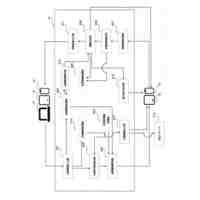
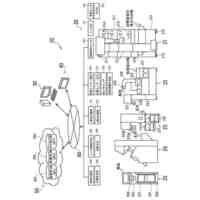
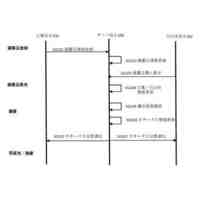
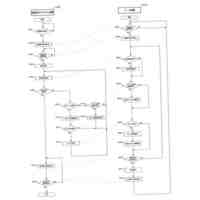
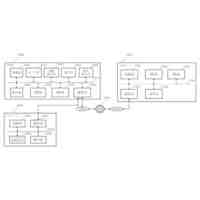
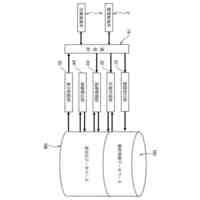
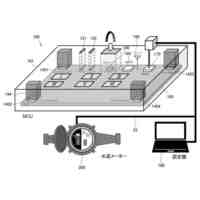
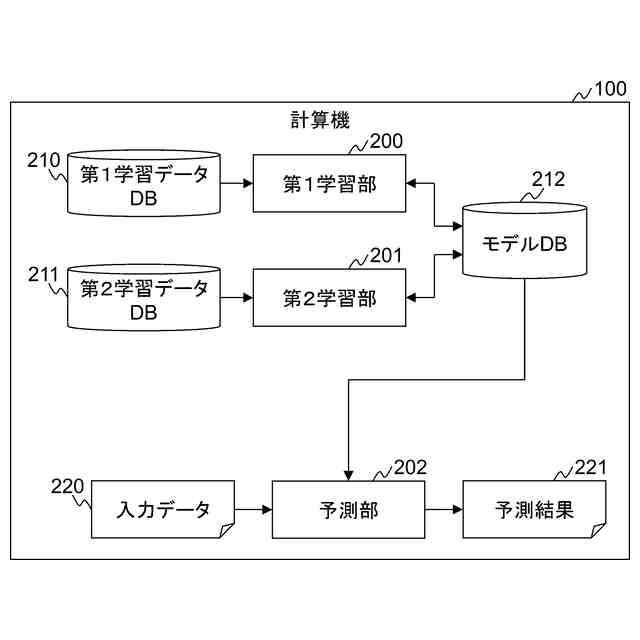
公開番号2025103441 公報種別公開特許公報(A) 公開日2025-07-09 出願番号2023220838 出願日2023-12-27 発明の名称計算機システム、モデルの学習方法、及び情報処理方法 出願人株式会社日立製作所 代理人藤央弁理士法人 主分類G06N 3/096 20230101AFI20250702BHJP(計算;計数) 要約【課題】大規模データベースを用いて生成された予測モデルを活用して、情報量が少ないデータを扱う予測モデルを生成する転移学習を実現する。 【解決手段】計算機システムは、第1学習データセットを用いた機械学習によって、ベースとなる第1モデルを生成し、第1モデル及び第2学習データセットを用いた転移学習によって第2モデルを生成する。転移学習では、第2学習データセットを構成する学習データに含まれる第2モデルの予測対象に対応する項目の分布特性に応じて当該学習データの学習への影響を調整する第2損失関数を含む第3損失関数と、第1モデル及び第2モデルの出力の差分を評価する第4損失関数を含む第5損失関数と、の少なくともいずれかを用いて第2モデルが生成される。 【選択図】図2 特許請求の範囲【請求項1】 プロセッサ、前記プロセッサに接続される記憶装置、及び前記プロセッサに接続される接続インタフェースを有する計算機を備える計算機システムであって、 前記記憶装置に格納される第1学習データセットを用いた機械学習によって、ベースとなる第1モデルを生成し、 前記第1モデル及び前記記憶装置に格納される第2学習データセットを用いた転移学習によって第2モデルを生成し、 前記転移学習では、前記第2学習データセットを構成する学習データに含まれる前記第2モデルの予測対象に対応する項目の分布特性に応じて当該学習データの学習への影響を調整する第2損失関数を含む第3損失関数と、前記第1モデル及び前記第2モデルの出力の差分を評価する第4損失関数を含む第5損失関数と、の少なくともいずれかを用いて前記第2モデルが生成されることを特徴とする計算機システム。 続きを表示(約 2,000 文字)【請求項2】 請求項1に記載の計算機システムであって、 前記第2損失関数は、前記第2学習データセットを構成する学習データに含まれる前記第2モデルの予測対象に対応する項目の値が所定の範囲に含まれない前記学習データによる前記第2モデルの更新を抑えるための関数であることを特徴とする計算機システム。 【請求項3】 請求項1に記載の計算機システムであって、 前記第1モデル及び前記第2モデルは、入力層、複数の中間層、及び出力層を含むネットワークであって、 前記第4損失関数は、前記第1モデル及び前記第2モデルの前記入力層及び前記複数の中間層の少なくとも一つの層の出力の差分を評価する損失関数と、前記第1モデル及び前記第2モデルの前記出力層の出力の差分を評価する損失関数と、含むことを特徴とする計算機システム。 【請求項4】 請求項1に記載の計算機システムであって、 前記第3損失関数及び前記第5損失関数は係数を含み、 前記計算機システムは、前記転移学習の進捗状況に応じて、前記第3損失関数又は前記第5損失関数に含まれる前記係数を変更しながら前記転移学習を実行することを特徴とする計算機システム。 【請求項5】 請求項1に記載の計算機システムであって、 前記第2モデルは、患者の疾患又は病態に関する予測を行うモデルであることを特徴とする計算機システム。 【請求項6】 請求項1に記載の計算機システムであって、 前記第1学習データセットに含まれる学習のデータは、細胞株の遺伝子情報と、薬剤応答を含み、 前記第1モデルは、前記細胞株の遺伝子情報から前記薬剤応答を出力し、 前記第2学習データセットに含まれる学習データは、患者の薬剤応答を示す臨床データであり、 前記第2モデルは、患者の遺伝子変異情報を入力として受け付け、前記患者における薬剤応答に関する予測を行うモデルであることを特徴とする計算機システム。 