TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025080215
公報種別
公開特許公報(A)
公開日
2025-05-23
出願番号
2024102458
出願日
2024-06-26
発明の名称
3次元オブジェクト認識方法及び装置
出願人
三星電子株式会社
,
Samsung Electronics Co.,Ltd.
代理人
個人
,
個人
主分類
G06T
7/00 20170101AFI20250516BHJP(計算;計数)
要約
【課題】3次元オブジェクト認識方法及び装置が提供される。
【解決手段】その方法は、3次元空間に関する入力映像、3次元空間に関する入力ポイントクラウド、及び3次元空間内のターゲットオブジェクトに関する入力言語を受信し、エンコーディングモデルを用いて入力映像の部分領域の候補映像特徴、入力ポイントクラウドのポイントクラウド特徴、及び入力言語の言語特徴を生成し、候補映像特徴と言語特徴との間の類似度の類似度スコアに基づいて、候補映像特徴のうち言語特徴に対応するターゲット映像特徴を選択し、ターゲット映像特徴及びポイントクラウド特徴に基づいてマルチモーダルデコーディングモデルを動作させてデコーディング出力を生成し、デコーディング出力に基づいてオブジェクト検出モデルを動作させ、ターゲットオブジェクトに対応する3次元バウンディングボックスを検出するステップを含む。
【選択図】図1
特許請求の範囲
【請求項1】
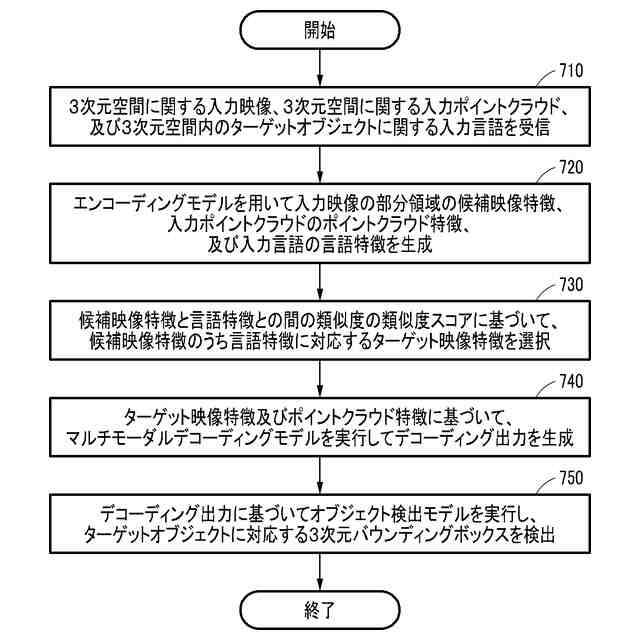
3次元空間に関する入力映像、3次元空間に関する入力ポイントクラウド、及び3次元空間内のターゲットオブジェクトに関する入力言語を受信するステップと、
エンコーディングモデルを用いて前記入力映像の部分領域の候補映像特徴、前記入力ポイントクラウドのポイントクラウド特徴、及び前記入力言語の言語特徴を生成するステップと、
前記候補映像特徴と前記言語特徴との間の類似度の類似度スコアに基づいて、前記候補映像特徴のうち前記言語特徴に対応するターゲット映像特徴を選択するステップと、
前記ターゲット映像特徴及び前記ポイントクラウド特徴に基づいてマルチモーダルデコーディングモデルを動作させ、デコーディング出力を生成するステップと、
