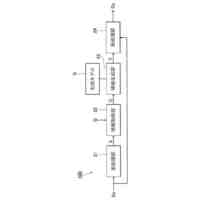
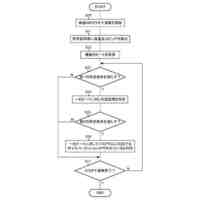
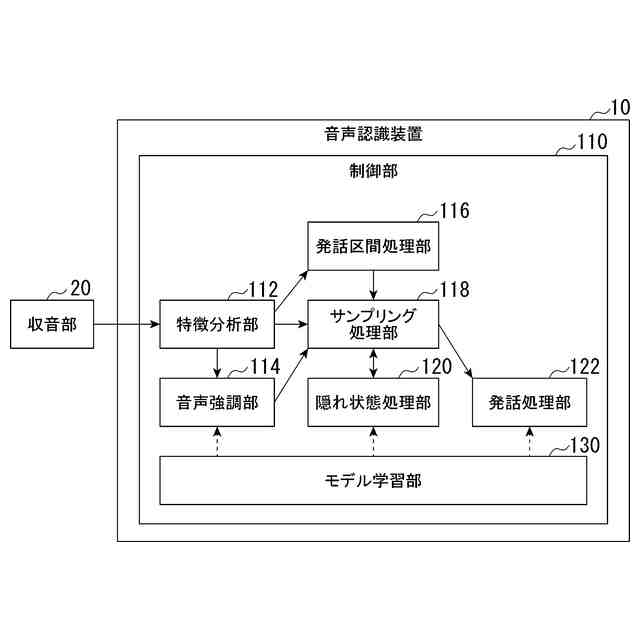
発明の詳細な説明【技術分野】 【0001】 本発明は、音声認識装置、音声認識方法、およびプログラムに関する。 続きを表示(約 2,300 文字)【背景技術】 【0002】 音声認識は、多様な用途を有し、さまざまな環境で用いられる。雑音が混入した音声を音声認識に用いると、雑音が混入されていないクリーン音声よりも認識率が低下することが知られている。雑音下で認識率を向上させるため、音声認識システムに対して音声強調が適用されることがある。音声強調によれば、収録された入力音声成分の音声成分が強調され、相対的に雑音成分が低減する。雑音抑圧は、音声強調の一形態として捉えることができる。 【0003】 音声強調を音声認識に適用した手法として、ミッシングデータ音声認識処理が提案されていた。例えば、非特許文献1、2に記載の手法では、エビデンス・モデル(evidence model)が適用される。エビデンス・モデルは、音声強調から音声認識に統計的情報を与えるデコード処理のモデルである。エビデンス・モデルは、認識結果を与える分類スコアの期待値を評価するための数理モデルとみなすことができ、誤分類を低減させるように学習された確率密度関数を用いて表わされる。 