TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025174291
公報種別
公開特許公報(A)
公開日
2025-11-28
出願番号
2024080476
出願日
2024-05-16
発明の名称
データ処理装置、データ処理方法、及びデータ処理プログラム
出願人
ソフトバンクグループ株式会社
代理人
弁理士法人太陽国際特許事務所
主分類
G10L
13/10 20130101AFI20251120BHJP(楽器;音響)
要約
【課題】本開示は、電子コンテンツに基づいて生成モデルから出力される人工音声の質を高めるデータ処理装置、方法及びプログラムを提供する。
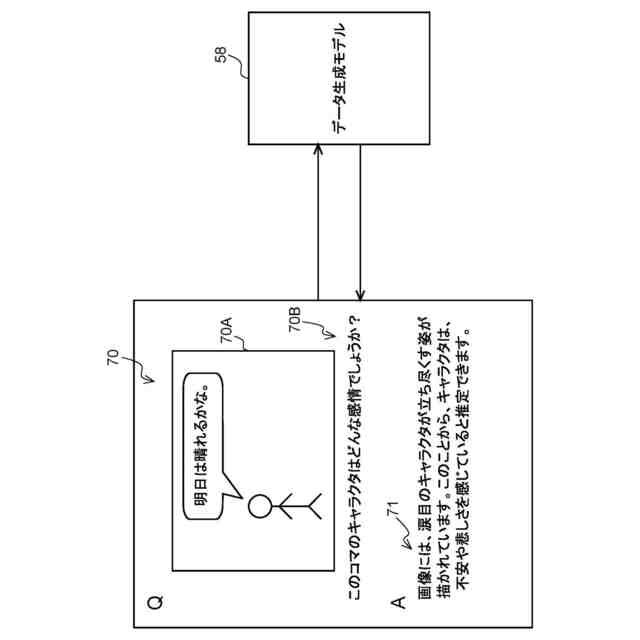
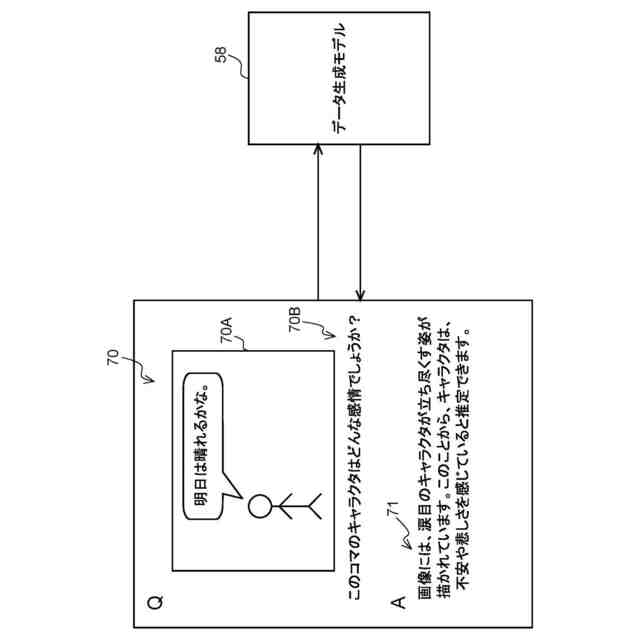
【解決手段】データ処理装置は、プロセッサを備え、前記プロセッサは、テキスト及びイラストを含むコンテンツが電子化された電子コンテンツを取得し、前記コンテンツにおいて予め定めた一区画単位に区画されたうちの特定区画の画像(コマ画像70A)と、前記特定区画の画像に示されるキャラクタの感情を推定する指示を示す指示文70Bとを含んだプロンプト70を、入力データに応じた情報を生成する生成モデルに入力し、前記電子コンテンツを表示可能な表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記生成モデルが推定した前記キャラクタの感情に基づいて生成された人工音声で出力部から出力させる。
【選択図】図3
特許請求の範囲
【請求項1】
プロセッサを備え、
前記プロセッサは、
テキスト及びイラストを含むコンテンツが電子化された電子コンテンツを取得し、
前記コンテンツにおいて予め定めた一区画単位に区画されたうちの特定区画の画像と、前記特定区画の画像に示されるキャラクタの感情を推定する指示とを含んだプロンプトを、入力データに応じた情報を生成する生成モデルに入力し、
前記電子コンテンツを表示可能な表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記生成モデルが推定した前記キャラクタの感情に基づいて生成された人工音声で出力部から出力させる、
データ処理装置。
続きを表示(約 1,800 文字)
【請求項2】
前記プロセッサは、
前記特定区画の画像にオノマトペが含まれる場合、前記特定区画の画像と、前記オノマトペを解釈する指示とを含んだプロンプトを、前記生成モデルに入力し、
前記表示部に前記特定区画の画像が表示された場合、前記生成モデルが出力した前記オノマトペの解釈結果に基づいて生成された効果音を前記出力部から出力させる、
請求項1に記載のデータ処理装置。
【請求項3】
前記プロセッサは、
前記表示部に前記特定区画の画像が表示されている間に、ユーザによる所定操作を受け付けた場合、前記生成モデルが生成した前記キャラクタの感情の推定内容を、所定の人工音声で前記出力部から出力させる、
請求項1に記載のデータ処理装置。
【請求項4】
前記プロセッサは、
前記出力部からの前記特定区画の画像に応じた音の出力が終了した場合、前記出力部による音出力機能及び振動部による振動機能の少なくとも一方を用いて、特定の音の出力及び特定の振動の発生の少なくとも一方を行う、
請求項1に記載のデータ処理装置。
【請求項5】
前記プロセッサは、
前記コンテンツが映像化されている場合、所定の声質の人工音声を出力可能な仮想役者が複数記憶された役者データベースから、前記キャラクタの声を担当した特定の役者に対応する特定の仮想役者を抽出し、
前記表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記特定の仮想役者による人工音声で前記出力部から出力させる、
請求項1に記載のデータ処理装置。
【請求項6】
前記プロセッサは、
前記特定の役者が複数人存在する場合、複数の前記特定の役者の中からユーザによる一の役者の選択を受け付け、
前記役者データベースから、選択を受け付けた前記一の役者に対応する第1仮想役者を抽出し、
前記表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記第1仮想役者による人工音声で前記出力部から出力させる、
請求項5に記載のデータ処理装置。
【請求項7】
前記プロセッサは、
