TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025176532
公報種別
公開特許公報(A)
公開日
2025-12-04
出願番号
2024082750
出願日
2024-05-21
発明の名称
学習プログラム、学習方法、および情報処理装置
出願人
富士通株式会社
代理人
弁理士法人片山特許事務所
主分類
G06N
20/00 20190101AFI20251127BHJP(計算;計数)
要約
【課題】 高い精度で生成モデルを生成することができる学習プログラム、学習方法、および情報処理装置を提供する。
【解決手段】 学習プログラムは、サンプルデータに対して推定される確率分布に基づいて自己サンプルデータを生成可能な機械学習モデルの学習において、コンピュータに、学習途中の前記機械学習モデルから生成される前記自己サンプルデータを生成する処理と、前記サンプルデータに基づく教師無し学習の第1損失関数と、前記サンプルデータおよび前記自己サンプルデータに基づく教師有り学習の第2損失関数と、を含む第3損失関数が小さくなるように、前記機械学習モデルの学習を行う処理と、を実行させる。
【選択図】 図1
特許請求の範囲
【請求項1】
サンプルデータに対して推定される確率分布に基づいて自己サンプルデータを生成可能な機械学習モデルの学習において、
コンピュータに、
学習途中の前記機械学習モデルから生成される前記自己サンプルデータを生成する処理と、
前記サンプルデータに基づく教師無し学習の第1損失関数と、前記サンプルデータおよび前記自己サンプルデータに基づく教師有り学習の第2損失関数と、を含む第3損失関数が小さくなるように、前記機械学習モデルの学習を行う処理と、
を実行させることを特徴とする学習プログラム。
続きを表示(約 610 文字)
【請求項2】
前記第2損失関数では、前記自己サンプルデータから計算されたエネルギー関数がペナルティとして組み込まれていることを特徴とする請求項1に記載の学習プログラム。
【請求項3】
サンプルデータに対して推定される確率分布に基づいて自己サンプルデータを生成可能な機械学習モデルの学習において、
コンピュータが、
学習途中の前記機械学習モデルから生成される前記自己サンプルデータを生成する処理と、
前記サンプルデータに基づく教師無し学習の第1損失関数と、前記サンプルデータおよび前記自己サンプルデータに基づく教師有り学習の第2損失関数と、を含む第3損失関数が小さくなるように、前記機械学習モデルの学習を行う処理と、
を実行することを特徴とする学習方法。
【請求項4】
サンプルデータに対して推定される確率分布に基づいて自己サンプルデータを生成可能な機械学習モデルの学習において、学習途中の前記機械学習モデルから生成される前記自己サンプルデータを生成する自己サンプル生成部と、
前記サンプルデータに基づく教師無し学習の第1損失関数と、前記サンプルデータおよび前記自己サンプルデータに基づく教師有り学習の第2損失関数と、を含む第3損失関数が小さくなるように、前記機械学習モデルの学習を行う学習部と、
を備えることを特徴とする情報処理装置。
発明の詳細な説明
【技術分野】
【0001】
本件は、学習プログラム、学習方法、および情報処理装置に関する。
続きを表示(約 1,600 文字)
【背景技術】
【0002】
確率分布を機械学習することによって生成モデルを生成する技術が開示されている(例えば、非特許文献1,2を参照)。
【先行技術文献】
【非特許文献】
【0003】
Huang, L. and Wang “Accelerated monte carlo simulations with restricted boltzman machines” Physical Review B, 95(3):035105
Midgley, L. I., Stimper, V., Simm, G. N., Sch¨ olkopf, B., and Hern´andez-Lobato, J. M. (2022). Flow annealed importance sampling bootstrap. arXiv preprint arXiv:2208.01893.