【先行技術文献】 【非特許文献】 【0004】 A. C. Morris, J. Baker, and H. Bourlard, “FROM MISSING DATA TO MAYBE USEFUL DATA: SOFT DATA MODELLING FOR NOISE ROBUST ASR”, Proceedings of Workshop Innovation Speech Process, 2001 M. Kuhne, R. Togneri, and S. Nordholm, “Recognition with Applications in Reverberant Multi-Source Environments”, IEEE Transactions on Audio, Speech and Language Processing, vol. 19, No. 2, pp. 372-384, 2011 【発明の概要】 【発明が解決しようとする課題】 【0005】 しかしながら、従来技術では、クリーン音源で学習した認識器に適用すると性能が上がるが、ノイズを含んだ音源で学習した認識器に適用すると性能が上がらないという問題があった。 【0006】 本発明は、上記の問題点に鑑みてなされたものであって、認識器の学習環境が異なっても、認識性能を向上させることができる音声認識装置、音声認識方法、およびプログラムを提供することを目的とする。 【課題を解決するための手段】 【0007】 (1)上記目的を達成するため、本発明の一態様に係る音声認識装置は、入力音声信号の音響特性に基づいて発話区間を定める発話区間処理部と、第1モデルを用いて前記入力音声信号の音響特徴量について音声成分が強調された強調特徴量をフレームごとに定める音声強調部と、第2モデルを用いて目