前記デコーディング出力に基づいてオブジェクト検出モデルを動作させ、前記ターゲットオブジェクトに対応する3次元バウンディングボックスを検出するステップと、
を含む、3次元オブジェクト認識方法。
続きを表示(約 1,300 文字)
【請求項2】
前記候補映像特徴、前記ポイントクラウド特徴、及び前記言語特徴を生成するステップは、
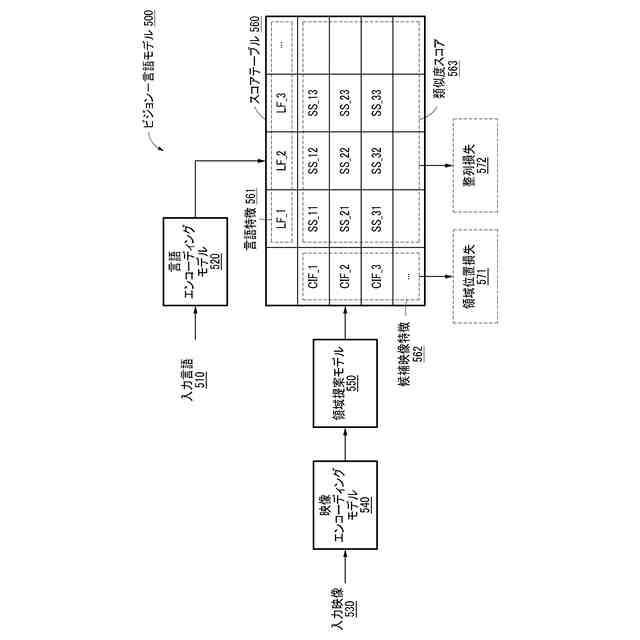
前記入力言語に基づいて言語エンコーディングモデルを動作させ、前記入力言語に対応する言語特徴を生成するステップと、
前記入力映像に基づいて映像エンコーディングモデル及び領域提案モデルを動作させ、前記入力映像の部分領域に対応する候補映像特徴を生成するステップと、
前記入力ポイントクラウドに基づいてポイントクラウドエンコーディングモデルを動作させ、前記入力ポイントクラウドに対応するポイントクラウド特徴を生成するステップと、
を含む、請求項1に記載の3次元オブジェクト認識方法。
【請求項3】
前記入力言語に基づいて前記ターゲットオブジェクトの幾何学的な特性を示す位置フィールド、及び前記ターゲットオブジェクトのクラスを示すクラスフィールドをそれぞれ含む拡張された表現が生成され、
前記拡張された表現に基づいて前記言語特徴が生成される、請求項1に記載の3次元オブジェクト認識方法。
【請求項4】
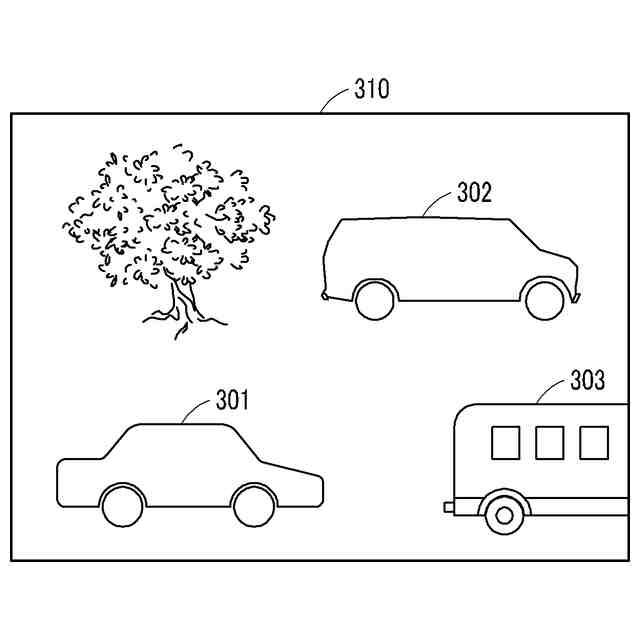
前記位置フィールドに基づいて他の幾何学的な特性の同じクラスのオブジェクトが区分される、請求項3に記載の3次元オブジェクト認識方法。
【請求項5】
前記位置フィールドは学習可能な特性を有する、請求項3に記載の3次元オブジェクト認識方法。
【請求項6】
前記デコーディング出力を生成するステップは、
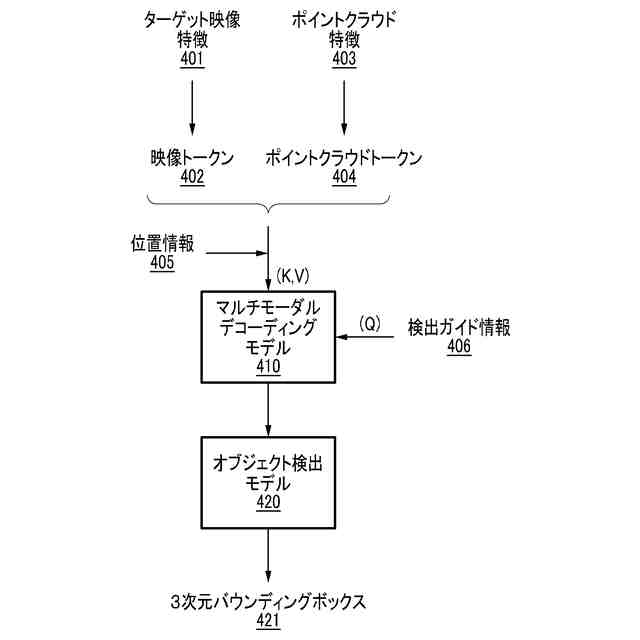
前記ターゲット映像特徴を分割して映像トークンを生成するステップと、
前記ポイントクラウド特徴を分割してポイントクラウドトークンを生成するステップと、
前記映像トークンの相対的な位置を示す第1位置情報を生成するステップと、
前記ポイントクラウドトークンの相対的な位置を示す第2位置情報を生成するステップと、
前記映像トークン、前記ポイントクラウドトークン、前記第1位置情報、及び前記第2位置情報に基づいたキーデータ及びバリューデータで前記マルチモーダルデコーディングモデルを動作させるステップと、