前記コンテンツが映像化されていない場合、前記電子コンテンツを前記生成モデルに入力して解釈した前記キャラクタの特徴を取得し、
取得した前記キャラクタの特徴と、当該特徴に適した声質を有する役者を尋ねる指示とを含んだプロンプトを、前記生成モデルに入力し、
所定の声質の人工音声を出力可能な仮想役者が複数記憶された役者データベースから、前記生成モデルが出力した役者に対応する第2仮想役者を抽出し、
前記表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記第2仮想役者による人工音声で前記出力部から出力させる、
請求項1に記載のデータ処理装置。
【請求項8】
テキスト及びイラストを含むコンテンツが電子化された電子コンテンツを取得し、
前記コンテンツにおいて予め定めた一区画単位に区画されたうちの特定区画の画像と、前記特定区画の画像に示されるキャラクタの感情を推定する指示とを含んだプロンプトを、入力データに応じた情報を生成する生成モデルに入力し、
前記電子コンテンツを表示可能な表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記生成モデルが推定した前記キャラクタの感情に基づいて生成された人工音声で出力部から出力させる、
処理をコンピュータが実行するデータ処理方法。
【請求項9】
テキスト及びイラストを含むコンテンツが電子化された電子コンテンツを取得し、
前記コンテンツにおいて予め定めた一区画単位に区画されたうちの特定区画の画像と、前記特定区画の画像に示されるキャラクタの感情を推定する指示とを含んだプロンプトを、入力データに応じた情報を生成する生成モデルに入力し、
前記電子コンテンツを表示可能な表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記生成モデルが推定した前記キャラクタの感情に基づいて生成された人工音声で出力部から出力させる、
処理をコンピュータに実行させるデータ処理プログラム。
発明の詳細な説明
【技術分野】
【0001】
本開示の技術は、データ処理装置、データ処理方法、及びデータ処理プログラムに関する。
続きを表示(約 1,800 文字)
【背景技術】
【0002】
特許文献1には、少なくとも一つのプロセッサにより遂行される、ペルソナチャットボット制御方法であって、ユーザ発話を受信するステップと、前記ユーザ発話を、チャットボットのキャラクターに関する説明と関連した指示文を含むプロンプトに追加するステップと前記プロンプトをエンコードするステップと、前記エンコードしたプロンプトを言語モデルに入力して、前記ユーザ発話に応答するチャットボット発話を生成するステップ、を含む、方法が開示されている。
【先行技術文献】
【特許文献】
【0003】
特開2022-180282号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら従来技術では、上記の言語モデルのような生成モデルから出力される人工音声の質について未だ改善の余地がある。
【課題を解決するための手段】
【0005】
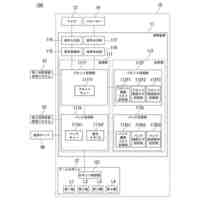
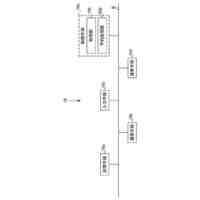
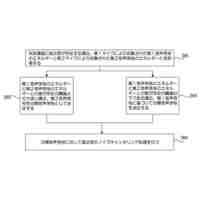
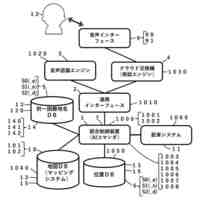
第1態様のデータ処理装置は、プロセッサを備え、前記プロセッサは、テキスト及びイラストを含むコンテンツが電子化された電子コンテンツを取得し、前記コンテンツにおいて予め定めた一区画単位に区画されたうちの特定区画の画像と、前記特定区画の画像に示されるキャラクタの感情を推定する指示とを含んだプロンプトを、入力データに応じた情報を生成する生成モデルに入力し、前記電子コンテンツを表示可能な表示部に前記特定区画の画像が表示された場合、前記特定区画における前記キャラクタの台詞を、前記生成モデルが推定した前記キャラクタの感情に基づいて生成された人工音声で出力部から出力させる。
【0006】
第1態様のデータ処理装置では、プロセッサは、電子コンテンツを取得する。生成モデルには、電子コンテンツにおける特定区画の画像と、特定区画の画像に示されるキャラクタの感情を推定する指示とを含んだプロンプトが入力される。そして、表示部に特定区画の画像が表示された場合、出力部からは、生成モデルが推定したキャラクタの感情に基づいて生成された人工音声で特定区画におけるキャラクタの台詞が出力される。これにより、当該データ処理装置によれば、出力部から抑揚のない人工音声が出力される構成に比べて、電子コンテンツに対するユーザの没入感を高めることができる。