標特徴量の系列である目標特徴量系列に基づいて隠れ状態特徴量の系列である隠れ状態特徴量系列を定める隠れ状態処理部と、発話区間内の前記強調特徴量の系列である強調特徴量系列と前記音響特徴量の系列である音響特徴量系列に対応する目標特徴量系列の確率分布を示す第3モデルを用いて当該目標特徴量系列のサンプル値を複数回サンプリングし、前記隠れ状態特徴量系列のサンプル値から前記隠れ状態特徴量系列の期待値を定めるサンプリング処理部と、第4モデルを用いて前記隠れ状態特徴量系列の期待値に基づいて前記発話区間の発話内容を定める発話処理部と、を備え、前記第3モデルはベータ分布の確率分布である。 【0008】 (2)また、本発明の一態様は、上記(1)の音声認識装置において、前記サンプリング処理部は、音声認識結果のスコアに基づき前記ベータ分布のパラメータを選択するようにしてもよい。 【0009】 (3)また、本発明の一態様は、上記(1)または(2)の音声認識装置において、前記音声強調部と、前記サンプリング処理部と、前記発話処理部と、は、 前記強調特徴量を確率変数として扱うことで、音声強調処理と音声認識処理とをベイズの定理を用いて統合するようにしてもよい。 【0010】 (4)また、本発明の一態様は、上記(1)から(3)のうちのいずれか1つの音声認識装置において、前記音声強調部は、音声強調用エンコーダと、音声強調用デコーダと、を備え、前記隠れ状態処理部は、音声認識用エンコーダ、を備え、前記発話処理部は、音声認識用デコーダ、を備え、前記音声強調用エンコーダは、入力される前記入力音声信号の観測スペクトルをエンコードして潜在変数を求め、前記潜在変数を