TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024161380
公報種別
公開特許公報(A)
公開日
2024-11-19
出願番号
2024114800,2021183302
出願日
2024-07-18,2019-08-23
発明の名称
コンピューティングデバイス
出願人
サウンドハウンド,インコーポレイテッド
代理人
弁理士法人深見特許事務所
主分類
G10L
15/25 20130101AFI20241112BHJP(楽器;音響)
要約
【課題】オーディオデータおよび画像データに基づいて人の発声を解析する装置および方法が記載される。
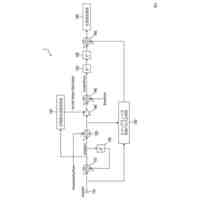
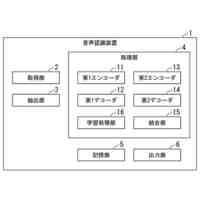
【解決手段】ある例は、音声処理を向上させるために視覚情報を使用する。この視覚情報は車両内部から得られる画像データであり得る。ある例において、装置は、オーディオデータおよび画像データに基づいて人の発声を解析するように構成される音声処理モジュールを含む。音声処理モジュールは、オーディオデータを処理し、発声を解析するために使用される音素データを予測するように構成される音響モデルを含む。音響モデルは、入力として話者特徴ベクトルおよびオーディオデータを受け取るように構成され、音素データを予測するために話者特徴ベクトルおよびオーディオデータを使用するように学習される。
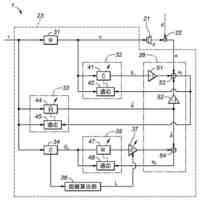
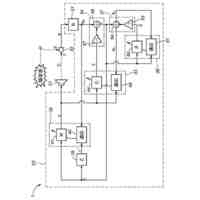
【選択図】図1B
特許請求の範囲
【請求項1】
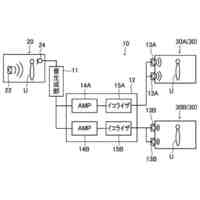
車両のオーディオキャプチャデバイスからオーディオデータを受け取るように構成されるオーディオインターフェイスと、
前記車両からの画像をキャプチャするよう画像キャプチャデバイスから画像データを受け取るように構成される画像インターフェイスと、
前記オーディオデータおよび前記画像データに基づいて人の発声を解析するように構成される音声処理モジュールと、
前記画像データを受け取り、かつ、音素データを予測するために前記画像データに基づいて話者特徴ベクトルを得るように構成される話者前処理モジュールとを含む、車載装置。
続きを表示(約 1,000 文字)
【請求項2】
前記音声処理モジュールは、前記オーディオデータを処理し、前記発声を解析するために使用される前記音素データを予測するように構成される音響モデルを含む、請求項1に記載の車載装置。
【請求項3】
前記音響モデルはニューラルネットワークアーキテクチャを含む、請求項2に記載の車載装置。
【請求項4】