【発明の概要】
【発明が解決しようとする課題】
【0004】
サンプルデータが用意されているデータ有り学習でも、サンプルデータが用意されていないデータ無し学習でも、高い精度で生成モデルを生成するのは困難である。
【0005】
1つの側面では、本発明は、高い精度で生成モデルを生成することができる学習プログラム、学習方法、および情報処理装置を提供することを目的とする。
【課題を解決するための手段】
【0006】
1つの態様では、学習プログラムは、サンプルデータに対して推定される確率分布に基づいて自己サンプルデータを生成可能な機械学習モデルの学習において、コンピュータに、学習途中の前記機械学習モデルから生成される前記自己サンプルデータを生成する処理と、前記サンプルデータに基づく教師無し学習の第1損失関数と、前記サンプルデータおよび前記自己サンプルデータに基づく教師有り学習の第2損失関数と、を含む第3損失関数が小さくなるように、前記機械学習モデルの学習を行う処理と、を実行させる。
【発明の効果】
【0007】
高い精度で生成モデルを生成することができる。
【図面の簡単な説明】
【0008】
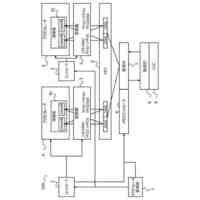
(a)は情報処理装置の全体構成を表す機能ブロック図であり、(b)は情報処理装置のハードウェア構成図である。
情報処理装置の動作の一例を表すフローチャートである。
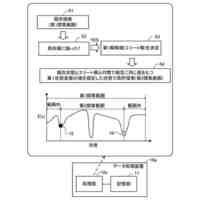
(a)および(b)は学習結果を示す図である。
【発明を実施するための形態】
【0009】