前記音声強調用デコーダに出力し前記音声強調用デコーダは、入力される前記観測スペクトルと前記潜在変数をデコードして音声特徴量を推定し、推定した前記音響特徴量を前記第3モデルに出力し、前記第3モデルは、前記ベータ分布の確率分布を用いてサンプリングにより、前記推定された前記音響特徴量と前記観測スペクトルに内挿を行い、内挿した前記推定された前記音響特徴量を前記音声認識用エンコーダに出力し、前記音声認識用エンコーダは、前記内挿した前記推定された前記音響特徴量をエンコードして前記隠れ状態特徴量系列を前記音声認識用デコーダに出力し、前記音声認識用デコーダは、入力される前記隠れ状態特徴量系列をデコードして音声認識結果を出力するようにしてもよい。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する
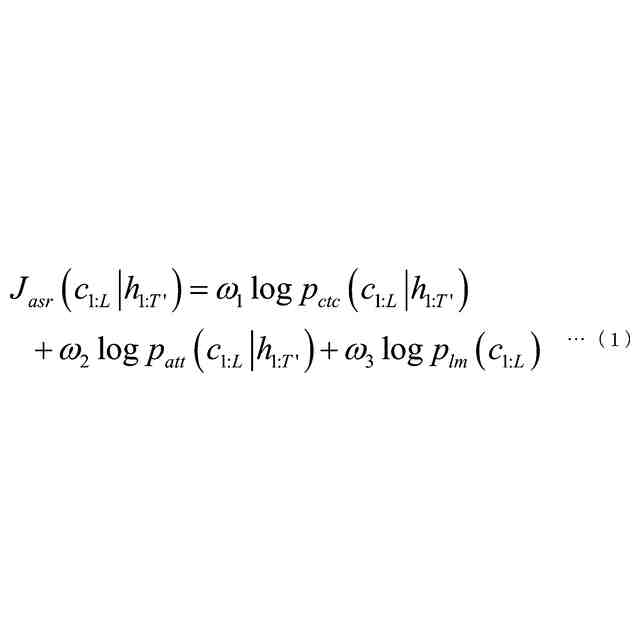
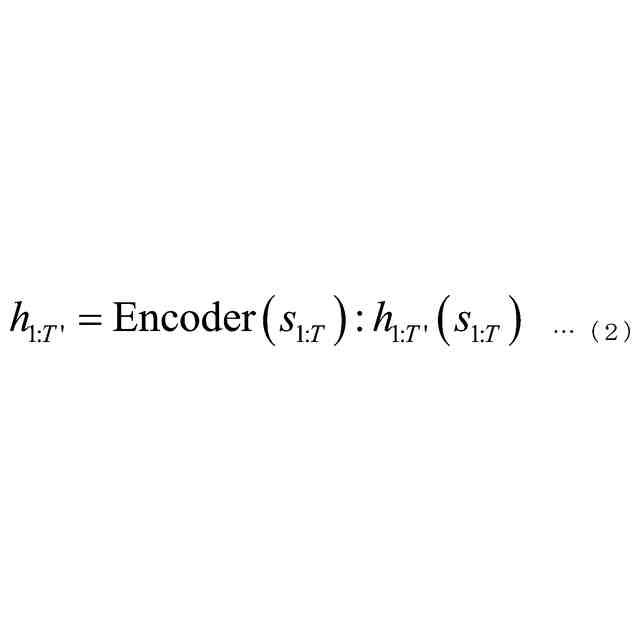
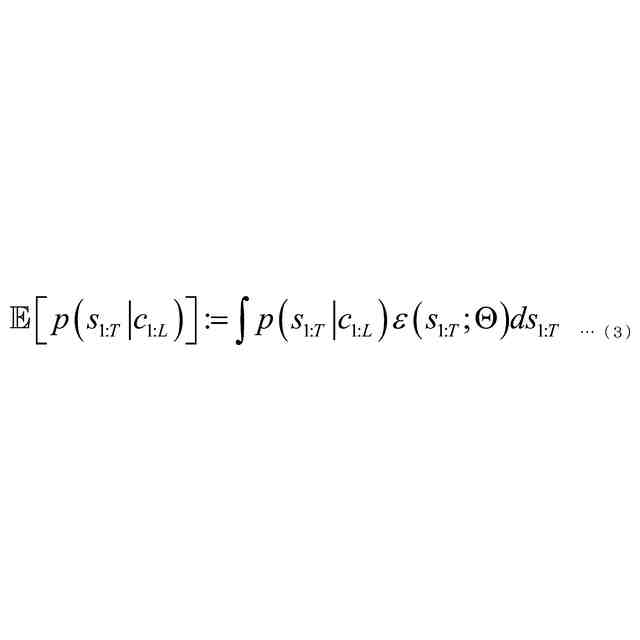
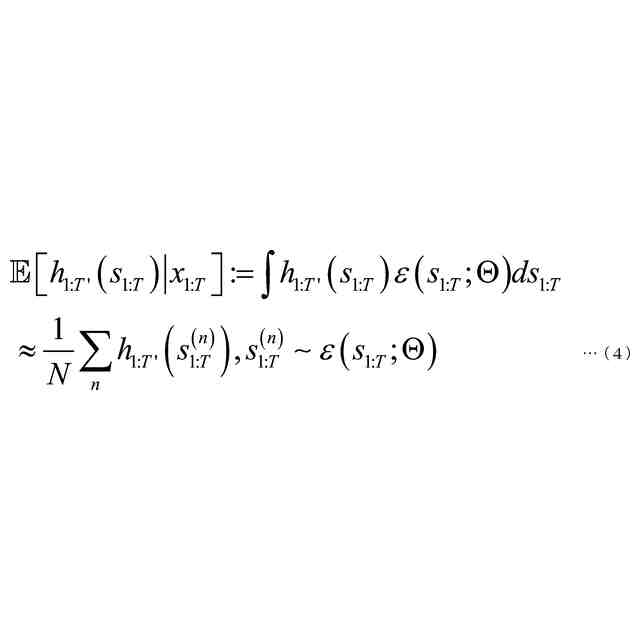
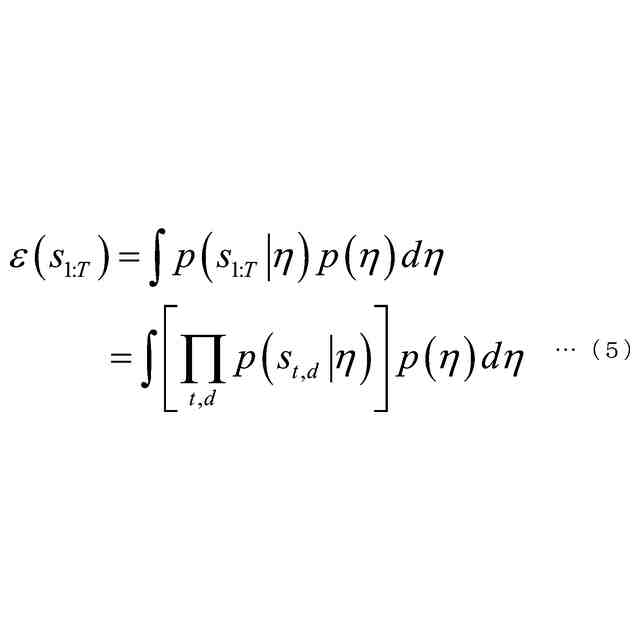
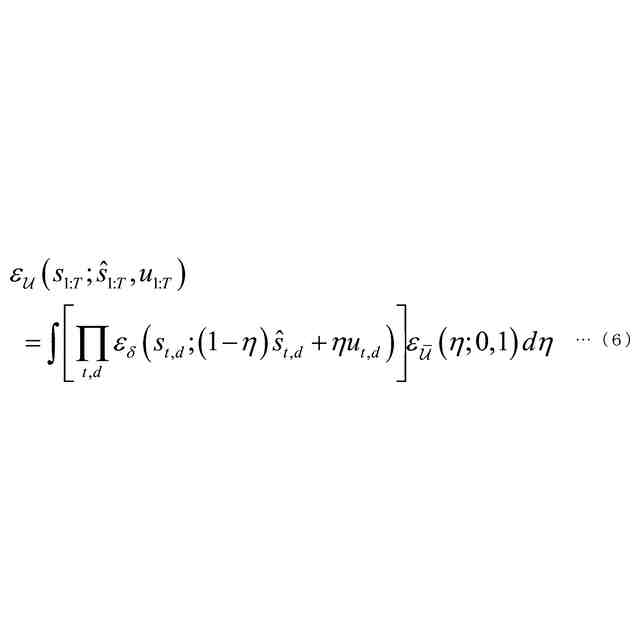
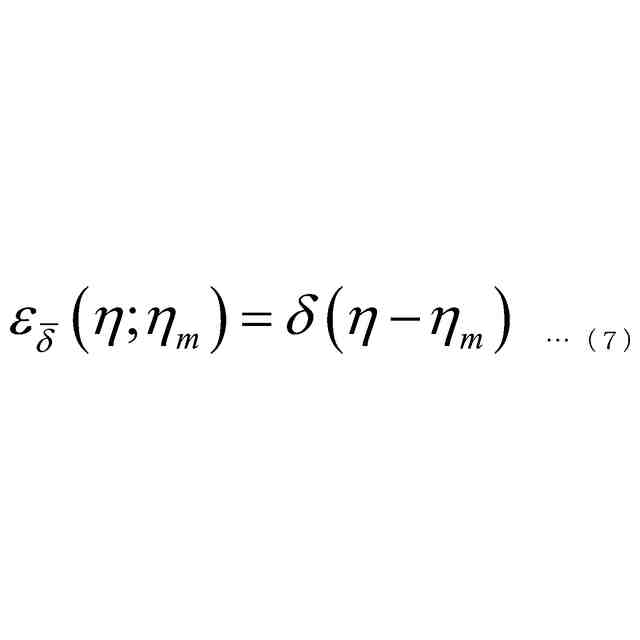
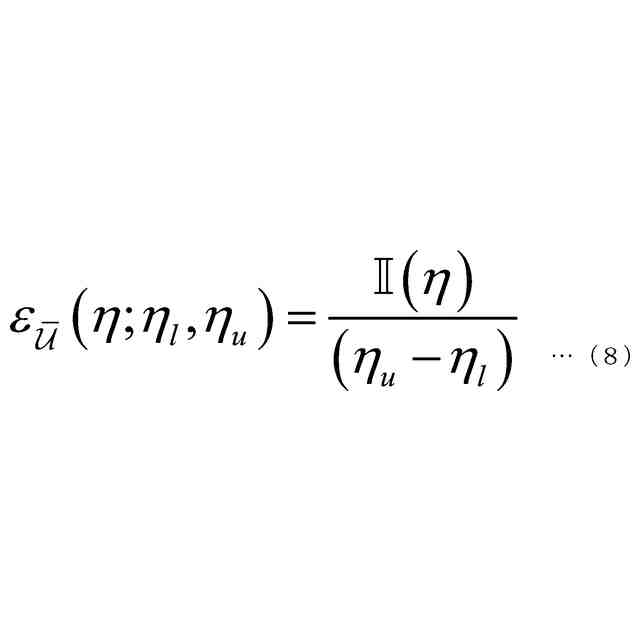
 特許ウォッチ
特許ウォッチ