を含む、請求項1に記載の3次元オブジェクト認識方法。
【請求項7】
前記デコーディング出力を生成するステップは、前記3次元空間で前記ターゲットオブジェクトが検出される可能性のある検出位置候補を示す検出ガイド情報に基づいたクエリデータで前記マルチモーダルデコーディングモデルを動作させるステップを含む、請求項6に記載の3次元オブジェクト認識方法。
【請求項8】
前記検出位置候補は非均一な位置を示す、請求項7に記載の3次元オブジェクト認識方法。
【請求項9】
前記マルチモーダルデコーディングモデルは、前記ターゲット映像特徴、前記ポイントクラウド特徴、及び前記検出ガイド情報から関連性を抽出して前記デコーディング出力を生成する、請求項7に記載の3次元オブジェクト認識方法。
【請求項10】
請求項1~請求項9のいずれか一項に記載の3次元オブジェクト認識方法をコンピュータに実行させるコンピュータプログラム。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
以下の実施形態は、3次元オブジェクト認識方法及び装置に関する。
続きを表示(約 2,500 文字)
【背景技術】
【0002】
認識プロセスの技術的な自動化は、例えば、特殊な算出構造としてプロセッサで具現されたニューラルネットワークモデルを介して具現され、これは相当なトレーニング後に入力パターンと出力パターンとの間で算出上に直観的なマッピングを提供することができる。このようなマッピングを生成するトレーニングされた能力は、ニューラルネットワークモデルの学習能力という。さらに、特化したトレーニングにより、このように特化してトレーニングされたニューラルネットワークモデルは、例えばトレーニングしていない入力パターンに対して比較的に正確な出力を発生させる一般化能力(又は汎化能力)を有し得る。
【発明の概要】
【発明が解決しようとする課題】
【0003】
以下の実施形態は、3次元オブジェクト認識方法及び装置を提供することにその目的がある。
【課題を解決するための手段】
【0004】
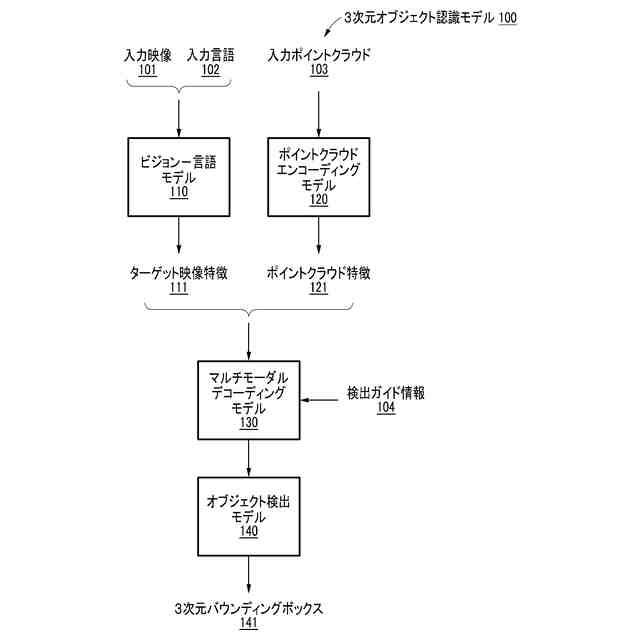
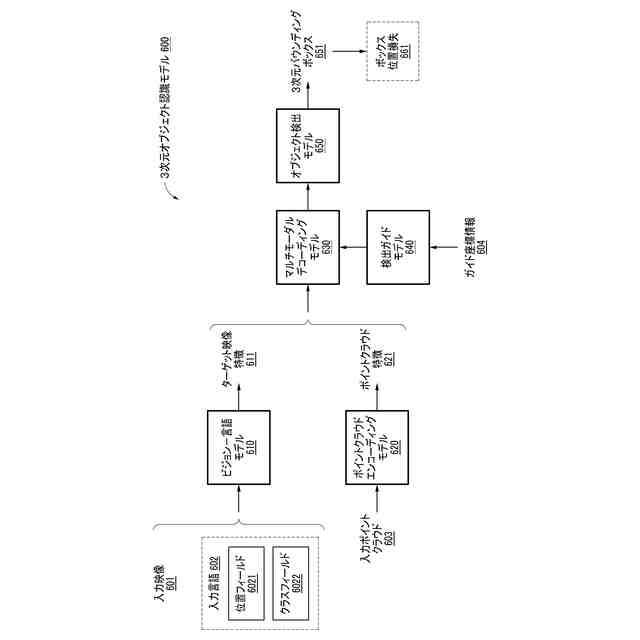