【0007】
第2態様のデータ処理装置は、第1態様において、前記プロセッサは、前記特定区画の画像にオノマトペが含まれる場合、前記特定区画の画像と、前記オノマトペを解釈する指示とを含んだプロンプトを、前記生成モデルに入力し、前記表示部に前記特定区画の画像が表示された場合、前記生成モデルが出力した前記オノマトペの解釈結果に基づいて生成された効果音を前記出力部から出力させる。
【0008】
第2態様のデータ処理装置では、特定区画の画像にオノマトペが含まれる場合、生成モデルには、特定区画の画像と、オノマトペを解釈する指示とを含んだプロンプトが入力される。そして、表示部に特定区画の画像が表示された場合、出力部からは、生成モデルが出力したオノマトペの解釈結果に基づいて生成された効果音が出力される。これにより、当該データ処理装置によれば、オノマトペに応じた効果音が出力部から出力されない構成に比べて、電子コンテンツに対するユーザの没入感を高めることができる。
【0009】
第3態様のデータ処理装置は、第1態様又は第2態様において、前記プロセッサは、前記表示部に前記特定区画の画像が表示されている間に、ユーザによる所定操作を受け付けた場合、前記生成モデルが生成した前記キャラクタの感情の推定内容を、所定の人工音声で前記出力部から出力させる。
【0010】
第3態様のデータ処理装置では、表示部に特定区画の画像が表示されている間に、ユーザによる所定操作を受け付けた場合、出力部からは、生成モデルが生成したキャラクタの感情の推定内容が所定の音声で出力される。これにより、当該データ処理装置によれば、キャラクタの台詞のみが音声出力される構成に比べて、電子コンテンツの内容に対するユーザの理解度を高めることができる。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
遮音材
23日前
個人
管楽器用リガチャ-
1か月前
個人
歌唱補助器具
1か月前
横浜ゴム株式会社
音響材
16日前
個人
音声出力装置
23日前
大和ハウス工業株式会社
音低減設備
1か月前
DIC株式会社
吸音材及び吸音部品
1か月前
個人
管楽器用音質改善留め具
10日前
NOK株式会社
吸音構造体
25日前
横浜ゴム株式会社
多層空洞音響材
23日前
矢崎総業株式会社
車両用対話システム
24日前
株式会社SinasSP
自動騒音低減装置
1か月前
株式会社第一興商
カラオケ装置
24日前
ヤマハ株式会社
鍵盤装置
3日前
大建工業株式会社
吸音体及び音環境調整構造
1か月前
ヤマハ株式会社
音処理装置及び音処理方法
10日前
有限会社ツバサ
エレキギターおよび保護フィルム付きの樹脂プレート
1か月前
有限会社 宮脇工房
モーター挙動音発生装置
1か月前
株式会社SUBARU
乗物用遮音構造体、及び車両
1か月前
株式会社デンソー
制御装置、制御方法、及び制御プログラム
16日前
株式会社第一興商
カラオケ装置、カラオケシステム
2日前
株式会社第一興商
カラオケ装置、カラオケシステム
18日前
株式会社コルグ
楽音信号変換装置、楽音信号変換方法、プログラム
26日前
固昌通訊股ふん有限公司
音響調整装置
1か月前
株式会社東芝
発話言語理解のためのシステムおよび方法
1か月前
株式会社枚方技研
方向付き楽器固定具
24日前
安克創新科技股フン有限公司
通話ノイズキャンセリング方法及びイヤホン
1か月前
カシオ計算機株式会社
情報処理装置、演奏装置、方法およびプログラム
1か月前
株式会社デンソー
制御装置、ロボットシステム、制御方法、及び制御プログラム
1か月前
日本放送協会
エンコーダー・デコーダー装置、推論装置、およびプログラム
1か月前
パイオニア株式会社
音声出力装置
1か月前
パイオニア株式会社
効果音出力装置
1か月前
エムケイ無線事業協同組合
音声応答システム、及びそれを利用した応答方法
1か月前
三菱ケミカル株式会社
共振シート部材、およびこれを備えた構造体
1か月前
ピクシーダストテクノロジーズ株式会社
遮音ユニット、遮音構造体、および区画設備
25日前
ヤマハ株式会社
音響信号処理装置、楽器、音響信号処理方法および音響信号処理プログラム
1か月前
続きを見る
他の特許を見る







 特許ウォッチ
特許ウォッチ