TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2024163133
公報種別
公開特許公報(A)
公開日
2024-11-21
出願番号
2024147124,2023021323
出願日
2024-08-29,2019-11-27
発明の名称
音声入力処理
出願人
グーグル エルエルシー
,
Google LLC
代理人
個人
主分類
G10L
15/19 20130101AFI20241114BHJP(楽器;音響)
要約
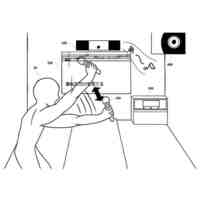
【課題】音声入力処理を実行する。
【解決手段】ユーザがコンピューティングデバイスを通じて音楽を聴いていることを示す文脈を判定し、発話のオーディオデータを受信し、発話についての1つ以上の候補転写を生成し、最高の転写信頼スコアを有する1つ以上の候補転写のうちの候補転写について、ユーザがコンピューティングデバイスを通じて音楽を聴いていることを示す文脈に基づいて文法を用いてパースを行って、コンピューティングデバイスが実行すべきアクションを識別する。
【選択図】図1
特許請求の範囲
【請求項1】
コンピュータにより実装される方法であって、データ処理ハードウェアによって実行されるとき、
ユーザによって行われて、前記ユーザに関連付けられているコンピューティングデバイスによってキャプチャされた発話のオーディオデータを受信することと、
前記オーディオデータから、前記発話に対応する複数の音素を判定することと、
前記発話に対応する前記複数の音素を用いて、前記発話についての1つ以上の候補転写を生成することであって、前記1つ以上の候補転写の各々は対応する転写信頼スコアを有する、生成することと、
ユーザが前記コンピューティングデバイスを通じて音楽を聴いていることを示す文脈を判定することと、
前記ユーザが前記コンピューティングデバイスを通じて音楽を聴いていることを示す前記文脈に基づいて、メディア再生コマンドを発行するとの特定のユーザの意図に対応している文法を選択することと、
最高の前記転写信頼スコアを有する前記1つ以上の候補転写のうちの候補転写について、前記メディア再生コマンドを発行するとの前記特定のユーザの意図に対応している選択した前記文法を用いてパースを行って、前記コンピューティングデバイスが実行すべきアクションを識別することと、
を含む動作を前記データ処理ハードウェアに実行させる、方法。
続きを表示(約 640 文字)
【請求項2】
前記動作は、識別された前記アクションを実行するよう前記コンピューティングデバイスに命令することをさらに含む、
請求項1に記載の方法。
【請求項3】
前記動作は、前記コンピューティングデバイスの前記文脈に基づいて、複数の文法から前記文法を選択することをさらに含む、
請求項1に記載の方法。
【請求項4】
前記複数の文法の各々は、複数の用語からなる異なる指定された構造を含む、
請求項3に記載の方法。
【請求項5】
前記コンピューティングデバイスは、携帯電話を含む、
請求項1に記載の方法。
【請求項6】
前記コンピューティングデバイスは、ウェアラブルデバイスを含む、
請求項1に記載の方法。
【請求項7】
前記1つ以上の候補転写の各々は複数の用語を含む、
