TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025163785
公報種別
公開特許公報(A)
公開日
2025-10-30
出願番号
2024067303
出願日
2024-04-18
発明の名称
画像処理装置
出願人
京セラドキュメントソリューションズ株式会社
代理人
個人
主分類
H04N
1/387 20060101AFI20251023BHJP(電気通信技術)
要約
【課題】 文書画像に対してユーザー所望の画像を適切に追加する画像処理装置を得る。
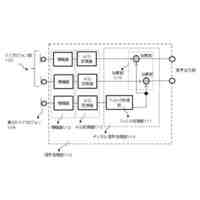
【解決手段】 テキスト情報抽出部12は、文書画像に対して文字認識処理を行って文書画像から文書画像内に記述されているテキストのテキストデータを取得する。プロンプト生成部13は、取得されたテキストデータに基づいて、所定の画像生成モデルのためのプロンプトを生成する。生成画像取得部14は、生成されたプロンプトに対応する生成画像を取得する。文書画像編集部15は、取得された生成画像を文書画像内に追加する。
【選択図】 図1
特許請求の範囲
【請求項1】
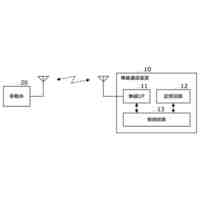
文書画像を取得する文書画像取得部と、
前記文書画像に対して文字認識処理を行って前記文書画像から前記文書画像内に記述されているテキストのテキストデータを取得するテキスト情報抽出部と、
取得された前記テキストデータに基づいて、所定の画像生成モデルのためのプロンプトを生成するプロンプト生成部と、
生成された前記プロンプトに対応する生成画像を取得する生成画像取得部と、
取得された前記生成画像を前記文書画像内に追加する文書画像編集部と、
を備えることを特徴とする画像処理装置。
続きを表示(約 1,000 文字)
【請求項2】
前記テキスト情報抽出部は、(a)前記文書画像から、前記テキストデータとともに、前記テキストが記述されている位置を特定し、(b)前記位置に基づいて、前記テキストデータを行ごとに分類し、
前記プロンプト生成部は、取得された前記テキストデータのうち、前記生成画像を追加すべき画像追加領域から所定距離の範囲内にある行のテキストデータに基づいて、所定の画像生成モデルのためのプロンプトを生成すること、
を特徴とする請求項1記載の画像処理装置。
【請求項3】
前記テキスト情報抽出部は、(a)前記文書画像から、前記テキストデータとともに、前記テキストが記述されている位置を特定し、さらに、前記文書画像における前記テキストの特徴を特定し、(b)前記位置に基づいて、前記テキストデータを行ごとに分類し、
前記プロンプト生成部は、取得された前記テキストデータのうち、前記テキストの特徴に基づいてテキストデータを選択し、選択した前記テキストデータに基づいて、所定の画像生成モデルのためのプロンプトを生成すること、
を特徴とする請求項1記載の画像処理装置。
【請求項4】
前記テキストの特徴は、前記テキストのサイズであり、
前記プロンプト生成部は、取得された前記テキストデータのうち、前記テキストのサイズが最も大きい行のテキストデータを選択し、選択した前記テキストデータに基づいて、所定の画像生成モデルのためのプロンプトを生成すること、
を特徴とする請求項3記載の画像処理装置。
【請求項5】
前記テキストの特徴は、前記テキストの文字種、書体、色、太さ、傾き、文字間スペースの幅、および行間スペースの幅のうちの少なくとも1つを含むことを特徴とする請求項3記載の画像処理装置。
【請求項6】
前記プロンプト生成部は、ユーザー所望の文字列を前記プロンプトに含めることを特徴とする請求項1から請求項5のうちのいずれか1項記載の画像処理装置。
【請求項7】
前記生成画像取得部は、生成された前記プロンプトに対応する複数の生成画像を取得し、
前記文書画像編集部は、取得された前記複数の生成画像からユーザーにより指定された生成画像を選択し、選択した前記生成画像を前記文書画像内に追加すること、
を特徴とする請求項1記載の画像処理装置。
発明の詳細な説明
【技術分野】
【0001】
本発明は、画像処理装置に関するものである。
続きを表示(約 1,300 文字)
【背景技術】
【0002】
Stable Diffusionなどといった画像生成AIサービスでは、入力されたテキスト(プロンプト)に対応する画像が生成される。
【0003】
ある情報処理方法は、画像生成AIを使用して、広告情報(企業名、商品名、など)に基づいて広告画像を生成している(例えば特許文献1参照)。
