TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025158772
公報種別
公開特許公報(A)
公開日
2025-10-17
出願番号
2024061640
出願日
2024-04-05
発明の名称
学習装置、推定装置、学習方法、推定方法及びプログラム
出願人
本田技研工業株式会社
,
個人
代理人
弁理士法人大塚国際特許事務所
主分類
G06T
7/70 20170101AFI20251009BHJP(計算;計数)
要約
【課題】参照位置を参照して指定される目標位置を精度よく推定する。
【解決手段】機械学習を行う学習装置は、入力データと正解データとを含む教師データを取得する取得部であって、入力データは、参照物体を含む入力画像と、参照物体を参照して目標位置を相対的に指定する入力テキストと、を含む、取得部と、入力データをモデルに入力することによって、目標位置を特定するための出力データを生成する生成部と、出力データと正解データとを損失関数に入力することによって得られる損失が低下するようにモデルのパラメータを更新する更新部と、を備える。モデルは、入力画像と入力テキストとに基づいて、参照物体を表す複数の特徴量であって、互いに異なる解像度を有する複数の特徴量を生成する第1のサブモデルと、複数の特徴量と入力テキストとに基づいて、出力データを生成する第2のサブモデルと、を含む。第2のサブモデルに、複数の特徴量のそれぞれが入力される。
【選択図】図4
特許請求の範囲
【請求項1】
機械学習を行う学習装置であって、
入力データと正解データとを含む教師データを取得する取得手段であって、前記入力データは、参照物体を含む入力画像と、前記参照物体を参照して目標位置を相対的に指定する入力テキストと、を含む、取得手段と、
前記入力データをモデルに入力することによって、前記目標位置を特定するための出力データを生成する生成手段と、
前記出力データと前記正解データとを損失関数に入力することによって得られる損失が低下するように前記モデルのパラメータを更新する更新手段と、を備え、
前記モデルは、
前記入力画像と前記入力テキストとに基づいて、前記参照物体を表す複数の特徴量であって、互いに異なる解像度を有する複数の特徴量を生成する第1のサブモデルと、
前記複数の特徴量と前記入力テキストとに基づいて、前記出力データを生成する第2のサブモデルと、を含み、
前記第2のサブモデルに、前記複数の特徴量のそれぞれが入力される、学習装置。
続きを表示(約 1,600 文字)
【請求項2】
前記モデルは、前記入力テキストから、前記参照物体に対する相対的な前記目標位置を表すテキストを抽出する第3のサブモデルをさらに含み、
前記第2のサブモデルは、前記複数の特徴量のそれぞれと、前記第3のサブモデルによって抽出された前記テキストとに基づいて、前記出力データを生成する、請求項1に記載の学習装置。
