TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025161485
公報種別
公開特許公報(A)
公開日
2025-10-24
出願番号
2024064702
出願日
2024-04-12
発明の名称
大規模言語モデルに機械学習させる方法及びその利用のためのプログラム
出願人
株式会社GFLOPS
代理人
個人
主分類
G06F
16/31 20190101AFI20251017BHJP(計算;計数)
要約
【課題】膨大なテキストファイルを高速かつ高い回答精度で検索を行う文書ファイル検索する方法及びプログラムを提供する。
【解決手段】大規模言語モデルデータベースへのデータ保存方法は、文書ファイル中のテキストを、チャンクとして断片化する。それぞれのチャンクは、連続するテキストにおける1つ前のチャンクの末尾部分を一定数以上含み、それぞれのチャンクはベクトル化された数値と関連付けられており、それぞれのチャンクが、ファイル名、カテゴリ、製品名、及びテキストを含むデータを付与した単位データとして保存する。質問方法は、ユーザー入力するテキストをベクトル化したデータを、大規模言語モデルにおいて回答情報源から抽出されたテキストをベクトル化したデータと比較し、関連度が高い上位n件のテキストデータと、プロンプトとを大規模言語モデルに送信する。大規模言語モデルにテキストを保存する際、大規模言語モデルに機械学習させる。
【選択図】図1
特許請求の範囲
【請求項1】
社会における組織内の製品に関連するテキストを含む文書ファイルを検索する方法において、
大規模言語モデルデータベースへのデータ保存は、
文書ファイル中のテキストを、チャンクとして断片化し、それぞれのチャンクは、連続するテキストにおける1つ前のチャンクの末尾部分を一定数以上含み、
それぞれのチャンクはベクトル化された数値と関連付けられており、それぞれのチャンクが、ファイル名、カテゴリ、製品名、およびテキストを含むデータを付与した単位データとして保存する方法により行われ、
質問方法は、ユーザー入力するテキストをベクトル化したデータを、大規模言語モデルにおいて回答情報源から抽出されたテキストをベクトル化したデータと比較し、
関連度が高い上位n件の"テキストデータを取得し、ユーザーの質問として入力されたテキストと、前記取得した関連度が高い上位n件の"テキストデータと、プロンプトとを大規模言語モデルに送信する方法ことにより行われ、
大規模言語モデルにチャンクとして断片化されたテキストを他のデータと関連付けて保存する際、
関連付けるデータ中、チャンクとして断片化されたテキストデータ自体をベクトル化したベクトルデータを関連付ける操作を最初に行ってから、その他の関連付けるデータを付与し、単位データとして保存することを特徴とする大規模言語モデルに機械学習させる方法。
続きを表示(約 170 文字)
【請求項2】
請求項1に記載の方法で機械学習をした大規模言語モデルに対しデータの送受信を行うプログラム。
【請求項3】
請求項1に記載の方法の機械学習を大規模言語モデルにさせることにより、任意の回答情報源の母集団に対し、設定された質問の集合中の質問を行った際の、前記大規模言語モデルの回答精度を向上させるためのプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、大規模言語モデルを作成する方法に関する。また、本発明は、それを用いたプログラムに関する。
続きを表示(約 3,200 文字)
【背景技術】
【0002】
大規模言語モデル(Large Language Model、又は、これを略してLLMと称する)は、非常に巨大なデータセットを有し、ディープラーニング技術を用いて検索を高速化することが可能であるような構築された言語モデルという側面を有する。
近年、大規模言語モデルに関して多くの研究がなされ、自然言語を適確かつ高速に処理し、質問に対する回答を出力することが出来るようになってきた。
【先行技術文献】
【特許文献】
【0003】
特許文献1: 特開2024-27070
【0004】
特許文献1は、会話型AIシステム及びアプリケーションにおけるタスク指向型対話のため の正準形式の生成に関する文献であり、自然言語を処理するための大規模データ処理に関する記載がある。
