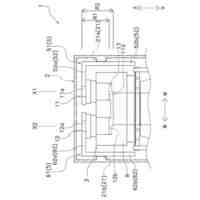
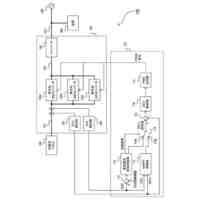
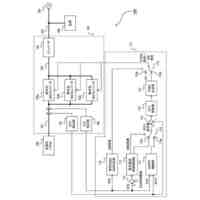
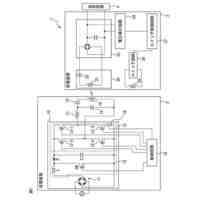
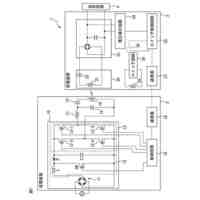
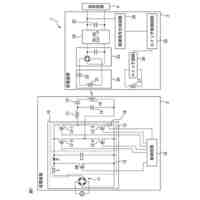
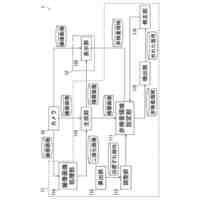
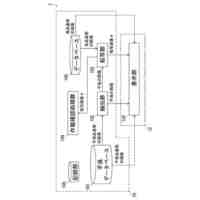
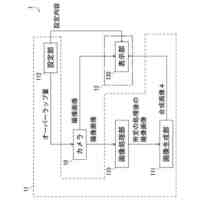
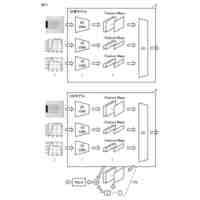
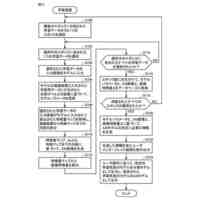
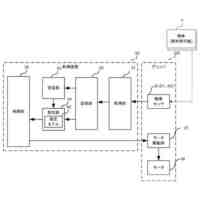
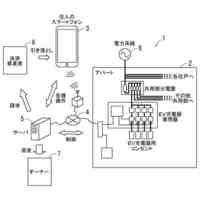
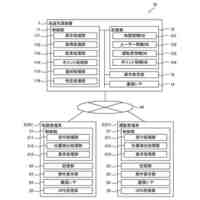
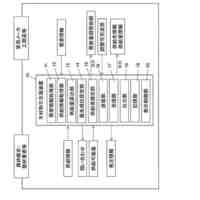
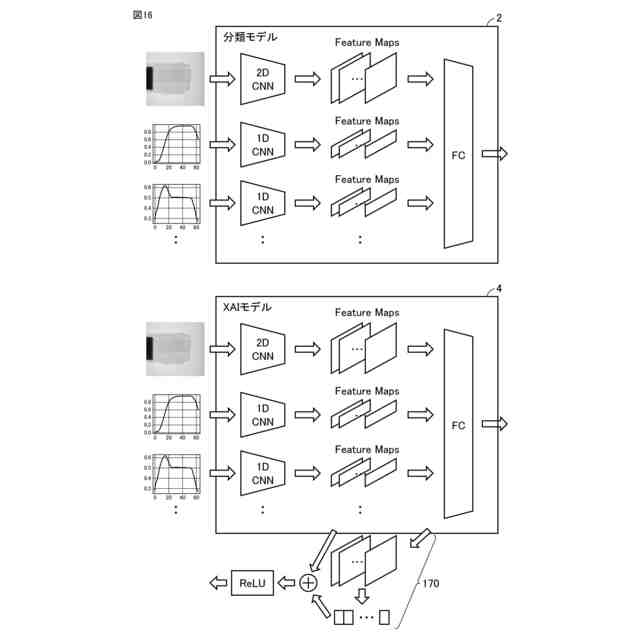
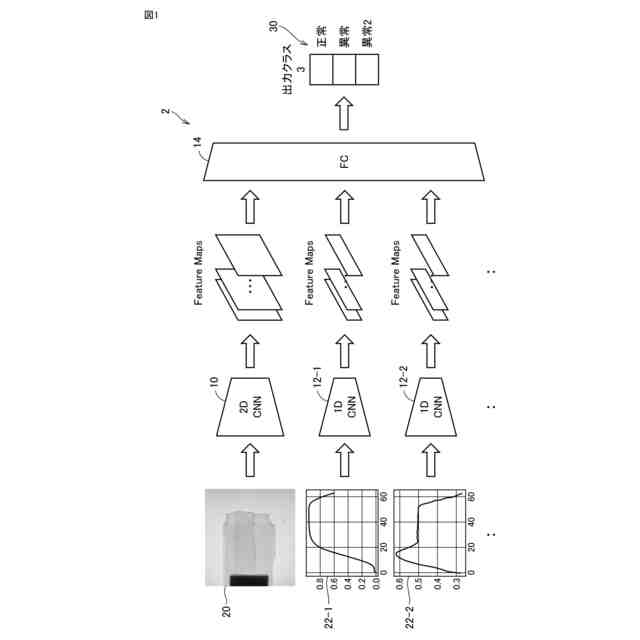
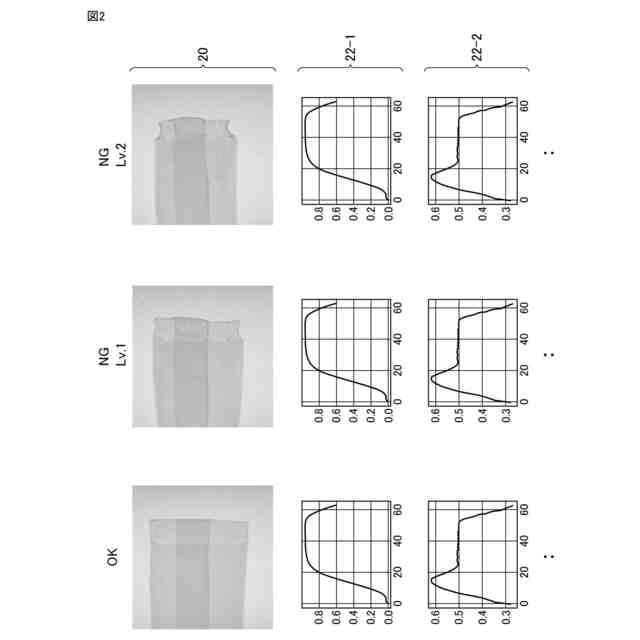
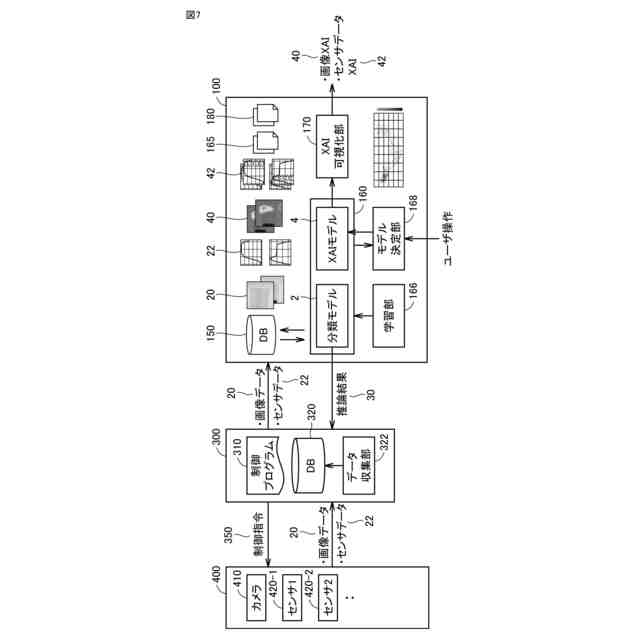
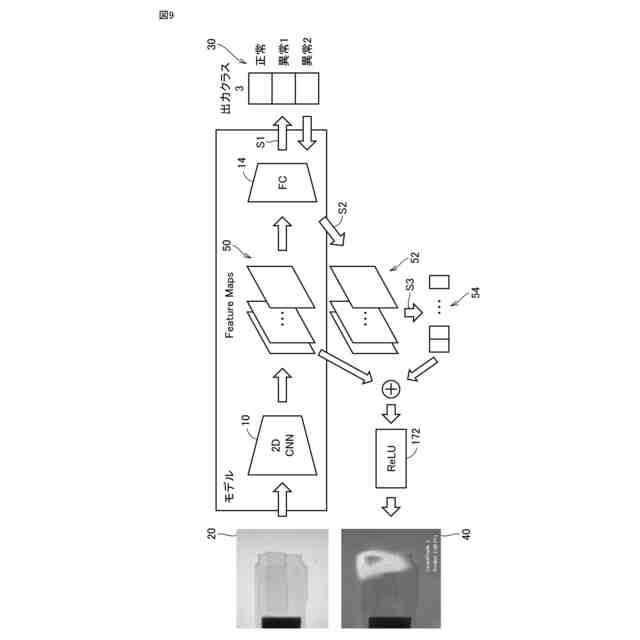
発明の詳細な説明【技術分野】 【0001】 本発明は、情報処理装置および情報処理プログラムに関する。 続きを表示(約 1,700 文字)【背景技術】 【0002】 生産現場においても、学習済モデルを用いた異常検知などの機能が実用化されている。このような学習済モデルがどのように判断を行ったのかを可視化する技術が知られている。このような技術は、説明可能なAI(XAI:Explainable AI)と称されることもある。 【0003】 例えば、画像認識モデルにおいて、入力と対応する推論とについて、入力のいずれの部分を推論の根拠にしているかを顕著性マップで可視化する技術が公知である(例えば、非特許文献1など)。また、テーブルデータに対して、入力と対応する推論とについて、いずれのデータを推論の根拠にしているかをグラフで可視化する技術が公知である(例えば、非特許文献2など)。 【先行技術文献】 【非特許文献】 【0004】 "Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization", Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra, 2017 IEEE International Conference on Computer Vision (ICCV), 22-29 October 2017, <URL:https://arxiv.org/abs/1610.02391> "A Unified Approach to Interpreting Model Predictions", Scott M. Lundberg, Su-In Lee, Part of Advances in Neural Information Processing Systems 30 (NIPS 2017), Jan 24th, 2018, < URL:https://arxiv.org/abs/1602.049 > 【発明の概要】 【発明が解決しようとする課題】 【0005】 複数種類のデータを入力して推論を行うタスクにおいて、上述したようなXAIは開示されていない。 