【請求項3】
前記モデルは、
前記入力テキストから、前記参照物体を表すテキストを抽出する第3のサブモデルと、
前記入力画像と、前記第3のサブモデルによって抽出された前記テキストとに基づいて、前記参照物体を表す特徴量を生成する第4のサブモデルと、をさらに含み、
前記第2のサブモデルは、前記第4のサブモデルによって生成された前記特徴量にさらに基づいて、前記出力データを生成する、請求項1に記載の学習装置。
【請求項4】
前記第1のサブモデルは、前記入力画像と前記入力テキストとに基づいて、前記参照物体の位置を表すデータをさらに生成し、
前記第4のサブモデルは、前記第1のサブモデルによって生成された前記データにさらに基づいて、前記参照物体を表す前記特徴量を生成する、請求項3に記載の学習装置。
【請求項5】
前記第1のサブモデルは、前記入力画像と前記入力テキストとに基づいて、前記参照物体の位置を表すデータをさらに生成し、
前記第2のサブモデルは、前記第1のサブモデルによって生成された前記データにさらに基づいて、前記出力データを生成する、請求項1に記載の学習装置。
【請求項6】
前記モデルは、
前記入力テキストから、前記参照物体を表すテキストを抽出する第3のサブモデルと、
前記入力画像と、前記第3のサブモデルによって抽出された前記テキストとに基づいて、前記参照物体を表す特徴量を生成する第4のサブモデルと、をさらに含み、
前記第1のサブモデルは、前記入力画像と前記入力テキストとに基づいて、前記参照物体の位置を表すデータをさらに生成し、
前記第2のサブモデルは、
前記入力テキストに基づいて前記複数の特徴量のそれぞれを変換することによって複数の中間特徴量を生成し、
前記複数の中間特徴量のそれぞれと、前記第1のサブモデルによって生成された前記データと、前記第4のサブモデルによって生成された前記特徴量とに基づいて、前記出力データを生成する、請求項1に記載の学習装置。
【請求項7】
前記入力画像は、車両のカメラによって撮影された画像を含む、請求項1に記載の学習装置。
【請求項8】
前記入力テキストは、自然言語によって表現される、請求項1に記載の学習装置。
【請求項9】
コンピュータを請求項1乃至8の何れか1項に記載された学習装置の各手段として機能させるためのプログラム。
【請求項10】
目標位置を推定する推定装置であって、
入力データを取得する取得手段であって、前記入力データは、参照物体を含む入力画像と、前記参照物体を参照して目標位置を相対的に指定する入力テキストと、を含む、取得手段と、
前記入力データをモデルに入力することによって、前記目標位置を特定するための出力データを生成する生成手段と、を備え、
前記モデルは、