しかし、同文献には、前記大規模データ処理に関して、それに用いるテキストデータを、人間ないし人間を中心として形成されるネットワークとしての社会における組織において作成され、用いられる文書に限定するか、またはそれらを中心としたものに適するようなものとして設計し、対話における回答がより適確にすること、また、その回答精度を向上させることについての記載はない。
【発明の概要】
【発明が解決しようとする課題】
【0005】
上記のような状況から、人間ないし人間を中心として形成されるネットワークとしての社会における組織において、様々な状況にふさわしい回答を行うことが出来る言語モデルを提供するためには、その組織において作成され、用いられる膨大な量の文書検索における上位に挙げられる結果の回答精度を向上させなければならないという課題が存在する。
膨大なデータを処理するには、そのデータために適したデータ構成と、それに伴う構造とする必要があるが、いずれにしても、大規模言語モデルを用いた処理の計算量は非常に大きいものであり、充分な処理速度を得るために高性能の処理装置を用いる必要がある。
公開されていないデータや資料を検索する上で、生成系AIと一般に称される大規模言語モデルが機械学習できていない領域のテキストデータとして検索範囲に取り込んで検索を行う場合、機械学習が行われていない領域に関して、機械学習が進むまで回答精度が十分高くなるまでに時間を世するという課題が存在する。
【課題を解決するための手段】
【0006】
本発明は、上記課題を解決するため、次の手段を用いるが、次のものに限定されるわけではない。
人間ないし人間を中心として形成されるネットワークとしての社会における組織において作成され、用いられる文書に適したデータ構成と、それに伴う構造とする必要がある。
本発明は、社会における組織内の製品に関連するテキストを含む文書ファイルを検索する方法において、大規模言語モデルデータベースへのデータ保存は、文書ファイル中のテキストを、所定の文字数ごとにチャンクとして分断し、それぞれのチャンクは、連続するテキストにおける1つ前のチャンクの末尾部分を一定文字数以上含み、それぞれのチャンクはベクトル化された数値と関連付けられており、それぞれのチャンクが、ファイル名、カテゴリ、製品名、およびテキストを含む単位データとして保存する方法により行われ、検索方法は、検索文字列を、プロンプトと共にベクトル化したデータとして、データベース中のチャンク中のテキストデータにより生成されたベクトルと比較する方法により行われ、大規模言語モデルデータベース中、チャンク化されたテキストを含む単位データをベクトル化した数値と関連付けてデータベース中に保存する際、チャンク化されたテキストデータに、チャンク化されたテキストデータ自体をベクトル化した数値を関連付ける操作を行ってから、単位データとして保存する大規模言語モデルデータベースの作成方法である。
【発明の効果】
【0007】
本発明の方法を用いることで、従来の方法では大規模言語モデルに質問を与え、回答を得る際、広範囲の独自情報とともに質問すると、通信量が多くなり過ぎ一般的な設定値を超えてしまうことや、回答を得るまでに時間がかかるところ、大規模言語モデルに機械学習をさせることで、回答精度も向上し、通信量が相対的に少なくなると共に回答時間が短くなる。このことは更に、従量制課金の大規模言語モデルを有料で利用する際には、経済的有用性も生じる。
現在の一般的な大規模言語モデルによる検索は、インターネット上の情報のみを機械学習しているが、本発明における方法における大規模言語モデルは、インターネット上の情報に加え、社会における組織内に保存され、一般的には公開されていない情報を、主として組織内で利用するために用いる。この際、本発明の方法を用いることで、機械学習により未学習の領域の検索精度が大幅に向上し、それに伴い検索の速度や効率も向上する。
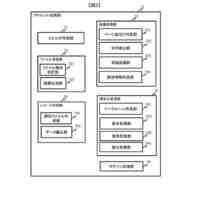
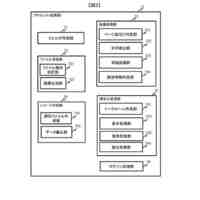
【図面の簡単な説明】
【0008】
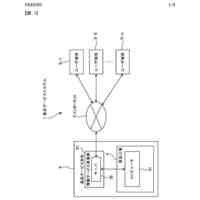
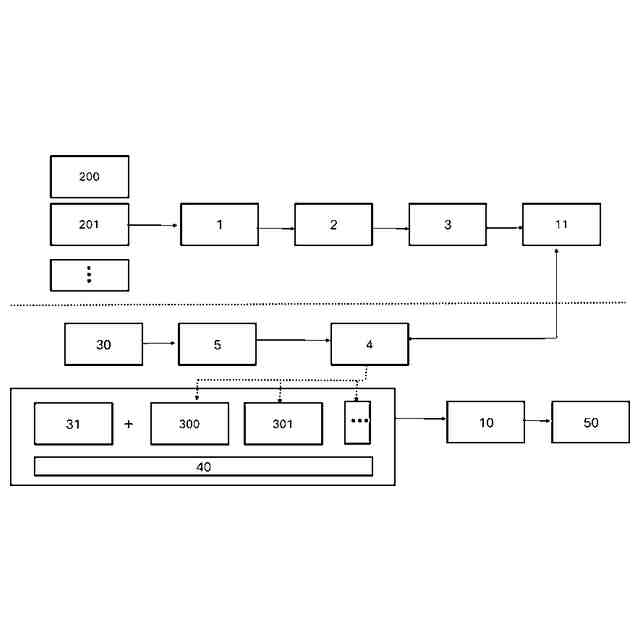
本発明において、回答情報源を基に大規模言語モデル(LLM)が質問から回答を出力するフローを示す図である。
