TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025017240
公報種別
公開特許公報(A)
公開日
2025-02-05
出願番号
2023120254
出願日
2023-07-24
発明の名称
音声認識装置、音声認識方法及び音声認識プログラム
出願人
日本電信電話株式会社
,
国立大学法人東京科学大学
代理人
弁理士法人酒井国際特許事務所
主分類
G10L
15/16 20060101AFI20250129BHJP(楽器;音響)
要約
【課題】ASRのストリーミング処理を効率良く実行できる。
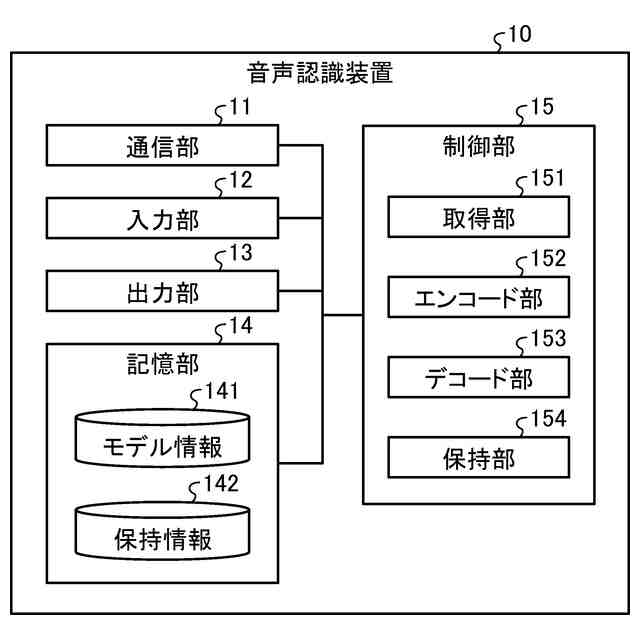
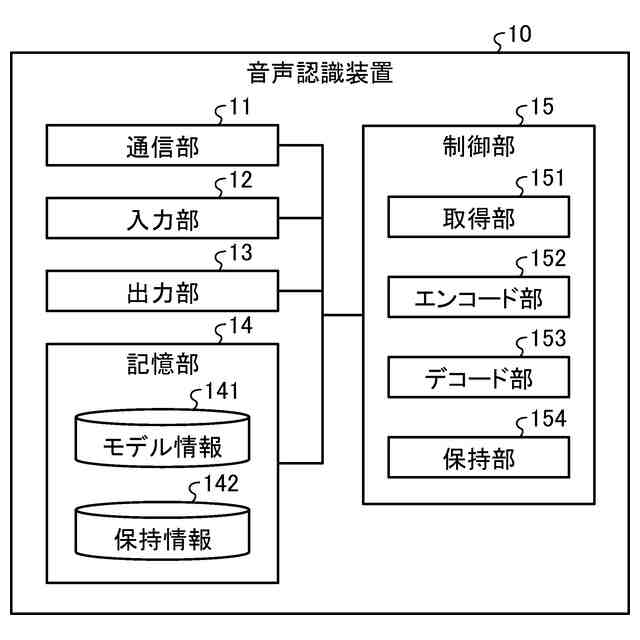
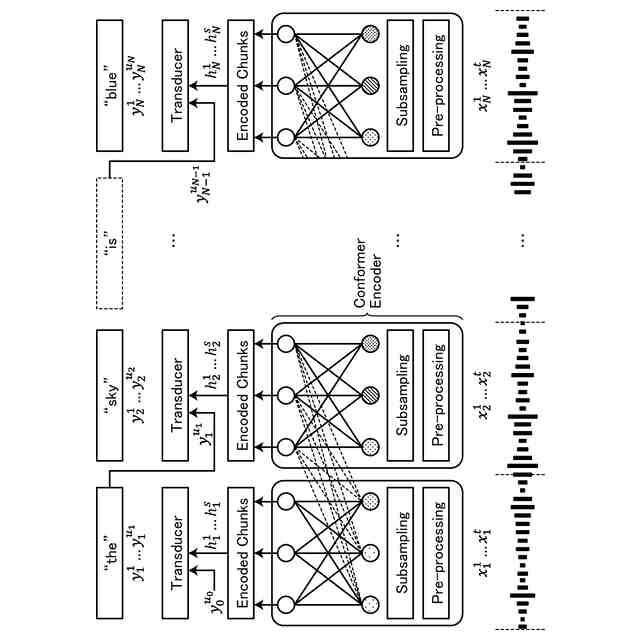
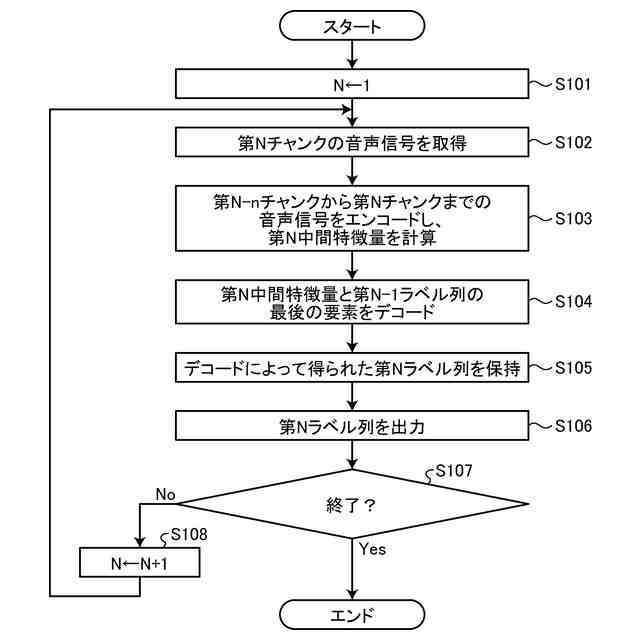
【解決手段】音声認識装置10は、取得部151、エンコード部152、及びデコード部153を有する。取得部151は、音声信号をチャンクごとに取得する。エンコード部152は、取得部151によって取得された第1のチャンクの音声信号と、第1のチャンクより過去に取得された一定数のチャンクの音声信号と、を基に、中間特徴量を計算する。デコード部153は、エンコード部152によって計算された中間特徴量を基に、テキストを特定するためのトークンの列を計算する。
【選択図】図1
特許請求の範囲
【請求項1】
音声信号をチャンクごとに取得する取得部と、
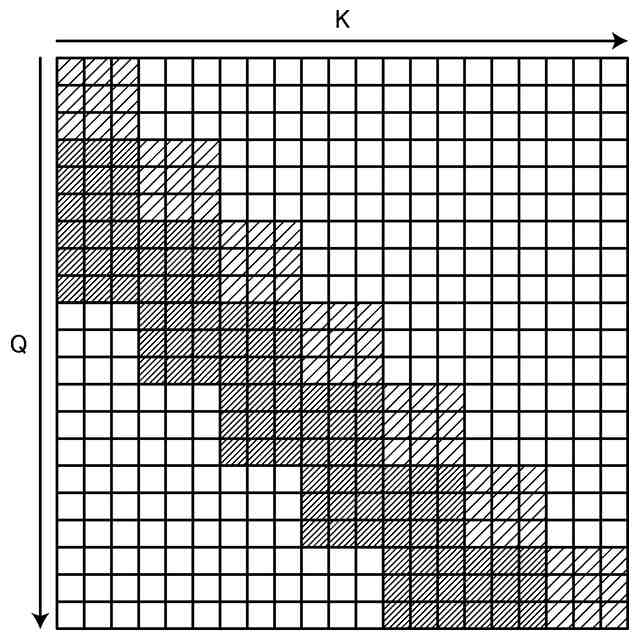
前記取得部によって取得された第1のチャンクの音声信号と、前記第1のチャンクより過去に取得された一定数のチャンクの音声信号と、を基に、中間特徴量を計算するエンコード部と、