前記入力画像と前記入力テキストとに基づいて、前記参照物体を表す複数の特徴量であって、互いに異なる解像度を有する複数の特徴量を生成する第1のサブモデルと、
前記複数の特徴量と前記入力テキストとに基づいて、前記出力データを生成する第2のサブモデルと、を含み、
前記第2のサブモデルに、前記複数の特徴量のそれぞれが入力される、推定装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、学習装置、推定装置、学習方法、推定方法及びプログラムに関する。
続きを表示(約 2,500 文字)
【背景技術】
【0002】
機械学習によって生成されたモデルを使用して車両の走行制御を行う様々な技術が提案されている。特許文献1には、車両によって取得されたセンサデータを使用して、ニューラルネットワークを学習することが記載されている。また、画像と言語とを入力とするマルチモーダルモデルを使用して、言語で指示された画像内の位置を推定する技術も提案されている。マルチモーダルモデルとして、FIBER(Fusion-In-the-Backbone-based transformER)(非特許文献1)やCLIP(Contrastive Language-Image Pre-training)(非特許文献2)、PWAN(Pixel-Word Attention Module)(非特許文献3)などが提案されている。
【先行技術文献】
【特許文献】
【0003】
特表2022-513866号公報
【非特許文献】
【0004】
Zi-Yi Dou, et al.,”Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone”,[online],令和4年11月18日,arXiv,[令和6年3月16日検索],インターネット<URL:https://arxiv.org/pdf/2206.07643.pdf>
Alec Radford, et al.,”Learning Transferable Visual Models From Natural Language Supervision”,[online],令和3年2月26日,arXiv,[令和6年3月16日検索],インターネット<URL:https://arxiv.org/pdf/2103.00020.pdf>
LAVT: Language-Aware Vision Transformer for Referring Image Segmentation Zhao Yang, et al.,”LAVT: Language-Aware Vision Transformer for Referring Image Segmentation”,[online],令和4年4月5日,arXiv,[令和6年3月16日検索],インターネット<URL:https://arxiv.org/pdf/2112.02244.pdf>