請求項1に記載の方法。
【請求項8】
前記複数の用語の各々は、対応する用語信頼スコアを含む、
請求項7に記載の方法。
【請求項9】
前記転写信頼スコアは、前記候補転写が前記ユーザによって行われた前記発話と一致する可能性を示している、
請求項1に記載の方法。
【請求項10】
前記データ処理ハードウェアは、前記コンピューティングデバイス上にある、
請求項1に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本明細書は、一般に音声認識に関する。
続きを表示(約 2,900 文字)
【背景技術】
【0002】
音声入力を使用してコンピュータとの対話を実行できるようにすることがますます求められている。これには、入力処理、特に自然言語データを処理および分析するようにコンピュータをプログラムする方法の開発が必要である。このような処理には、コンピュータによる話された言語の認識およびテキストへの変換を可能にする計算言語学の分野である音声認識が伴う場合がある。
【発明の概要】
【発明が解決しようとする課題】
【0003】
本明細書は、一般に音声認識に関する。
【課題を解決するための手段】
【0004】
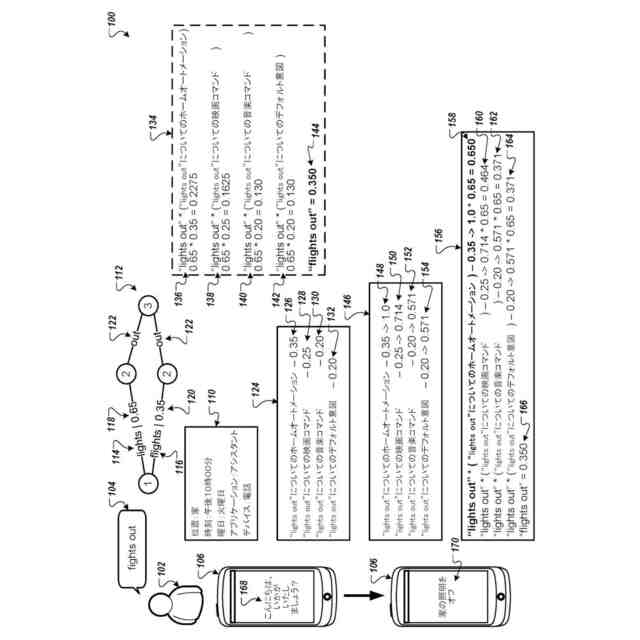
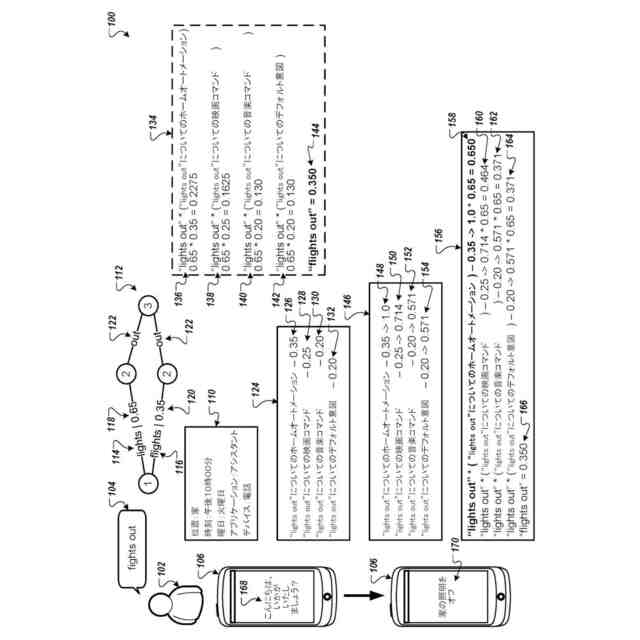
ユーザが音声を介してコンピューティングデバイスに入力を提供できるようにするため、音声入力処理システムは、文脈を使用して、自動音声認識部によって生成された複数の候補転写に適用する複数の文法を識別できる。各文法は、話者の異なる意図、あるいはシステムが同じ候補転写に対して実行するアクションを示している可能性がある。システムは、候補転写をパースする文法と、文法がユーザの意図と一致する可能性と、候補転写がユーザの発言と一致する可能性とに基づいて、文法および候補転写を選択し得る。次に、システムは、選択された候補転写に含まれる詳細を使用して、文法に対応するアクションを実行することができる。
【0005】
より詳細には、音声処理システムは、ユーザからの発話を受け取り、単語ラティスを生成する。単語ラティスは、発話における可能性の高い単語と、各単語の信頼スコアとを反映するデータ構造である。システムは、単語ラティスから、複数の候補転写と各候補転写の転写信頼スコアとを特定する。システムは、ユーザの特性、システムの位置、システムの特性、システム上で実行しているアプリケーション(例えば、現在アクティブなアプリケーションまたはフォアグラウンドで実行しているアプリケーション)、またはその他の類似の文脈データに基づいて、現在の文脈を特定する。文脈に基づいて、システムは、各候補転写をパースする複数の文法の文法信頼スコアを生成する。複数の文法が同じ候補転写に適用される可能性がある場合、システムは複数の文法信頼スコアのうちの一部を調整する場合がある。システムは、調整された複数の文法信頼スコアと複数の転写信頼スコアとの組み合わせに基づいて、文法と候補転写を選択する。
【0006】
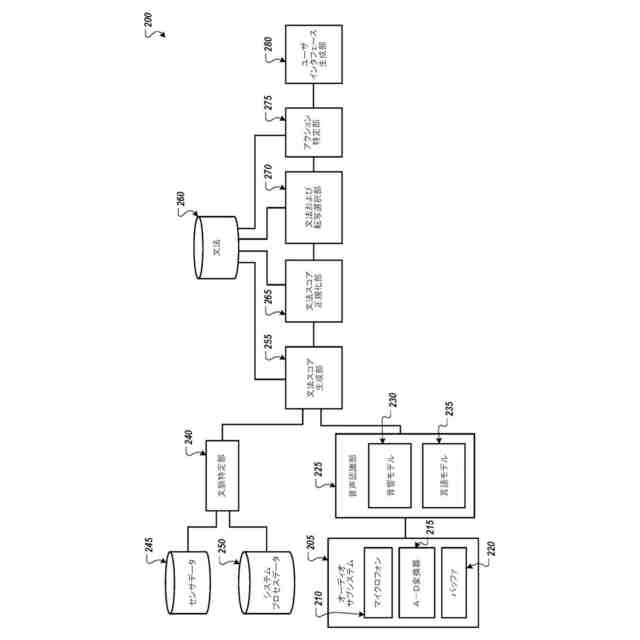
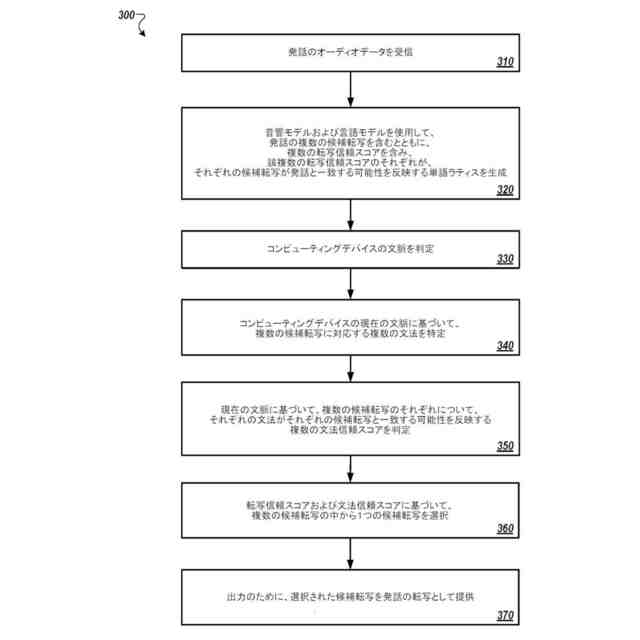
