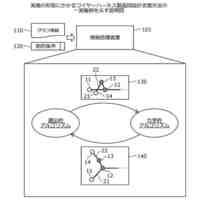
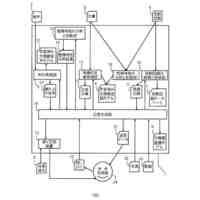
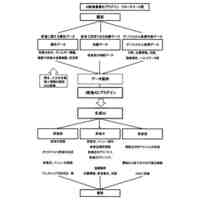
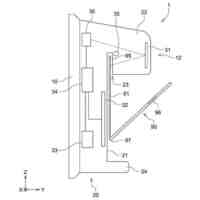
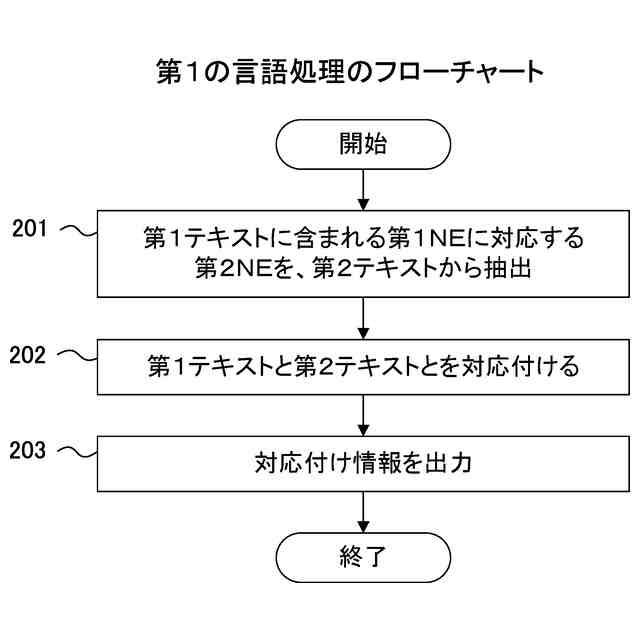
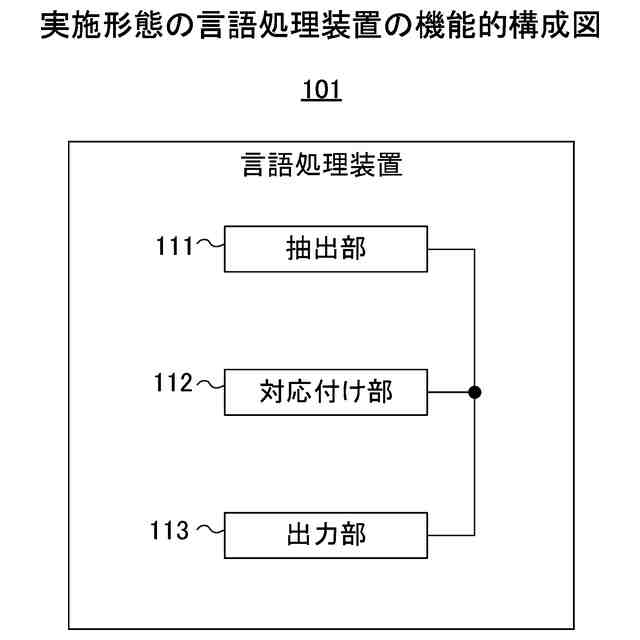
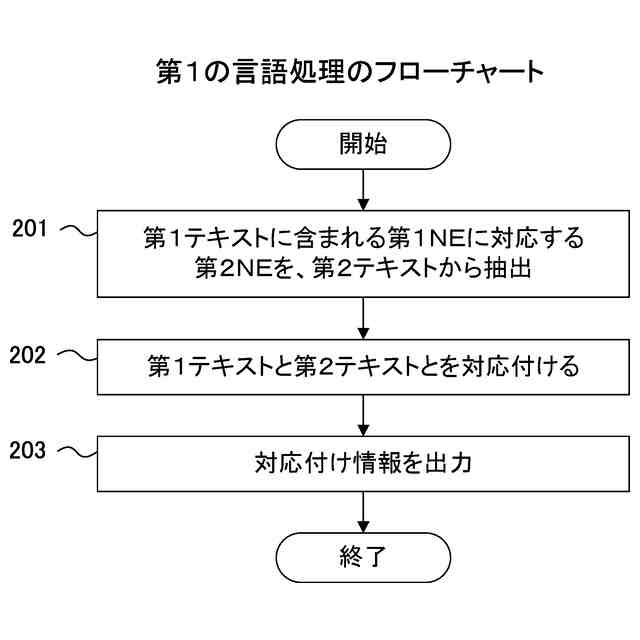
発明の詳細な説明【技術分野】 【0001】 本発明は、言語処理技術に関する。 続きを表示(約 1,800 文字)【背景技術】 【0002】 対訳コーパスは、翻訳関係にある異なる言語の文と文が対訳の形式で対応付けられたコーパスである。一方、コンパラブルコーパスは、同じトピックに関する異なる言語の文書と文書が対応付けられたコーパスである。 【0003】 コンパラブルコーパスの文書対は、対訳コーパスのようにきっちりとした翻訳関係を有していない。多言語で記述されるWikipedia(登録商標)の記事は、コンパラブルコーパスの一例である。 【0004】 対訳コーパスは、機械翻訳で利用される重要なデータである。しかし、対訳コーパスを構築するためには、人間による翻訳及びチェックが行われることが多く、構築のための作業負荷が大きい。このため、対訳コーパスは、なかなか入手しにくい希少なリソースである。また、科学技術分野のような専門領域の対訳コーパスを構築するためには、専門知識が要求されるため、専門領域の対訳コーパスはさらに希少となる。 【0005】 また、現存する対訳コーパスのリソースについては、言語間の格差が大きい。英語、フランス語等の主要なヨーロッパ言語の対訳コーパスは比較的多いが、低リソース言語の対訳コーパスは少ないか又は存在しない。低リソース言語は、バスク語、日本語、アラビア語、タミール語、タイ語、インドネシア語等のデータの少ない言語である。 【0006】 対訳コーパスに関して、低リソース言語の機械翻訳にコンパラブルコーパスを利用する技術が知られている(例えば、非特許文献1及び非特許文献2を参照)。双方向再帰型ニューラルネットワークを用いて対訳文を抽出する技術も知られている(例えば、非特許文献3を参照)。