【発明の概要】
【発明が解決しようとする課題】
【0005】
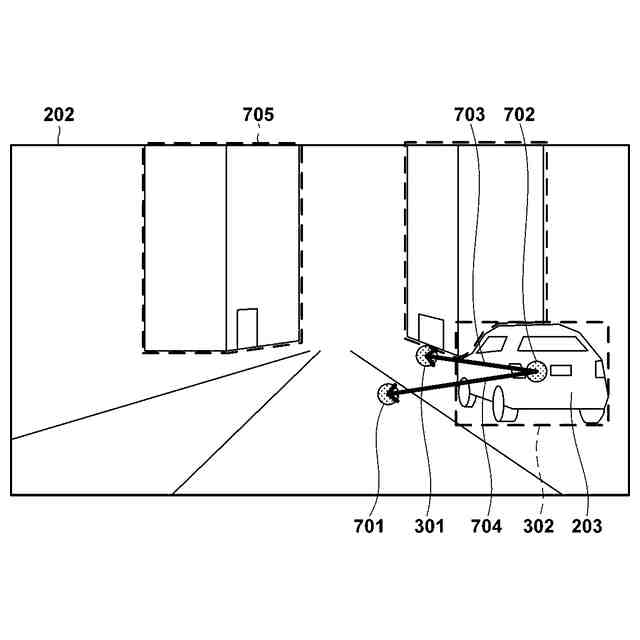
入力画像における目標位置は、入力画像に含まれる参照物体を参照して指定されうる。参照物体は、入力画像において様々な大きさを有しうる。本発明の1つの側面は、参照物体を参照して指定される目標位置を精度よく推定することを目的とする。
【課題を解決するための手段】
【0006】
一部の実施形態によれば、機械学習を行う学習装置であって、入力データと正解データとを含む教師データを取得する取得手段であって、前記入力データは、参照物体を含む入力画像と、前記参照物体を参照して目標位置を相対的に指定する入力テキストと、を含む、取得手段と、前記入力データをモデルに入力することによって、前記目標位置を特定するための出力データを生成する生成手段と、前記出力データと前記正解データとを損失関数に入力することによって得られる損失が低下するように前記モデルのパラメータを更新する更新手段と、を備え、前記モデルは、前記入力画像と前記入力テキストとに基づいて、前記参照物体を表す複数の特徴量であって、互いに異なる解像度を有する複数の特徴量を生成する第1のサブモデルと、前記複数の特徴量と前記入力テキストとに基づいて、前記出力データを生成する第2のサブモデルと、を含み、前記第2のサブモデルに、前記複数の特徴量のそれぞれが入力される、学習装置が提供される。
【発明の効果】
【0007】
一部の実施形態によれば、参照位置を参照して指定される目標位置を精度できる。
【図面の簡単な説明】
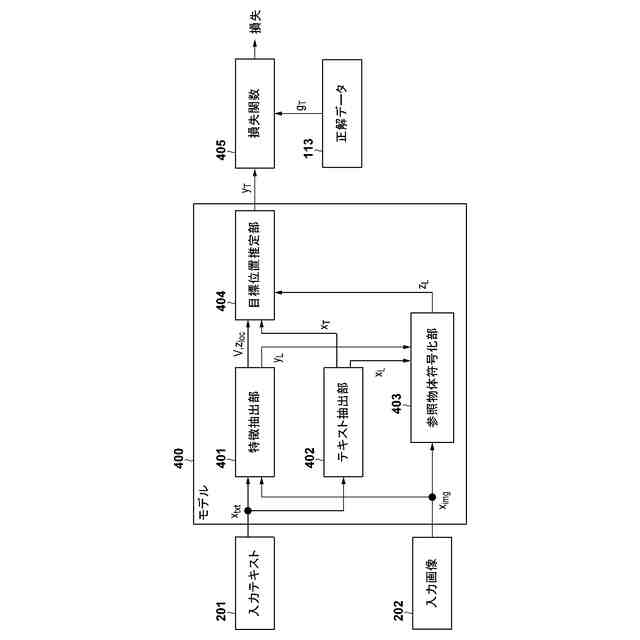
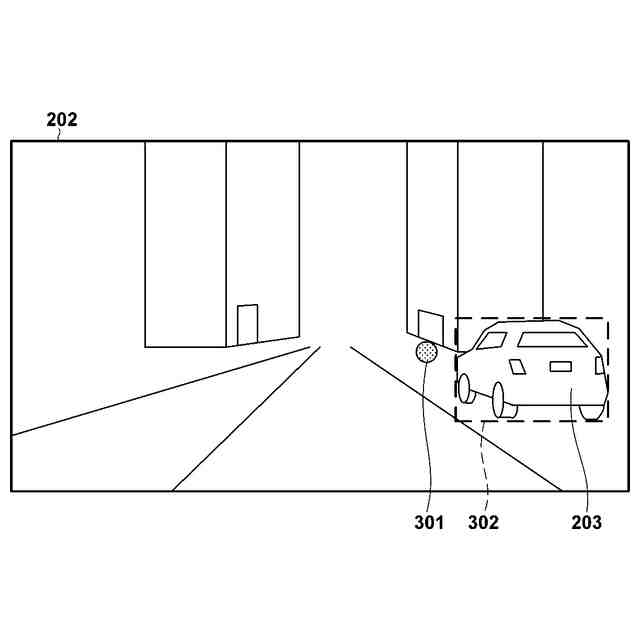
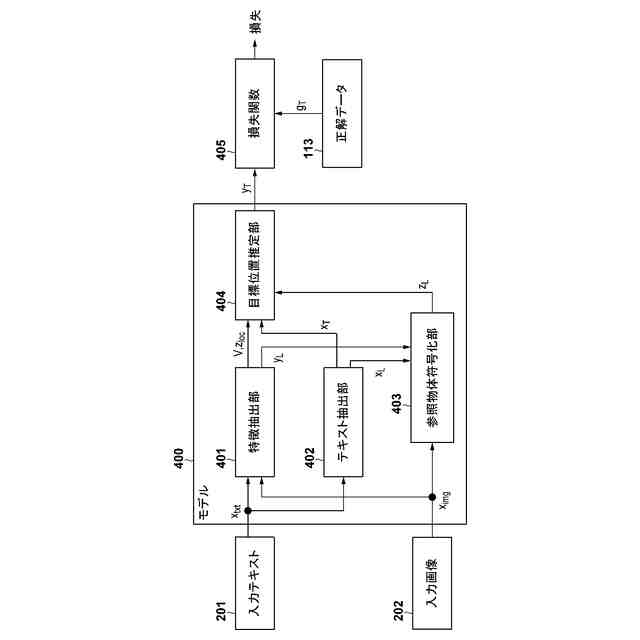
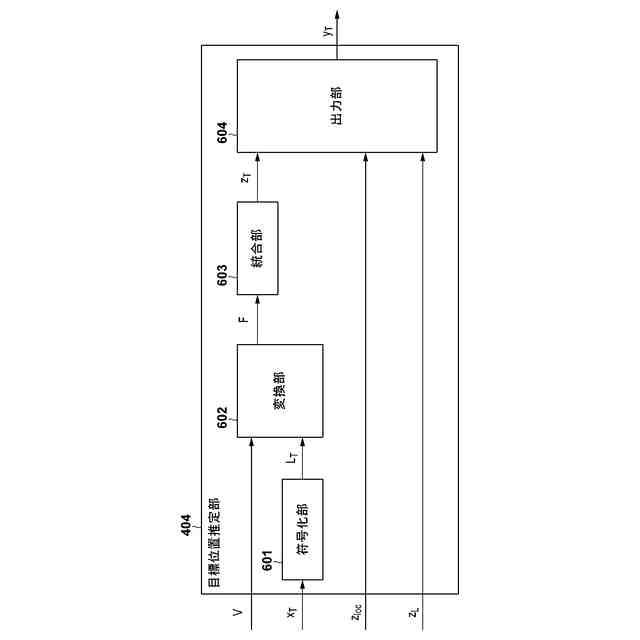
【0008】
一部の実施形態に係るコンピュータのハードウェア構成例を説明するブロック図。
一部の実施形態に係る入力データの例を説明する模式図。
一部の実施形態に係る正解データの例を説明する模式図。
一部の実施形態に係るモデルの構成例を説明する模式図。
一部の実施形態に係る特徴抽出部の構成例を説明する模式図。
一部の実施形態に係る目標位置推定部の構成例を説明する模式図。
一部の実施形態に係る損失関数の例を説明する模式図。
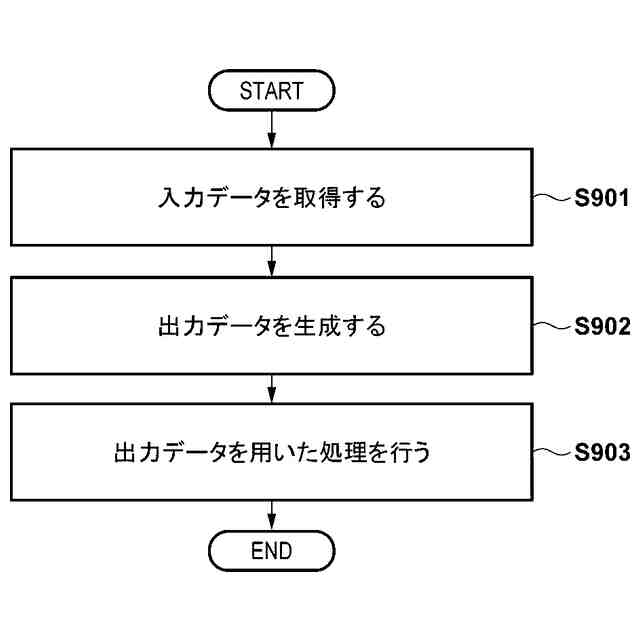
一部の実施形態に係る学習方法の例を説明するフロー図。
一部の実施形態に係る推定方法の例を説明するフロー図。
【発明を実施するための形態】