前記音響モデルは、入力として前記話者特徴ベクトルおよび前記オーディオデータを受け取るように構成され、前記音素データを予測するために前記話者特徴ベクトルおよび前記オーディオデータを使用するように学習される、請求項2または3に記載の車載装置。
【請求項5】
前記画像データは、前記車両内の人の顔エリアを含む、請求項1~4に記載の車載装置。
【請求項6】
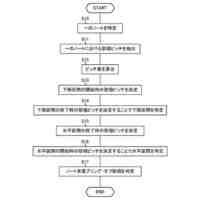
前記話者前処理モジュールは、
前記車両内の前記人を識別するために前記画像データに対して顔認識を行なうことと、
識別された前記人に関連付けられる話者特徴ベクトルを抽出することとを行うように構成される、請求項1~5に記載の車載装置。
【請求項7】
前記話者前処理モジュールは、
プロセッサによって実現される読唇モジュールを含み、前記読唇モジュールは、前記人の前記顔エリア内の唇の動きに基づいて1つ以上の話者特徴ベクトルを生成するように構成される、請求項1または6に記載の車載装置。
【請求項8】
前記話者前処理モジュールはニューラルネットワークアーキテクチャを含み、前記ニューラルネットワークアーキテクチャは、前記オーディオデータおよび前記画像データのうちの1つ以上に由来するデータを受け取り、前記話者特徴ベクトルを予測するように構成される、請求項1~7のいずれか1項に記載の車載装置。
【請求項9】
前記話者前処理モジュールは、
予め規定された数の発声について話者特徴ベクトルを計算することと、
前記予め規定された数の発声について複数の前記話者特徴ベクトルに基づいて静的な話者特徴ベクトルを計算することとを行うように構成される、請求項1~8のいずれか1項に記載の車載装置。
【請求項10】
前記静的な話者特徴ベクトルは前記車両のメモリ内に格納される、請求項9に記載の車載装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
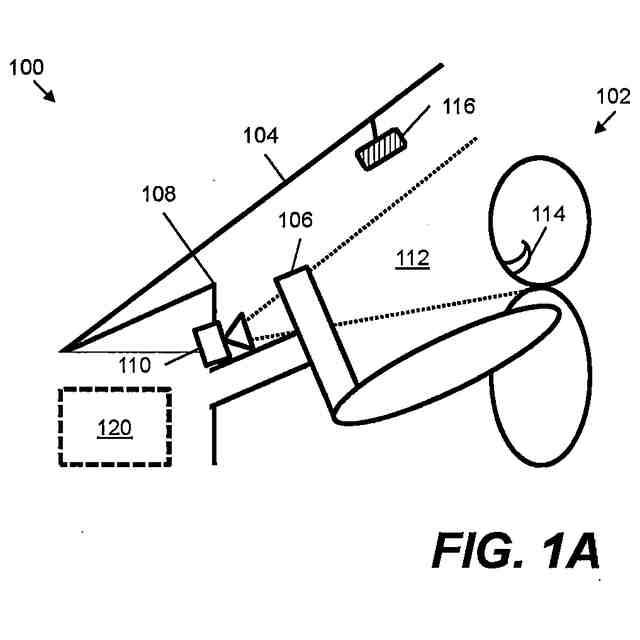
本発明の技術分野
本技術は音声処理の分野にある。ある例は、車両内部からキャプチャされる音声を処理することに関する。
続きを表示(約 2,800 文字)
【背景技術】
【0002】
背景
コンピューティングにおける最近の進歩によって、多くの長く望まれていた音声制御アプリケーションを実現する可能性が高まっている。たとえば、有効なニューラルネットワークアーキテクチャについての実際的なフレームワークを含む統計モデルにおける改善によって、以前の音声処理システムの精度および信頼性が大幅に増加している。これがワイドエリアコンピュータネットワークの興隆と組み合わされ、単にアプリケーションプログラミングインターフェイスを使用してアクセスされ得るある範囲のモジュラーサービスを提供する。音声は急速に、ユーザインターフェイスを提供するための実行可能オプションになっている。
【0003】