前記エンコード部によって計算された前記中間特徴量を基に、テキストを特定するためのトークンの列を計算するデコード部と、
を有することを特徴とする音声認識装置。
続きを表示(約 630 文字)
【請求項2】
前記エンコード部は、Conformerモデルを用いてエンコードを行うことを特徴とする請求項1に記載の音声認識装置。
【請求項3】
前記デコード部は、Transducerを用いてデコードを行うことを特徴とする請求項1に記載の音声認識装置。
【請求項4】
音声認識装置によって実行される音声認識方法であって、
音声信号をチャンクごとに取得する取得工程と、
前記取得工程によって取得された第1のチャンクの音声信号と、前記第1のチャンクより過去に取得された一定数のチャンクの音声信号と、を基に、中間特徴量を計算するエンコード工程と、
前記エンコード工程によって計算された前記中間特徴量を基に、テキストを特定するためのトークンの列を計算するデコード工程と、
を含むことを特徴とする音声認識方法。
【請求項5】
音声信号をチャンクごとに取得する取得ステップと、
前記取得ステップによって取得された第1のチャンクの音声信号と、前記第1のチャンクより過去に取得された一定数のチャンクの音声信号と、を基に、中間特徴量を計算するエンコードステップと、
前記エンコードステップによって計算された前記中間特徴量を基に、テキストを特定するためのトークンの列を計算するデコードステップと、
をコンピュータに実行させることを特徴とする音声認識プログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識装置、音声認識方法及び音声認識プログラムに関する。
続きを表示(約 1,700 文字)
【背景技術】
【0002】