統計学の分野では、確率分布の規格化定数(分配関数)以外の関数形が与えられる状況下で、当該確率分布からサンプリングを行う技術が提案されてきている。例えば、タンパク質の分野において、確率分布からサンプリングを行う技術が提案されてきている。具体的には、下記式(1)において、p(x)が確率分布である。下記式(1)において、Zが規格化定数である。下記式(1)では、Zの値の評価が困難であり、エネルギー関数H(x)は現実的な計算時間で利用可能である。
TIFF
2025176532000002.tif
18
170
【0010】
機械学習の分野では、未知の複雑な確率分布を機械学習モデルq(x)によりモデリングする技術(生成モデル)が発展している。特に、下記式(2)のように、パラメータθで特徴付けられる生成モデルq
θ
(x)が主流として発展している。
TIFF
2025176532000003.tif
15
170
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
富士通株式会社
半導体装置
1か月前
富士通株式会社
行列演算回路
2か月前
富士通株式会社
周波数変換器
2か月前
富士通株式会社
半導体デバイス
1か月前
富士通株式会社
メッシュ微細化
1か月前
富士通株式会社
画像処理モデル
1か月前
富士通株式会社
ダウンサンプリング
8日前
富士通株式会社
演算器及び演算方法
1か月前
富士通株式会社
冷却装置及び電子機器
2か月前
富士通株式会社
ポイントクラウド分類
1か月前
富士通株式会社
ハイブリッド光増幅器
3か月前
富士通株式会社
量子デバイスの製造方法
3か月前
富士通株式会社
光受信装置及び光受信方法
8日前
富士通株式会社
アレイアンテナモジュール
1か月前
富士通株式会社
電子機器筐体及び電子機器
1か月前
富士通株式会社
OLT及びPONシステム
28日前
富士通株式会社
光送信器及び光トランシーバ
1か月前
富士通株式会社
プログラム及びデータ処理装置
22日前
富士通株式会社
情報処理装置及び情報処理方法
14日前
富士通株式会社