音声制御デバイスは、家庭内で一般的になっているが、車両内で音声処理を提供することにはさらなる困難が示される。たとえば、車両は、しばしば(音声インターフェイスのような)補助的な機能のための処理リソースが限られており、顕著なノイズ(たとえばハイレベルの道路ノイズおよび/またはエンジンノイズ)に見舞われ、音響環境での制約を提示する。如何なるユーザインターフェイスも、車両を制御する安全性への影響によって更に制約される。これらの要因によって、車両内で音声制御を実際上達成することが困難になっている。
【0004】
さらに音声処理における進歩にもかかわらず、高度なコンピューティングデバイスのユーザでさえしばしば、現在のシステムは人間レベルの応答性および知能を欠いていると報告している。空気中の圧力変動を解析されたコマンドへ変換することは、信じられないほど困難である。音声処理は典型的に複雑な処理パイプラインを伴い、如何なるステージでのエラーによっても機械の解釈の成功が損なわれることになる。これらの困難のうちの多くは、意識的な思考なしで皮質構造または皮質下構造を使用して音声を処理することができる人間にとっては直ちに明白ではない。しかしながら、当該分野で働くエンジニアは急速に、人間の能力と現状技術の音声処理との間のギャップに気付いている。
【0005】
US8,442,820B2(特許文献1)は、読唇および音声認識組合マルチモーダルインターフェイスシステムを記載している。当該システムは、音声および唇の動きによるのみナビゲーションオペレーション命令を発行し得、これにより、運転手がナビゲーションオペレーションの間に前方を見ることが可能になり、運転中のナビゲーションオペレーションに関係する車両事故を低減する。US8,442,820B2に記載される読唇および音声認識組合マルチモーダルインターフェイスシステムは、オーディオ音声入力ユニットと、音声認識ユニットと、音声認識命令および推定確率出力ユニットと、唇ビデオ画像入力ユニットと、読唇ユニットと、読唇認識命令出力ユニットと、音声認識命令を出力する音声認識および読唇認識結果組合ユニットとを含む。US8,442,820B2は車両内制御の1つのソリューションを提供しているが、提案されたシステムは複雑であり、多くの相互動作するコンポーネントによって、エラーおよび解析の失敗の機会が増加する。
【0006】
より正確に人間の発声を文字起こし(transcribe)して解析する音声処理システムおよ
び方法を提供することが望まれている。さらに、車両のための埋込型コンピューティングシステムのような現実世界のデバイスにより実際に実現され得る音声処理方法を提供することが望まれている。実際的な音声処理ソリューションを実現することは、システムインテグレーションおよび接続性について多くの困難が車両に存在するため、困難である。
【先行技術文献】
【特許文献】
【0007】
米国特許明細書第8,422,820号
【発明の概要】
【課題を解決するための手段】
【0008】
発明の概要
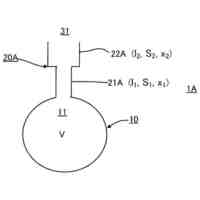
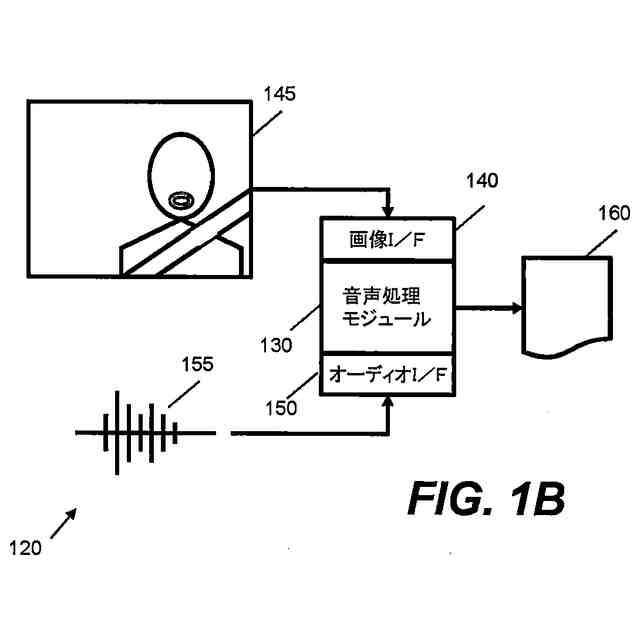