従来、音声をテキストに変換する技術であるASR(Automatic Speech Recognition)を利用した音声AIが知られている。音声AIには、リアルタイムでの音声からの文字起こし、動画の字幕作成、リアルタイムでの音声の翻訳、音声操作による音声アシスタント、運転中におけるボイスコマンドによる機器の操作、といった目的において、ストリーミング処理が求められる。
【0003】
ストリーミング処理によりASRを行うためのモデルとして、RNN-Transducerモデルが知られている。一方、RNN-Transducerモデルには、長いシーケンス(音声信号の系列)に対してうまく機能しないこと、RNN状態に再帰的な性質があり、また、並列での操作ができないことから、訓練が難しいこと、訓練中に勾配の消失及び爆発が発生すること、といった問題がある。
【0004】
これに対し、非ストリーミングのASRタスクとして優れているConvolution Augmented Transformer(Conformer)モデルを利用した因果的手法(例えば、非特許文献1を参照)、及びチャンクベースのアプローチ(例えば、非特許文献2を参照)が提案されている。
【先行技術文献】
【非特許文献】
【0005】
T.N.Sainath,他, "Improving the latency and quality of cascaded encoders,",in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)、 2022, pp.8112-8116
【0006】
S.Zhang, Z.Gao, H.Luo, M.Lei, J.Gao, Z.Yan, and L.Xie, "Streaming chunk-aware multihad attention for online end-to-end speech recognition,",Interspeech, 2020, pp.2142-2146
【発明の概要】
【発明が解決しようとする課題】