【請求項7】 計算機システムが実行するモデルの学習方法であって、 前記計算機システムは、プロセッサ、前記プロセッサに接続される記憶装置、及び前記プロセッサに接続される接続インタフェースを有する計算機を有し、 前記モデルの学習方法は、 前記プロセッサが、前記記憶装置に格納される第1学習データセットを用いた機械学習を実行することによって第1モデルを生成し、前記第1モデルを前記記憶装置に格納する第1のステップと、 前記プロセッサが、前記記憶装置に格納される前記第1モデル及び第2学習データセットを用いた転移学習を実行することによって第2モデルを生成し、前記第2モデルを前記記憶装置に格納する第2のステップと、を含み 前記第2のステップは、前記プロセッサが、前記第2学習データセットを構成する学習データに含まれる前記第2モデルの予測対象に対応する項目の分布特性に応じて当該学習データの学習への影響を調整する第2損失関数を含む第3損失関数と、前記第1モデル及び前記第2モデルの出力の差分を評価する第4損失関数を含む第5損失関数と、の少なくともいずれかを用いて前記第2モデルを生成するステップを含むことを特徴とするモデルの学習方法。 【請求項8】 請求項7に記載のモデルの学習方法であって、 前記第2損失関数は、前記第2学習データセットを構成する学習データに含まれる、前記第2モデルの予測対象に対応する項目の値が所定の範囲に含まれない前記学習データによる前記第2モデルの更新を抑えるための関数であることを特徴とするモデルの学習方法。 【請求項9】 請求項7に記載のモデルの学習方法であって、 前記第1モデル及び前記第2モデルは、入力層、複数の中間層、及び出力層を含むネットワークであって、 前記第4損失関数は、前記第1モデル及び前記第2モデルの前記入力層及び前記複数の中間層の少なくとも一つの層の出力の差分を評価する損失関数と、前記第1モデル及び前記第2モデルの前記出力層の出力の差分を評価する損失関数と、含むことを特徴とするモデルの学習方法。 【請求項10】 請求項7に記載のモデルの学習方法であって、 前記第3損失関数及び前記第5損失関数は係数を含み、 前記第2のステップは、前記プロセッサが、前記転移学習の進捗状況に応じて、前記第3損失関数又は前記第5損失関数に含まれる前記係数を変更しながら前記転移学習を実行するステップを含むことを特徴とするモデルの学習方法。 (【請求項11】以降は省略されています) 発明の詳細な説明【技術分野】 【0001】 本発明は、大規模公開データベースを用いて生成された予測モデルを活用して、情報量が少ないデータ(例えば実臨床データ)を扱う予測モデルの精度を高める転移学習に関する。 続きを表示(約 2,600 文字)【背景技術】 【0002】 次世代シーケンシング(NGS:Next Generation Sequencing)に代表される遺伝子測定技術の進展により、ハイスループットスクリーニングが可能となり、近年、遺伝子配列データなどの大規模レジストリが急速に蓄積されている。例えば、TCGA(The Cancer Genome Atlas、NCI:National Cancer Institute)などの医療機関主催によるマスタークリニカルトライアル含む多くの治験データ、公開細胞株データ(CCLE:Cancer Cell Line Encyclopedia、GDSC:Genomics of Drug Sensitivity in Cancerなど)、患者腫瘍移植モデル(PDX:patient-derived xenografts)データなどである。 【0003】 これらのいわゆる医用ビッグデータを用いた分析研究も非常に盛んであり、例えば、公開細胞株データを用いた薬物感受性予測モデルの研究もその一つである。しかし、現在の予測モデルの精度、加えてそこから得られた結果の解釈方法は、十分な臨床予測力を有していない。これは、一般的に使用されている細胞株や異種移植片が、ヒトの反応を効果的に模倣/予測できないモデルであることが原因であるとされている(非特許文献1を参照)。 【0004】 一方で、細胞株データは、数として約1000、薬剤は約300、薬効実験数は24万ほどの膨大な実症例データであり(非特許文献2を参照)、有益な活用方法が望まれている。 