【0009】
以下、添付図面を参照して実施形態を詳しく説明する。なお、以下の実施形態は特許請求の範囲に係る発明を限定するものではなく、また実施形態で説明されている特徴の組み合わせの全てが発明に必須のものとは限らない。実施形態で説明されている複数の特徴のうち二つ以上の特徴は任意に組み合わされてもよい。また、同一若しくは同様の構成には同一の参照番号を付し、重複した説明は省略する。
【0010】
図1を参照して、一部の実施形態に係るコンピュータ100のハードウェア構成例について説明する。以下に詳細に説明されるように、コンピュータ100は、機械学習によってモデルを学習するために使用される。そのため、コンピュータ100は、学習装置と呼ばれてもよい。コンピュータ100は、例えばサーバコンピュータであってもよいし、パーソナルコンピュータ(例えば、デスクトップ型又はラップトップ型)であってもよい。コンピュータ100は、クラウド環境上に配置されたコンピュータリソースであってもよい。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
詐欺保険
1か月前
個人
縁伊達ポイン
1か月前
個人
RFタグシート
1か月前
個人
職業自動販売機
23日前
個人
5掛けポイント
1か月前
個人
ペルソナ認証方式
1か月前
個人
自動調理装置
1か月前
個人
情報処理装置
1か月前
個人
立体グラフの利用方法
2日前
個人
農作物用途分配システム
1か月前
NISSHA株式会社
入力装置
3日前
個人
インターネットの利用構造
1か月前
個人
サービス情報提供システム
25日前
個人
タッチパネル操作指代替具
1か月前
個人
スケジュール調整プログラム
1か月前
個人
携帯端末障害問合せシステム
1か月前
個人
学習用データ生成装置
4日前
個人
エリアガイドナビAIシステム
1か月前
キヤノン株式会社
情報処理装置
1か月前
株式会社ワコム
電子ペン
1か月前
株式会社ワコム
電子ペン
1か月前
株式会社ケアコム
項目選択装置
1か月前
キヤノン株式会社
画像認識装置
17日前
キラル株式会社
顧客体験提供システム
5日前
トヨタ自動車株式会社
通知装置
1か月前
エッグス株式会社
情報処理装置
1か月前
キヤノン株式会社
印刷システム
1か月前
キヤノン株式会社
情報処理装置
17日前
キヤノン株式会社
情報処理装置
17日前
株式会社ケアコム
項目選択装置
1か月前
太陽誘電株式会社
表示装置
1か月前
キヤノン電子株式会社
情報処理システム
2日前
株式会社アジラ
行動推定システム
17日前
株式会社ITP
仮想展示システム
11日前
大同大學
スーパーアプリ構築方法
17日前
トヨタ自動車株式会社
車両
1か月前
続きを見る
他の特許を見る




 特許ウォッチ
特許ウォッチ