【0006】 本発明は、複数種類のデータが入力される学習済モデルの解釈性を高める方法を提供することを一つの目的とする。 【課題を解決するための手段】 【0007】 本発明の一例に従う情報処理装置は、1または複数の第1のデータと、1または複数の第1のデータとはデータ形式が異なる1または複数の第2のデータとを第1の学習済モデルに入力して推論結果を算出する算出部と、1または複数の第1のデータおよび1または複数の第2のデータのうち少なくとも1つのデータについて、第1の学習済モデルが推論結果を算出するために着目した部分を示す顕著性マップを生成する生成部とを含む。 【0008】 この構成によれば、データ形式が異なる複数種類のデータを学習済モデルに入力することで、多面的な推論結果を算出できる。また、当該学習済モデルが推論結果を算出するために着目した部分を示す顕著性マップが生成されるので、入力されるデータがどのように着目されているのかをユーザが把握することを支援できる。 【0009】 1または複数の第1のデータの各々は、画像データを含んでもよい。1または複数の第2のデータの各々は、スカラ値の時系列データを含んでもよい。この構成によれば、製造ラインなどから収集される複数種類のデータを用いた学習済モデルに基づく推論を容易に行うことができる。 【0010】 生成部は、第1の学習済モデルに比較して、学習が不足している第2の学習済モデルを用いて、顕著性マップを生成してもよい。この構成によれば、学習が不足している第2の学習済モデルを用いることで、第1の学習済モデルの解釈性をより高めることができる。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する


 特許ウォッチ
特許ウォッチ