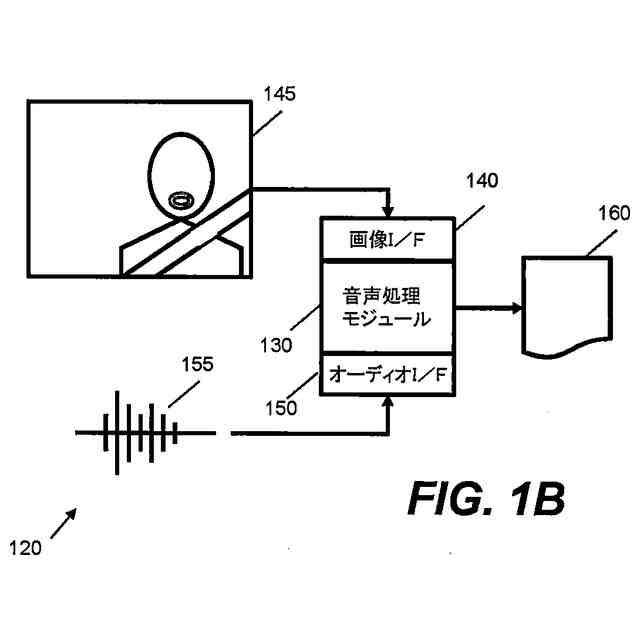
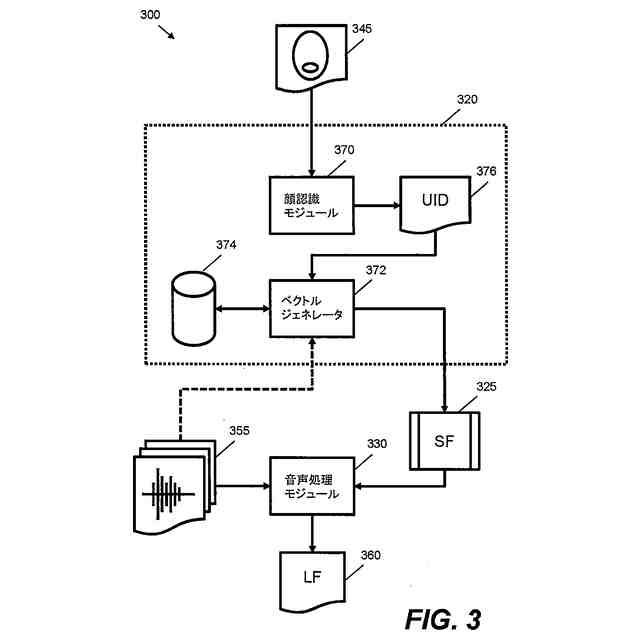
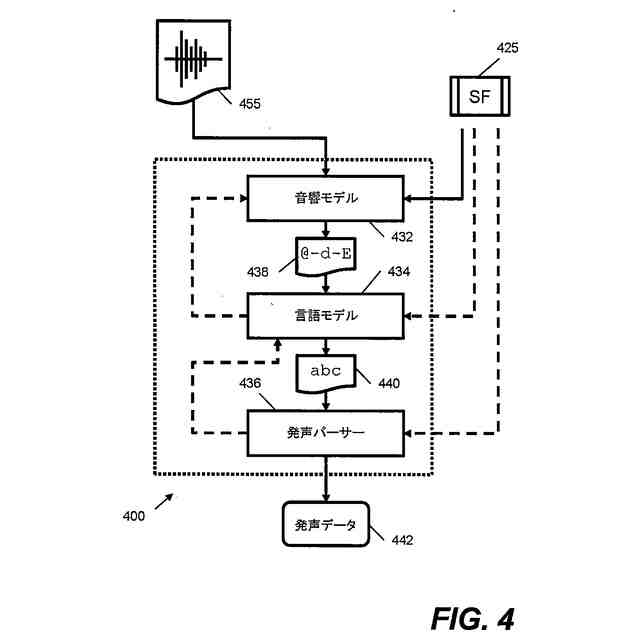
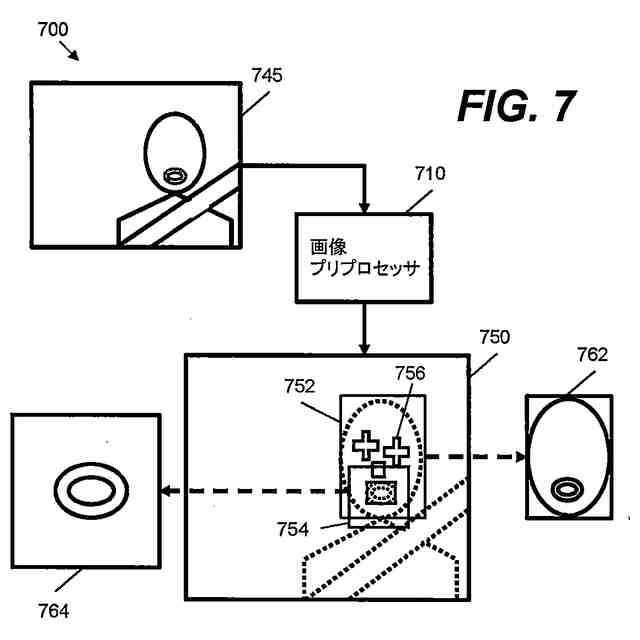
本願明細書において記載されるある例は、スピーチを処理するための方法およびシステムを提供する。ある例は、スピーチを処理するためにオーディオデータおよび画像データの両方を使用する。ある例は、車両内でキャプチャされる発声を処理する困難に対応するために適合される。ある例は、たとえば車両内の人といった少なくとも人の顔エリアを特徴とする画像データに基づいて、話者特徴ベクトルを得る。その後、音声処理は、発声の話者に依存する視覚由来情報を使用して行なわれる。これにより、精度および堅牢性が改善され得る。
【0009】
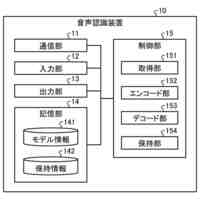
1つの局面では、車両のための装置は、車両内に位置するオーディオキャプチャデバイスからオーディオデータを受け取るように構成されるオーディオインターフェイスと、車両内で画像データをキャプチャするために、車両内の人の顔エリアを特徴とする画像データを画像キャプチャデバイスから受け取るように構成される画像インターフェイスと、オーディオデータおよび画像データに基づいて人の発声を解析するように構成される音声処理モジュールとを含む。音声処理モジュールは、オーディオデータを処理し、発声を解析するために使用される音素データを予測するように構成される音響モデルを含み、音響モデルはニューラルネットワークアーキテクチャを含む。装置はさらに、プロセッサによって実現される話者前処理モジュールを含み、話者前処理モジュールは、画像データを受け取り、かつ、画像データに基づいて話者特徴ベクトルを得るように構成されており、音響モデルは、入力として話者特徴ベクトルおよびオーディオデータを受け取るように構成され、音素データを予測するために話者特徴ベクトルおよびオーディオデータを使用するように学習される。
【0010】
上記の局面では、話者特徴ベクトルは、話している人の顔エリアを特徴とする画像データを使用して得られる。この話者特徴ベクトルは、音響モデルのニューラルネットワークアーキテクチャへの入力として提供され、音響モデルは、発声を特徴とするオーディオデータと同様にこの入力を使用するように構成される。これにより、発声の解析を改善するために、たとえば車両内の望ましくない音響およびノイズ特徴を補償するために、ニューラルネットワークアーキテクチャが使用し得る付加的な視覚由来情報が音響モデルに提供される。たとえば、画像データから決定される特定の人および/またはその人の口エリアに基づいて音響モデルを構成することによって、たとえば、付加的な情報がなければ、車両の状況に基づいて誤って文字起こしされ得る曖昧な音素の決定が向上され得る。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