【0005】 公開細胞株データでの検証精度の課題に対して、PDXの活用による薬物応答プロファイリングが進んでいるが、PDXの作成にはコストと時間がかかるという問題がある。 【0006】 非特許文献2では、公開細胞株データで学習した予測モデルをin-vivo腫瘍及びex-vivo患者由来異種移植片(PDX)データへ転移学習し、転帰を予測するモデルを構築している。薬剤ごとの予測とがんごとの予測において、転移学習を使用しない場合(平均)と比較して、それぞれ49.8%、47.8%AUROCを改善した、と報告されている。 【先行技術文献】 【非特許文献】 【0007】 Jennifer L Wilding, Walter F Bodmer, “Cancer cell lines for drug discovery and development”, Cancer Res. 2014 May 1;74(9):2377-84. doi: 10.1158/0008-5472.CAN-13-2971. Yi-Ching Tang, Reid T. Powell & Assaf Gottlieb, 「Molecular pathways enhance drug response prediction using transfer learning from cell lines to tumors and patient-derived xenografts」, Scientifc Reports(2022) 12:16109. Zhuang, F., Qi, Z., Duan, K., Xi, D., Zhu, Y., Zhu, H., Xiong, H., and He, Q. (2020) A Comprehensive Survey on Transfer Learning. Proceedings of the IEEE 109 (1), 43-76. Motiian, S., Piccirilli, M., Adjeroh, D. A., and Doretto, G.: Unified deep supervised domain adaptation and generalization, in Proceedings of the IEEE International Conference on Computer Vision, pp. 5715-5725 (2017) G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. Ji-Hoon Bae Junho Yim, Donggyu Joo and Junmo Kim. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. CVPR, 2017. Maaten, L. V. D. and Hinton, G. “Visualizing Data using t-SNE.” Journal of Machine Learning Research (2008), pp. 1-48. 【発明の概要】 【発明が解決しようとする課題】 【0008】 例えば、実臨床における医療データは、一般的に、入力するパラメータ(説明変数、特徴量)(P)に対して、サンプル数(N)が極端に低いため(P>>N)、機械学習を用いた予測モデルは十分な予測精度を達成できないか、過学習を起こす可能性が高い。そこで、例えば、公開細胞株データに代表される大規模データベースを活用した高精度な予測モデルの臨床適用が望まれている。 【0009】 非特許文献2で用いられている転移学習の手法としては、最終層のfine-tuningする一般的な転移学習手法を利用している。また、公開細胞株データは、対象疾患によって区別をせず、全ての細胞株データを教師データとして用いた予測モデルを生成している。 【0010】 本発明は、転移学習により予測が高い予測モデルを生成するシステム及び方法を実現することを目的とする。 【課題を解決するための手段】 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する

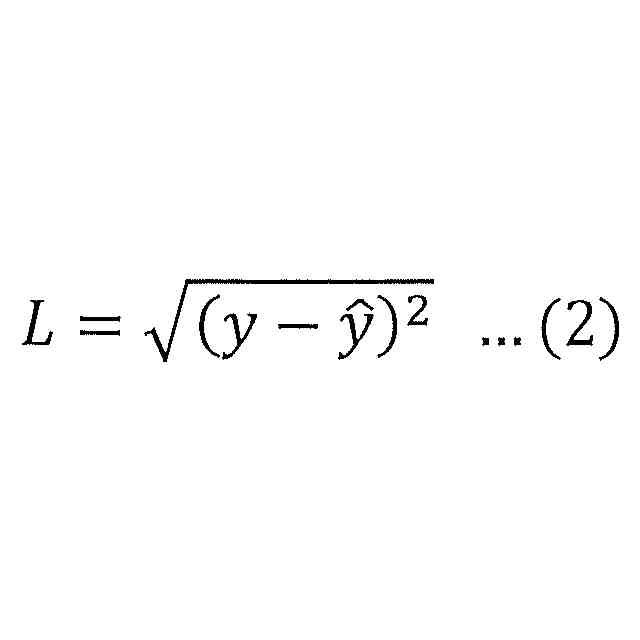




 特許ウォッチ
特許ウォッチ