一実施形態によれば、3次元オブジェクト認識方法は、3次元空間に関する入力映像、3次元空間に関する入力ポイントクラウド、及び3次元空間内のターゲットオブジェクトに関する入力言語を受信するステップと、エンコーディングモデルを用いて入力映像の部分領域の候補映像特徴、入力ポイントクラウドのポイントクラウド特徴、及び入力言語の言語特徴を生成するステップと、候補映像特徴と言語特徴との間の類似度の類似度スコアに基づいて、候補映像特徴のうち言語特徴に対応するターゲット映像特徴を選択するステップと、ターゲット映像特徴及びポイントクラウド特徴に基づいてマルチモーダルデコーディングモデルを動作させ、デコーディング出力を生成するステップと、デコーディング出力に基づいてオブジェクト検出モデルを動作させ、ターゲットオブジェクトに対応する3次元バウンディングボックスを検出するステップとを含む。
【0005】
一実施形態に係る電子装置は、1つ以上のプロセッサと、命令語を格納するメモリと、を含み、命令語は、1つ以上のプロセッサによって、3次元空間に関する入力映像、3次元空間に関する入力ポイントクラウド、及び3次元空間内のターゲットオブジェクトに関する入力言語を受信し、エンコーディングモデルを用いて入力映像の部分領域の候補映像特徴、入力ポイントクラウドのポイントクラウド特徴、及び入力言語の言語特徴を生成し、候補映像特徴と言語特徴との間の類似度の類似度スコアに基づいて、候補映像特徴のうち言語特徴に対応するターゲット映像特徴を選択し、ターゲット映像特徴及びポイントクラウド特徴に基づいてマルチモーダルデコーディングモデルを動作させてデコーディング出力を生成し、デコーディング出力に基づいてオブジェクト検出モデルを動作させ、ターゲットオブジェクトに対応する3次元バウンディングボックスを検出するように設定される。
【0006】
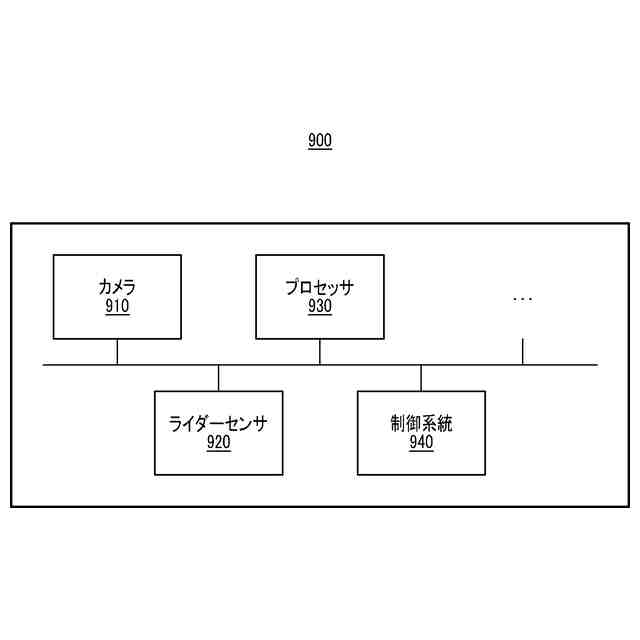
一実施形態に係る車両は、3次元空間に関する入力映像を生成するカメラと、3次元空間に関する入力ポイントクラウドを生成するライダーセンサと、3次元空間に関する入力映像、3次元空間に関する入力ポイントクラウド、及び3次元空間内のターゲットオブジェクトに関する入力言語を受信し、エンコーディングモデルを用いて入力映像の部分領域の候補映像特徴、入力ポイントクラウドのポイントクラウド特徴、及び入力言語の言語特徴を生成し、候補映像特徴と言語特徴との間の類似度の類似度スコアに基づいて、候補映像特徴のうち言語特徴に対応するターゲット映像特徴を選択し、ターゲット映像特徴及びポイントクラウド特徴に基づいてマルチモーダルデコーディングモデルを動作させてデコーディング出力を生成し、デコーディング出力に基づいてオブジェクト検出モデルを動作させ、ターゲットオブジェクトに対応する3次元バウンディングボックスを検出する、1つ以上のプロセッサと、3次元バウンディングボックスに基づいて車両を制御する制御系統とを含む。
【発明の効果】
【0007】
実施形態によれば、3次元オブジェクト認識方法及び装置を提供することができる。
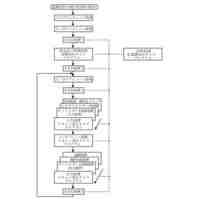
【図面の簡単な説明】
【0008】
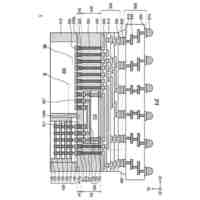
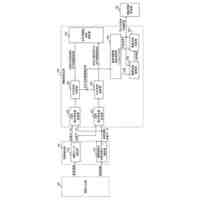
一実施形態に係る3次元オブジェクト認識モデルの構成を例示的に示す図である。
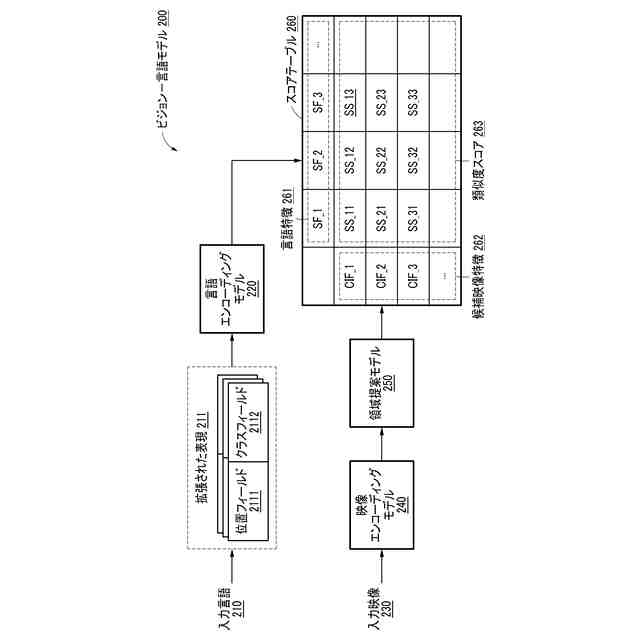
一実施形態に係るビジョン-言語モデルの構成を例示的に示す図である。
一実施形態に係る他の幾何学的な特性を有する同じクラスのオブジェクトを例示的に示す。
一実施形態に係るマルチモーダルデコーディングモデルの動作を例示的に示す図である。
一実施形態に係るビジョン-言語モデルのトレーニング過程を例示的に示す図である。
一実施形態に係る3次元オブジェクト認識モデルのトレーニング過程を例示的に示す図である。
一実施形態に係る3次元オブジェクト認識方法を例示的に示すフローチャートである。
一実施形態に係る電子装置の構成を例示的に示すブロック図である。
一実施形態に係る車両の構成を例示的に示すブロック図である。
【発明を実施するための形態】
【0009】
実施形態に対する特定な構造的又は機能的な説明は単なる例示のための目的として開示されたものであって、様々な形態に変更されることができる。したがって、実施形態は特定な開示形態に限定されるものではなく、本明細書の範囲は技術的な思想に含まれる変更、均等物ないし代替物を含む。
【0010】