【0007】
しかしながら、従来の技術には、ASRのストリーミング処理を効率良く実行できない場合があるという問題がある。
【0008】
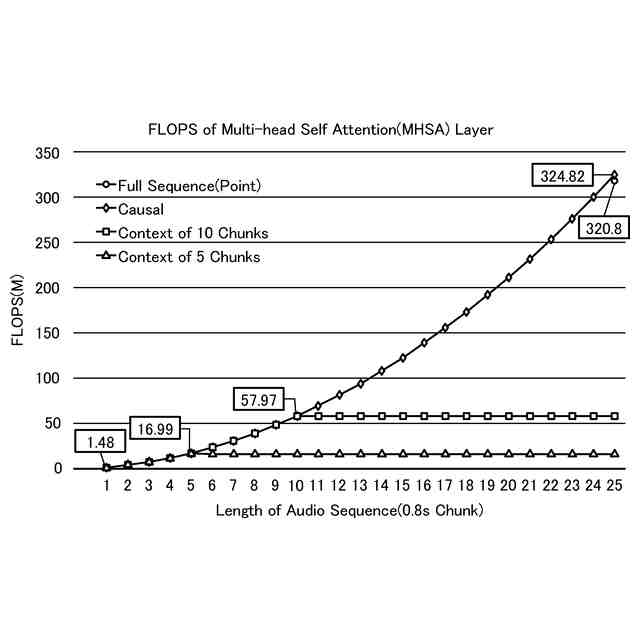
例えば、非特許文献1に記載の因果的手法は、シーケンス内の現在の要素のアテンションスコアを過去のフレームのみで計算し、将来のフレームをマスクするものである。一方、因果的手法には、音声の長さが長くなるにつれて、計算コストが2次的に増加するという問題がある。これは、新しいフレームと過去のフレームが繰り返し処理されるためである。
【0009】
また、例えば、非特許文献2に記載のチャンクベースのアプローチは、新しい音声のフレームが到着すると、オーディオのチャンクの形でオーディオフレームを処理するものである。一方、非特許文献2に記載のアプローチは、コンテキストを考慮していないため、パフォーマンス(例えば、認識精度)が低下することがある。
【課題を解決するための手段】
【0010】
上述した課題を解決し、目的を達成するために、音声認識装置は、音声信号をチャンクごとに取得する取得部と、前記取得部によって取得された第1のチャンクの音声信号と、前記第1のチャンクより過去に取得された一定数のチャンクの音声信号と、を基に、中間特徴量を計算するエンコード部と、前記エンコード部によって計算された前記中間特徴量を基に、テキストを特定するためのトークンの列を計算するデコード部と、を有することを特徴とする。
【発明の効果】
(【0011】以降は省略されています)
特許ウォッチbot のツイートを見る
この特許をJ-PlatPatで参照する
関連特許
他の特許を見る
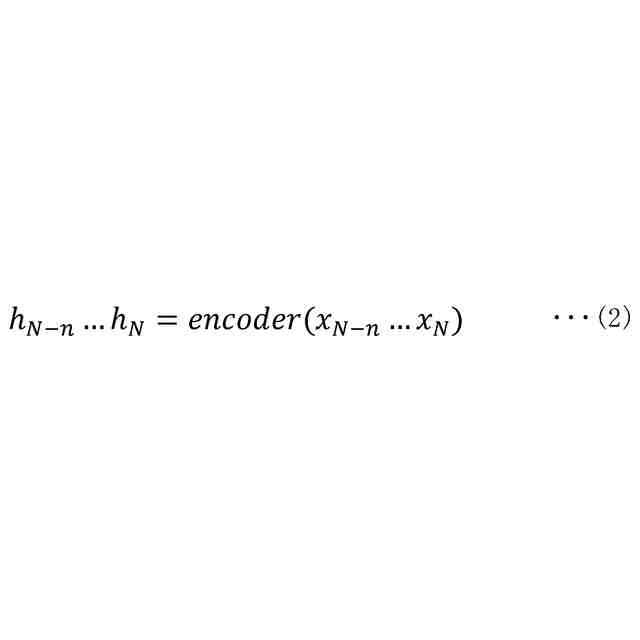
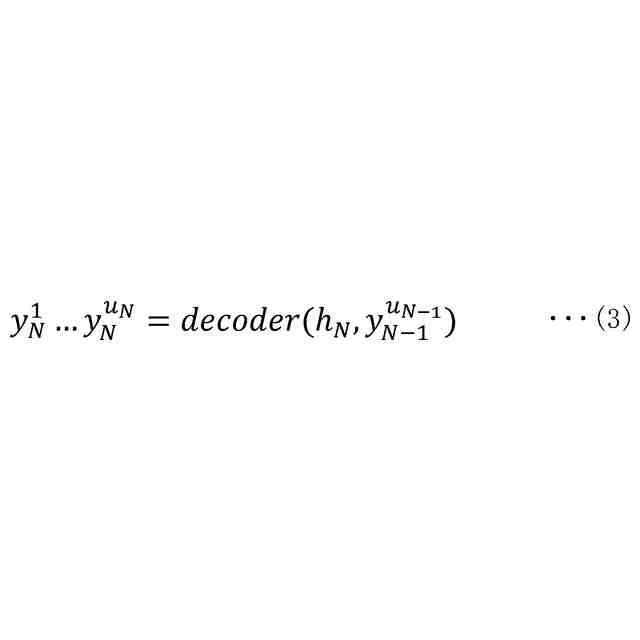

 特許ウォッチ
特許ウォッチ