【先行技術文献】
【特許文献】
【0004】
特開2024-43680号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
上述のような画像生成AIサービスや画像生成AIでは、ユーザーが所望する画像を得るためには、適切なテキスト(プロンプト)を入力する必要がある。ユーザーが、ある文書画像に対して自動生成された画像を追加したい場合において、ユーザーの熟練度によっては、適切なテキスト(プロンプト)が選択されずに、適切な画像が追加されない可能性がある。
【0006】
本発明は、上記の問題に鑑みてなされたものであり、文書画像に対してユーザー所望の画像を適切に追加する画像処理装置を得ることを目的とする。
【課題を解決するための手段】
【0007】
本発明に係る画像処理装置は、文書画像を取得する文書画像取得部と、前記文書画像に対して文字認識処理を行って前記文書画像から前記文書画像内に記述されているテキストのテキストデータを取得するテキスト情報抽出部と、取得された前記テキストデータに基づいて、所定の画像生成モデルのためのプロンプトを生成するプロンプト生成部と、生成された前記プロンプトに対応する生成画像を取得する生成画像取得部と、取得された前記生成画像を前記文書画像内に追加する文書画像編集部とを備える。
【発明の効果】
【0008】
本発明によれば、文書画像に対してユーザー所望の画像を適切に追加する画像処理装置が得られる。
【0009】
本発明の上記又は他の目的、特徴および優位性は、添付の図面とともに以下の詳細な説明から更に明らかになる。
【図面の簡単な説明】
【0010】
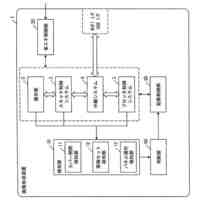
図1は、本発明の実施の形態に係る画像処理装置の構成を示すブロック図である。
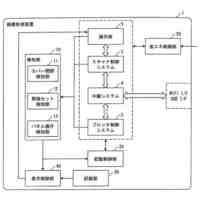
図2は、文書画像の一例を示す図である。
図3は、図2に示す文書画像から抽出されるテキストについて説明する図である。
図4は、図3に示す行のテキストデータのうち、プロンプトの生成に使用されるテキストデータの一例を示す図である。
図5は、ユーザーにより指定された文字列「ハンバーガー」をプロンプトとして生成された生成画像の一例を示す図である。
図6は、ユーザーにより指定された文字列「ハンバーガー」並びに文書画像から抽出されたテキストデータから選択された文字列「Lunch」、「メニュー」、「一品」、および「plus」をプロンプトとして生成された生成画像の例を示す図である。
図7は、生成画像が追加された文書画像の一例を示す図である。
【発明を実施するための形態】
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
イヤーピース
2日前
個人
イヤーマフ
16日前
個人
監視カメラシステム
25日前
個人
スイッチシステム
10日前
キーコム株式会社
光伝送線路
26日前
個人
スキャン式車載用撮像装置
25日前
サクサ株式会社
中継装置
1か月前
WHISMR合同会社
収音装置
1か月前
サクサ株式会社
中継装置
1か月前
キヤノン株式会社
撮像装置
2か月前
アイホン株式会社
電気機器
1か月前
サクサ株式会社
無線通信装置
1か月前
キヤノン電子株式会社
画像読取装置
2か月前
キヤノン電子株式会社
画像読取装置
10日前
個人
ワイヤレスイヤホン対応耳掛け
1か月前
キヤノン電子株式会社
画像読取装置
2日前
株式会社リコー
画像形成装置
18日前
株式会社リコー
画像形成装置
2か月前
サクサ株式会社
無線システム
1か月前
株式会社リコー
画像形成装置
2か月前
個人
映像表示装置、及びARグラス
11日前
サクサ株式会社
無線通信装置
1か月前
ヤマハ株式会社
放音制御装置
10日前
キヤノン電子株式会社
画像読取装置
24日前
キヤノン電子株式会社
シート搬送装置
2日前
キヤノン株式会社
撮像システム
1か月前
個人
発信機及び発信方法
1か月前
キヤノン株式会社
画像処理装置
5日前
日本電気株式会社
海底分岐装置
26日前
シャープ株式会社
表示装置
2日前
株式会社NTTドコモ
端末
25日前
株式会社松平商会
携帯機器カバー
2か月前
シャープ株式会社
表示装置
2日前
シャープ株式会社
端末装置
23日前
国立大学法人電気通信大学
小型光学装置
2か月前
株式会社NTTドコモ
端末
26日前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