第1又は第2などの用語を複数の構成要素を説明するために用いることがあるが、このような用語は1つの構成要素を他の構成要素から区別する目的としてのみ解釈されなければならない。例えば、第1構成要素は第2構成要素と命名することができ、同様に、第2構成要素は第1構成要素にも命名することができる。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
三星電子株式会社
イメージセンサー
8日前
三星電子株式会社
半導体パッケージ
9日前
三星電子株式会社
計測装置及び計測方法
今日
三星電子株式会社
半導体メモリ素子の製造方法
9日前
三星電子株式会社
イメージセンサー及びその製造方法
16日前
三星電子株式会社
集積回路素子、及びそれを含む電子システム
1日前
三星電子株式会社
熱交換器及びこの熱交換器を用いた空気調和機
15日前
三星電子株式会社
磁気トンネル接合素子及びこれを含むメモリ装置
19日前
三星電子株式会社
映像の復号化方法及び装置
6日前
三星電子株式会社
映像の復号化方法及び装置
6日前
三星電子株式会社
映像の復号化方法及び装置
6日前
個人
対話装置
6日前
個人
物品給付年金
1か月前
個人
非正規コート
2か月前
個人
情報処理装置
6日前
個人
政治のAI化
29日前
個人
人物再現システム
2か月前
個人
在宅介護システム
1か月前
個人
RFタグ読取装置
1か月前
個人
情報処理装置
2日前
個人
プラグインホームページ
20日前
個人
情報入力装置
6日前
個人
AI飲食最適化プラグイン
1か月前
キヤノン株式会社
通信装置
1か月前
個人
物価スライド機能付生命保険
6日前
有限会社ノア
データ読取装置
2か月前
個人
電話管理システム及び管理方法
1か月前
個人
マイホーム非電子入札システム
6日前
個人
全アルゴリズム対応型プログラム
1か月前
個人
広告提供システムおよびその方法
2か月前
キヤノン株式会社
画像処理装置
27日前
サクサ株式会社
カードの制動構造
8日前
シャープ株式会社
電子機器
29日前
個人
決済手数料0%のクレジットカード
9日前
株式会社CROSLAN
支援装置
1か月前
大同特殊鋼株式会社
輝線検出方法
29日前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