文書単位で対応付いた非対訳コーパスの各文書又は各単語に対して、言語を横断したトピックを割り当てるトピック推定装置も知られている(例えば、特許文献1を参照)。 【先行技術文献】 【特許文献】 【0007】 特開2017-151678号公報 【非特許文献】 【0008】 A. Irvine et al., “Combining Bilingual and Comparable Corpora for Low Resource Machine Translation”, Proceedings of the Eighth Workshop on Statistical Machine Translation, pages 262-270, 2013. S. H. Ramesh et al., “Neural Machine Translation for Low Resource Languages using Bilingual Lexicon Induced from Comparable Corpora”, Proceedings of NAACL-HLT 2018: Student Research Workshop, pages 112-119, 2018. F. Gregoire et al., “Extracting Parallel Sentences with Bidirectional Recurrent Neural Networks to Improve Machine Translation”, Proceedings of the 27th International Conference on Computational Linguistics, pages 1442-1453, 2018. 【発明の概要】 【発明が解決しようとする課題】 【0009】 コンパラブルコーパスから対訳コーパスを生成するために、文と文の意味的類似度に基づいて、翻訳関係にある文対を抽出する場合、抽出された文対が必ずしも同じ意味内容を表しているとは限らない。 【0010】 なお、かかる問題は、コンパラブルコーパスから対訳コーパスを生成する場合に限らず、異なる言語で記述された様々なテキストを比較する場合において生ずるものである。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する
 特許ウォッチ
特許ウォッチ