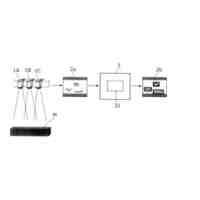
テキスト抽出/データ整形の概念図である。
チャンク化の概念図である。
チャンク化されたテキストの先頭の一部と末尾の一部が重複することを示す略図である。
テキストのエンベディング(ベクトル化)の概念図である。
質問から抽出したベクトルデータと、LLMに保存されたベクトルデータとと比較している概念図である。
対応するベクトルデータにより、同じ意味の外国語で、質問と回答を行うこともできることを示す概念図である。
公開されていな回答情報源の場合、回答が得られない場合があることを示す概念図である。
【発明を実施するための形態】
【0009】
本発明における実施形態を以下に例示するが、本発明の要旨を逸脱しない限りにおいて、本発明の実施形態は、以下のものに限定されない。
【0010】
本発明の第1の実施形態は、図1のフロー図に示すものであり、次の(1)~(3)の構成により例示される。
(1)社会における組織内の製品に関連するテキストを含む文書ファイルを検索する方法において、
大規模言語モデルデータベースへのデータ保存は、
文書ファイル中のテキストを、チャンクとして断片化し、それぞれのチャンクは、連続するテキストにおける1つ前のチャンクの末尾部分を一定数以上含み、
それぞれのチャンクはベクトル化された数値と関連付けられており、それぞれのチャンクが、ファイル名、カテゴリ、製品名、およびテキストを含むデータを付与した単位データとして保存する方法により行われ、
質問方法は、ユーザー入力するテキストをベクトル化したデータを、大規模言語モデルにおいて回答情報源から抽出されたテキストをベクトル化したデータと比較し、
関連度が高い上位n件の"テキストデータを取得し、ユーザーの質問として入力されたテキストと、前記取得した関連度が高い上位n件の"テキストデータと、プロンプトとを大規模言語モデルに送信する方法ことにより行われ、
大規模言語モデルにチャンクとして断片化されたテキストを他のデータと関連付けて保存する際、
関連付けるデータ中、チャンクとして断片化されたテキストデータ自体をベクトル化したベクトルデータを関連付ける操作を最初に行ってから、その他の関連付けるデータを付与し、単位データとして保存することを特徴とする大規模言語モデルに機械学習させる方法である。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
株式会社GFLOPS
大規模言語モデルに機械学習させる方法及びその利用のためのプログラム
5日前
個人
詐欺保険
15日前
個人
縁伊達ポイン
15日前
個人
RFタグシート
2日前
個人
地球保全システム
28日前
個人
QRコードの彩色
19日前
個人
自動調理装置
1日前
個人
為替ポイント伊達夢貯
1か月前
個人
冷凍食品輸出支援構造
1か月前
個人
表変換編集支援システム
1か月前
個人
残土処理システム
21日前
個人
農作物用途分配システム
14日前
個人
タッチパネル操作指代替具
8日前
個人
知財出願支援AIシステム
1か月前
個人
知的財産出願支援システム
22日前
個人
携帯端末障害問合せシステム
7日前
個人
行動時間管理システム
1か月前
個人
AIによる情報の売買の仲介
1か月前
個人
スケジュール調整プログラム
7日前
個人
パスワード管理支援システム
1か月前
株式会社キーエンス
受発注システム
27日前
日本精機株式会社
施工管理システム
1か月前
株式会社アジラ
進入判定装置
2か月前
個人
AIキャラクター制御システム
1か月前
個人
海外支援型農作物活用システム
1か月前
個人
システム及びプログラム
1か月前
株式会社キーエンス
受発注システム
27日前
個人
食品レシピ生成システム
27日前
個人
パスポートレス入出国システム
2か月前
株式会社キーエンス
受発注システム
27日前
個人
SaaS型勤務調整支援システム
1か月前
個人
社会還元・施設向け供給支援構造
1か月前
大同特殊鋼株式会社
疵判定方法
1か月前
個人
冷凍加工連携型農場運用システム
1か月前
エッグス株式会社
情報処理装置
8日前
個人
人格進化型対話応答制御システム
1か月前
続きを見る
他の特許を見る









 特許ウォッチ
特許ウォッチ