[3]また、本発明の一態様は、上記[2]の音声認識装置において、前記疑似アラインメント生成部は、記号の連続回数n
c
について所定の統計から決定される確率密度関数P
c
(n)に基づいて前記n
c
の値を決定するとともに、ブランク記号の連続回数n
b
について所定の統計から決定される確率密度関数P
b
(n)に基づいて前記n
b
の値を決定する、ものである。
【0010】
[4]また、本発明の一態様は、入力される音響特徴量に基づいて中間層特徴量を算出して出力する第1エンコーダーと、前記第1エンコーダーから出力される前記中間層特徴量に基づいて最終層特徴量を算出して出力する第2エンコーダーと、前記第2エンコーダーから出力される前記最終層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第1ロスを算出する第1ロス算出部(55)と、前記第1エンコーダーから出力される前記中間層特徴量と、入力された前記音響特徴量に対応する正解テキストとに基づいて、第2ロスを算出する第2ロス算出部(62)と、入力されるテキストに基づいて、テキスト特徴量を算出して出力するテキストエンコーダーと、前記第1エンコーダーが出力した前記中間層特徴量と、前記テキストエンコーダーが出力した前記テキスト特徴量とに基づいて、第3ロスを算出する第3ロス算出部(41)とを備え、前記第1ロスに基づいて、前記第2エンコーダーが持つネットワークのパラメーターと、前記第1エンコーダーが持つネットワークのパラメーターと、を調整可能として、前記第2ロスに基づいて、前記第1エンコーダーが持つネットワークのパラメーターを調整可能として、前記第3ロスに基づいて、前記テキストエンコーダーが持つネットワークのパラメーターを調整可能とした、音声認識装置、としてコンピューターを機能させるためのプログラムである。
【発明の効果】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
日本放送協会
配線構造
2か月前
日本放送協会
撮像装置
6か月前
日本放送協会
光学計測装置
4か月前
日本放送協会
無線通信装置
4か月前
日本放送協会
マイクロホン
4か月前
日本放送協会
液晶表示装置
11か月前
日本放送協会
磁性細線メモリ
3か月前
日本放送協会
光制御デバイス
11か月前
日本放送協会
レンズアダプター
8か月前
日本放送協会
映像伝送システム
2か月前
日本放送協会
磁性細線デバイス
6か月前
日本放送協会
無線伝送システム
6か月前
日本放送協会
3次元映像表示装置
3か月前
日本放送協会
データ管理システム
6か月前
日本放送協会
良撮影位置推定装置
1か月前
日本放送協会
垂直分離型撮像素子
10か月前
日本放送協会
角度選択フィルター
1か月前
日本放送協会
受信装置及び送出装置
7か月前
日本放送協会
送信装置及び受信装置
9か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
同軸切替器の着脱機構
10か月前
日本放送協会
送出装置及び受信装置
12か月前
日本放送協会
送信装置及び受信装置
8か月前
日本放送協会
送信装置及び受信装置
12か月前
日本放送協会
撮像素子及び撮像装置
11か月前
日本放送協会
衛星放送受信システム
8か月前
日本放送協会
送信装置及び受信装置
6か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
11か月前
日本放送協会
端末装置及びプログラム
7か月前
日本放送協会
縮小装置及びプログラム
9日前
日本放送協会
受信装置及びプログラム
8か月前
日本放送協会
磁壁移動型空間光変調器
7か月前
日本放送協会
受信装置及びプログラム
1か月前
日本放送協会
再生装置及びプログラム
10か月前
日本放送協会
伸縮性を有する半導体装置
8か月前
続きを見る
他の特許を見る
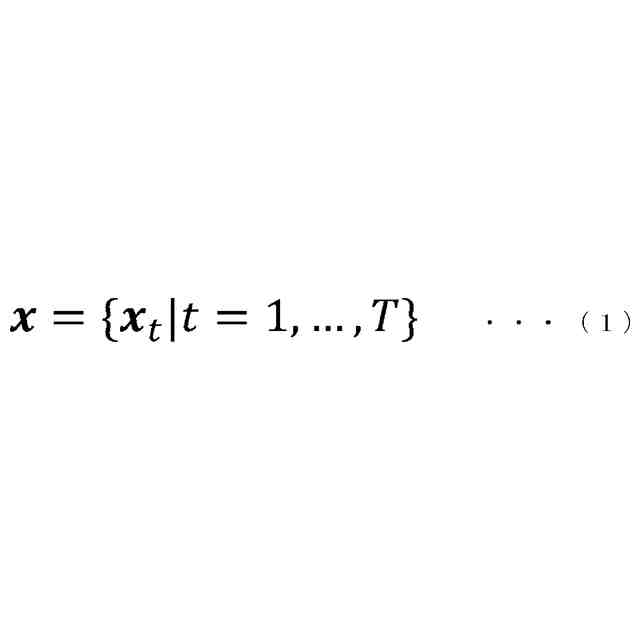
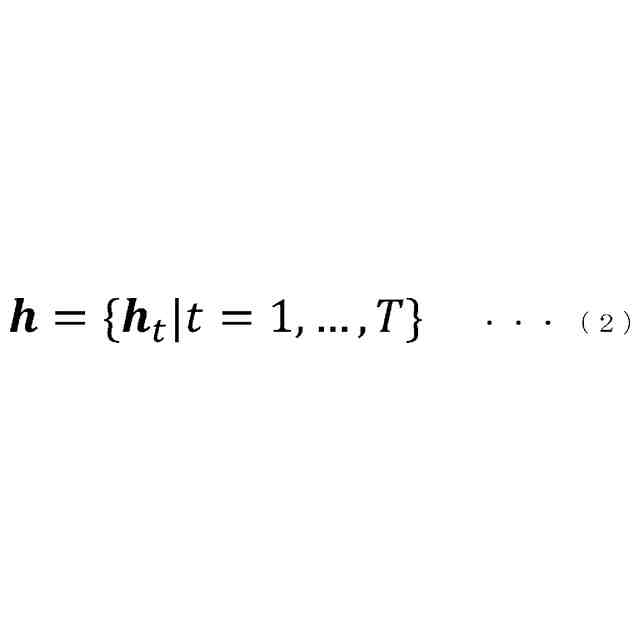