本出願に記載される主題の革新的な態様によれば、音声入力処理方法は、コンピューティングデバイスによって、発話のオーディオデータを受信することと、コンピューティングデバイスによって、音響モデルおよび言語モデルを使用して、発話の複数の候補転写を含むとともに、複数の転写信頼スコアを含み、該複数の転写信頼スコアのそれぞれが、それぞれの候補転写が発話と一致する可能性を反映する単語ラティスを生成することと、コンピューティングデバイスによって、コンピューティングデバイスの文脈を判定することと、コンピューティングデバイスの文脈に基づいて、コンピューティングデバイスによって、複数の候補転写に対応する複数の文法を特定することと、現在の文脈に基づいて、コンピューティングデバイスによって、複数の候補転写のそれぞれについて、それぞれの文法がそれぞれの候補転写と一致する可能性を反映する複数の文法信頼スコアを判定することと、複数の転写信頼スコアおよび複数の文法信頼スコアに基づいて、コンピューティングデバイスによって、複数の候補転写の中から候補転写を選択することと、コンピューティングデバイスによる出力のために、選択された候補転写を発話の転写として提供することと、に係るアクションを含む。
【0007】
これらおよびその他の実装には、それぞれ任意選択により次のフィーチャの1つ以上を含めることができる。アクションは、複数の文法のうちの2つ以上が複数の候補転写のうちの1つに対応すると判定することと、複数の文法のうちの2つ以上が複数の候補転写のうちの1つに対応すると判定することに基づいて、2つ以上の文法について複数の文法信頼スコアを調整することと、を含む。コンピューティングデバイスは、複数の候補転写の中から、転写信頼スコアおよび調整された文法信頼スコアに基づいて、候補転写を選択する。2つ以上の文法について複数の文法信頼スコアを調整するアクションは、2つ以上の文法のそれぞれについて、複数の文法信頼スコアのそれぞれを係数で増加させることを含む。アクションは、複数の候補転写のそれぞれについて、それぞれの転写信頼スコアとそれぞれの文法信頼スコアとの積を判定することを含む。コンピューティングデバイスは、複数の候補転写の中から、転写信頼スコアとそれぞれの文法信頼スコアとの積に基づいて、候補転写を選択する。コンピューティングデバイスによって、コンピューティングデバイスの文脈を判定するアクションは、コンピューティングデバイスの位置と、コンピューティングデバイスのフォアグラウンドで実行しているアプリケーションと、時刻とに基づいている。言語モデルは、単語ラティスに含まれる語のシーケンスについて、確率を特定するように構成されている。音響モデルは、オーディオデータの一部に一致する音素を特定するように構成されている。アクションは、コンピューティングデバイスによって、選択された候補転写と、選択された候補転写に一致する文法とに基づくアクションを実行することを含む。
【0008】
この態様の他の実施形態は、対応するシステム、装置、およびコンピュータ記憶装置に記録されたコンピュータプログラムを含み、それぞれが方法の動作を実行するように構成されている。
【0009】
本明細書に記載されている主題の特定の実施形態は、以下の利点のうちの1つまたは複数を実現するように実施することができる。音声認識システムは、受信した音声入力と判定された文脈の両方を使用して、受信した音声入力をさらに処理してコンピューティングデバイスにアクションを実行させるために使用される文法を選択することができる。このように、音声認識システムは、限られた数の文法を複数の候補転写に適用することにより、ヒューマンマシンインタフェースの待ち時間を短縮することができる。音声認識システムは、システムが予期しない入力を受信したときに音声認識システムが転写を出力できるように、言語のすべてまたはほぼすべての単語を含む語彙を使用することができる。
【0010】
本明細書に記載主題の1つまたは複数の実施形態の詳細は、添付の図面および以下の説明に記載されている。主題の他の特徴、態様、および利点は、説明、図面、および特許請求の範囲から明らかとなる。
【図面の簡単な説明】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
音響装置
20日前
個人
メディカルコントローラー
20日前
合名会社有賀鉄工所
小形弦楽器
14日前
合名会社有賀鉄工所
弦楽器用指板
14日前
個人
弦楽器および弦楽器用振動板
1か月前
合名会社有賀鉄工所
弦楽器用ストラップ
14日前
トヨタ自動車株式会社
音声認識装置
1か月前
東芝テック株式会社
マスキング装置
29日前
カシオ計算機株式会社
筐体及び楽器
22日前
株式会社スリック
電子オルゴール装置
22日前
トヨタ自動車株式会社
情報処理装置及び方法
1か月前
ソフトバンクグループ株式会社
電子機器
28日前
ソフトバンクグループ株式会社
電子機器
28日前
ソフトバンクグループ株式会社
電子機器
1か月前
株式会社HOWA
防音体、その製造方法及び自動車用サイレンサー
7日前
ヤマハ株式会社
シンバルの保持構造及び保持具
7日前
岐阜プラスチック工業株式会社
吸音構造体及びその製造方法
7日前
株式会社コルグ
弦楽器の調律機構、弦楽器、電気弦楽器
7日前
日本電信電話株式会社
信号強調装置、方法及びプログラム
1か月前
amptalk株式会社
プログラム、会話要約装置、および会話要約方法
28日前
ソフトバンクグループ株式会社
行動制御システム
6日前
株式会社日本知財総合研究所
音波処理装置、音波処理方法、及びデータ構造
7日前
ソフトバンクグループ株式会社
行動制御システム
29日前
ソフトバンクグループ株式会社
行動制御システム
20日前
ソフトバンクグループ株式会社
行動制御システム
20日前
ソフトバンクグループ株式会社
行動制御システム
20日前
ソフトバンクグループ株式会社
エージェントシステム
29日前
ソフトバンクグループ株式会社
エージェントシステム
29日前
ソフトバンクグループ株式会社
エージェントシステム
29日前
トヨタ紡織株式会社
制振シート
20日前
株式会社エフノート
電子演奏装置
13日前
株式会社東芝
音声入力支援プログラム及び音声入力支援装置
28日前
個人
楽譜を描画するための情報処理装置、楽譜生成方法およびプログラム
20日前
CASE特許株式会社
音声応答システム
1か月前
個人
シングルリード向け木管楽器用リガチャー
1か月前
個人
シングルリード向け木管楽器用リガチャー
1か月前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