演算処理装置及び演算処理方法
2か月前
富士通株式会社
基板及びこれを備えた電子装置
1か月前
富士通株式会社
通信制御装置及び移動中継装置
2か月前
富士通株式会社
演算処理装置及び情報処理装置
1か月前
富士通株式会社
テキスト案内される画像エディタ
1か月前
富士通株式会社
情報処理装置および情報処理方法
8日前
富士通株式会社
波長変換装置および波長変換方法
1か月前
富士通株式会社
ラックマウント装置及びラック装置
1か月前
富士通株式会社
書き込みアシスト回路及びSRAM
6日前
富士通株式会社
動的多次元メディアコンテンツ投影
2か月前
富士通株式会社
メモリ管理装置及びメモリ管理方法
1か月前
富士通株式会社
ポイントクラウドレジストレーション
3か月前
富士通株式会社
不正検知プログラム、方法、及び装置
14日前
富士通株式会社
視線誘導方法および視線誘導プログラム
3か月前
富士通株式会社
異常予測方法および異常予測プログラム
2か月前
富士通株式会社
データ処理方法及び装置、並びに記憶媒体
1日前
富士通株式会社
推定システム、情報処理装置及び推定方法
1日前
続きを見る
他の特許を見る


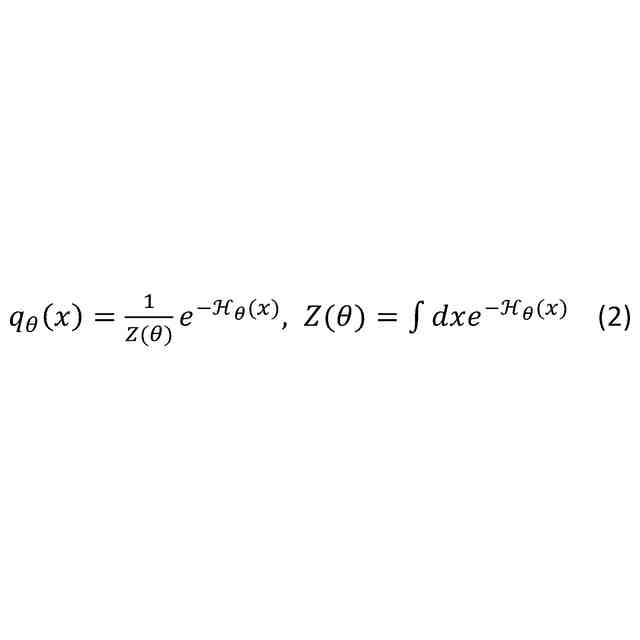
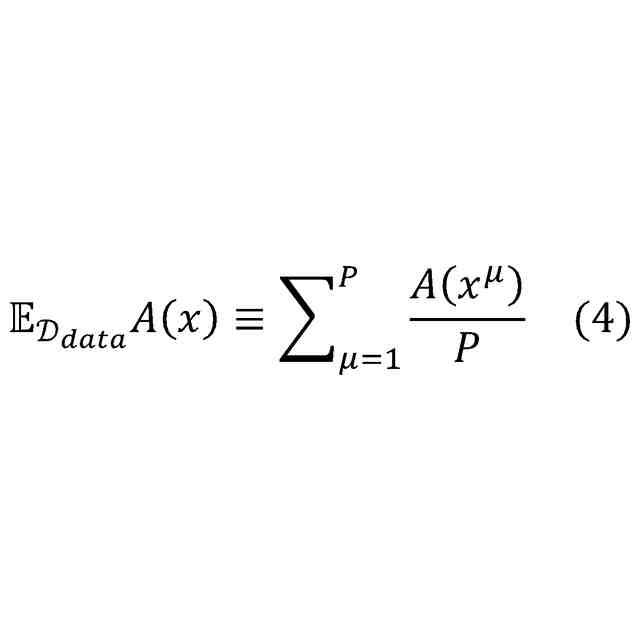
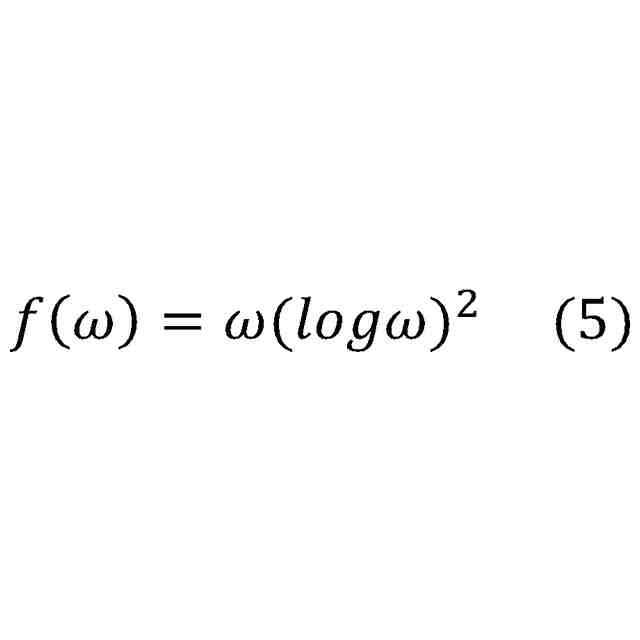
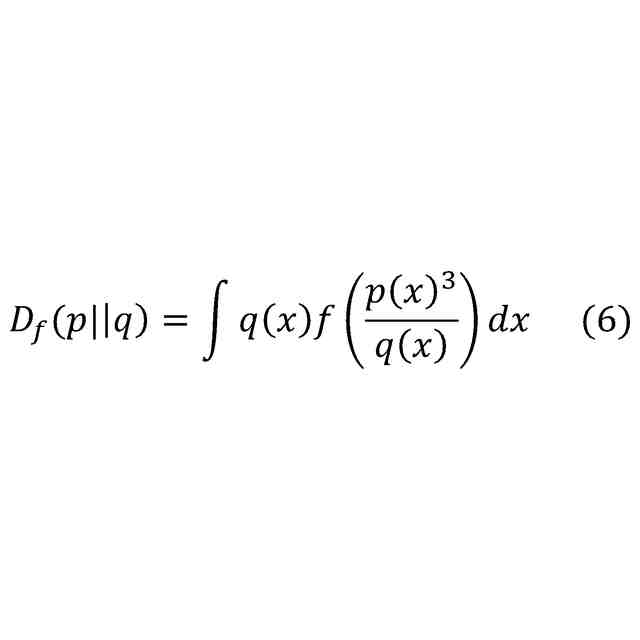
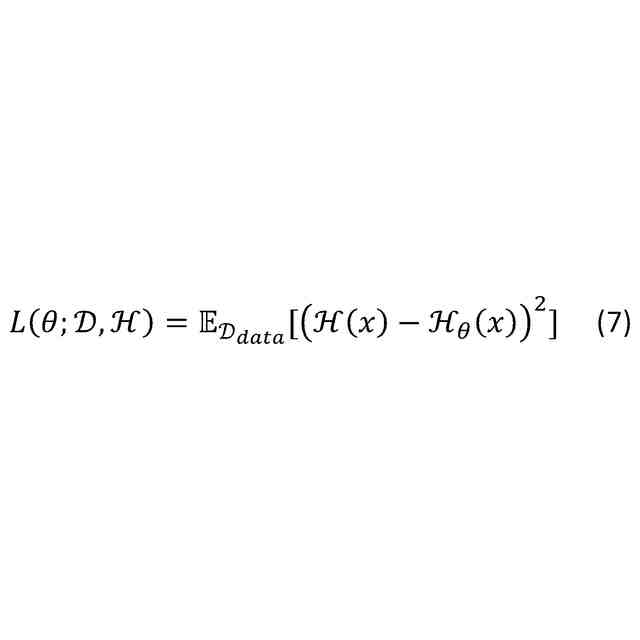
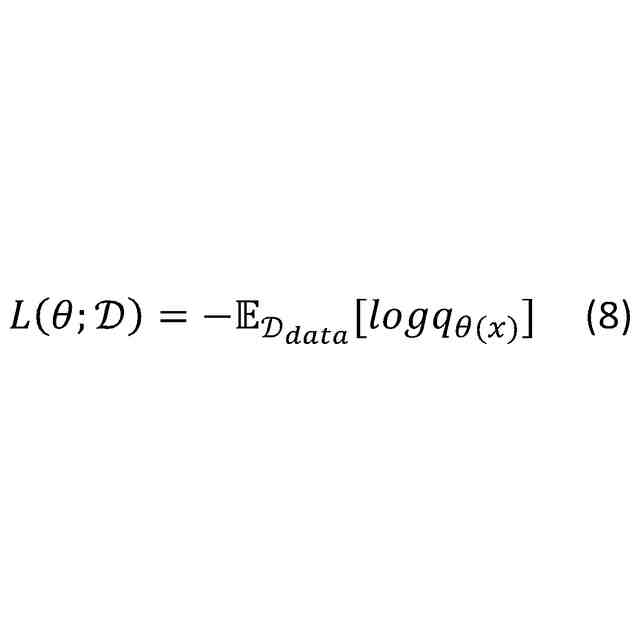
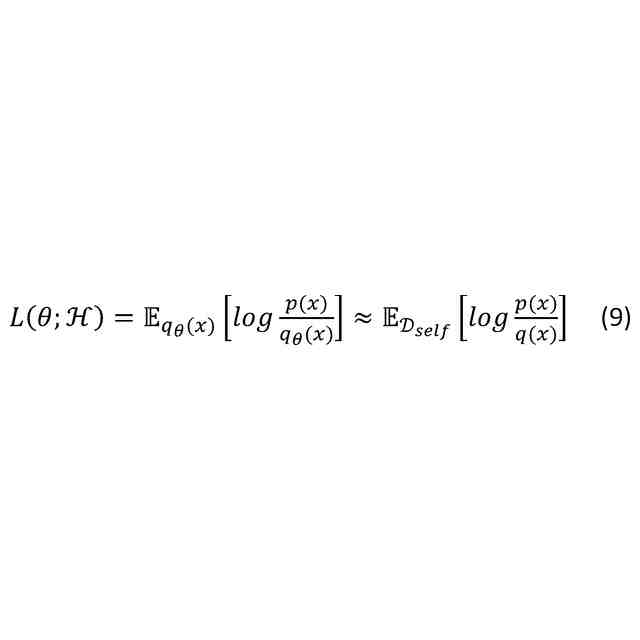
 特許ウォッチ
特許ウォッチ