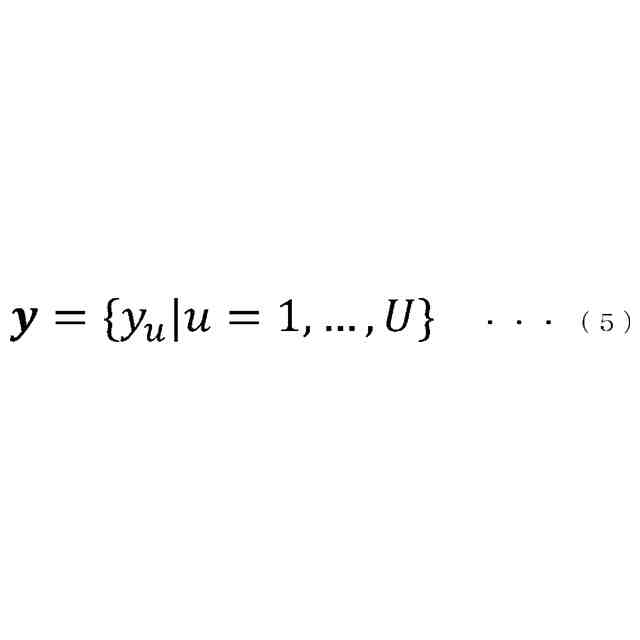

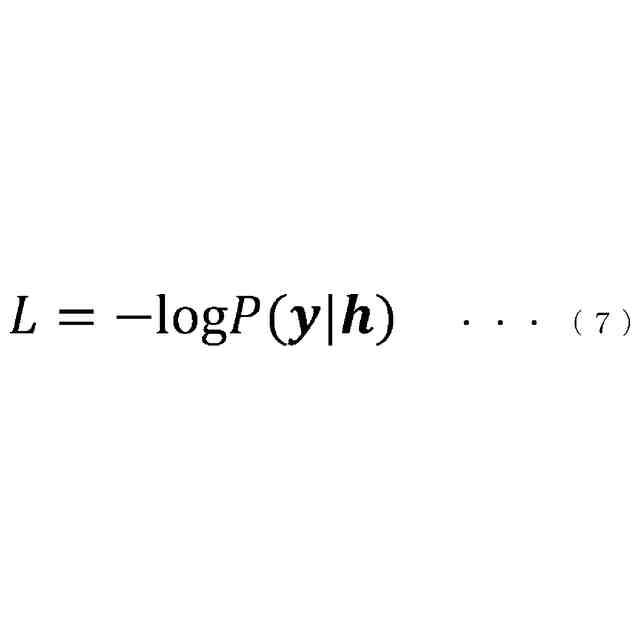

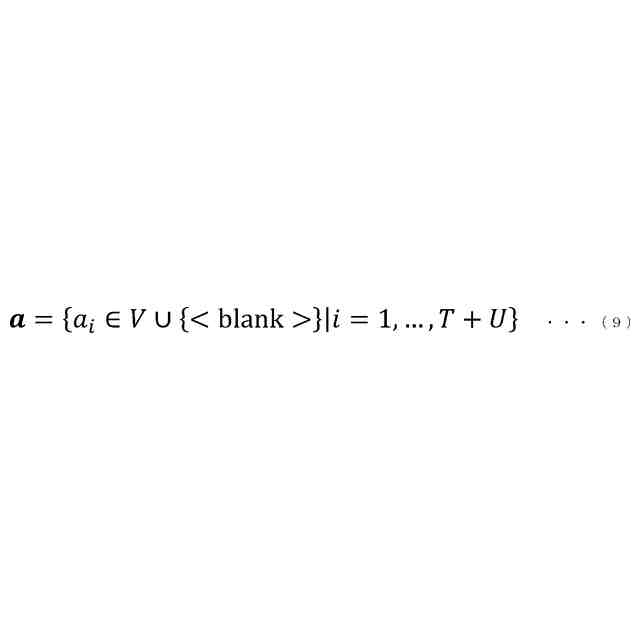
 特許ウォッチ
特許ウォッチ