横浜ゴム株式会社
水中音響材
今日
ヤマハ株式会社
ヘルムホルツ共鳴器
24日前
大和ハウス工業株式会社
音再現設備
4日前
日産自動車株式会社
防音構造体
18日前
セイコーエプソン株式会社
吸音ボード
18日前
株式会社第一興商
カラオケ装置
24日前
株式会社第一興商
カラオケ装置
4日前
京セラ株式会社
音出力装置及び音出力方法
18日前
コスモネクスト株式会社
入力支援プログラム及び入力支援方法
11日前
本田技研工業株式会社
能動型騒音低減装置
18日前
日本放送協会
音声認識装置およびプログラム
18日前
本田技研工業株式会社
能動型騒音低減装置
24日前
株式会社アナザーウェア
鍵盤画面表示プログラム及びそのシステム
24日前
トヨタ自動車株式会社
異音診断システム
24日前
株式会社コルグ
音波生成装置、音波生成方法、プログラム
11日前
株式会社永セ仁
「パワハラ」等ハラスメント発言に係る職場環境測定システム
今日
ソフトバンクグループ株式会社
行動制御システム
11日前
本田技研工業株式会社
音声認識装置、音声認識方法、およびプログラム
3日前
永楽電気株式会社
放送音声文字化システム及び放送設備における故障診断方法
18日前
パイオニア株式会社
情報処理装置
5日前
東日本電信電話株式会社
演奏補助装置、演奏補助方法、及び、演奏補助プログラム
3日前
ヤマハ株式会社
響板、その製造方法および響板を備える楽器
3日前
ドーナッツロボティクス株式会社
音声処理システム、音声処理方法
11日前
三菱重工業株式会社
サイレンサ
24日前
ソフトバンクグループ株式会社
データ処理装置、データ処理方法、及びプログラム
18日前
株式会社アナザーウェア
鍵盤画面表示プログラム及びそのシステム
24日前
カシオ計算機株式会社
情報処理装置、情報処理方法及びプログラム
5日前
カシオ計算機株式会社
楽音制御システム
3日前
ローランド株式会社
電子打楽器、制御装置、ベロシティ算出プログラム及びベロシティ算出方法
3日前
日産自動車株式会社
シート状防音構造体、並びにこれを用いた自動車用部品およびダクト閉塞用蓋部品
12日前
VIE株式会社
情報処理方法、記録媒体及び情報処理装置
今日
日本電信電話株式会社
音声認識装置、音声認識方法及び音声認識プログラム
12日前
カシオ計算機株式会社
モジュール及びウェアラブル機器
13日前
株式会社東芝
推定プログラム、学習プログラム、推定装置、学習装置、推定方法、学習方法、および学習モデル
11日前
株式会社VARK
音声配信システム、音声配信方法及びプログラム
13日前
日産自動車株式会社
シート状防音構造体およびその製造方法、並びにこれを用いた自動車用部品およびダクト閉塞用蓋部品
12日前
続きを見る
他の特許を見る





 特許ウォッチ
特許ウォッチ