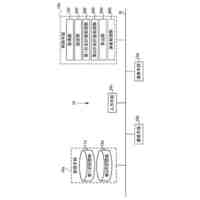
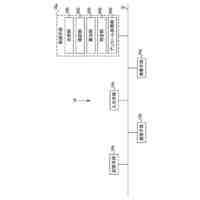
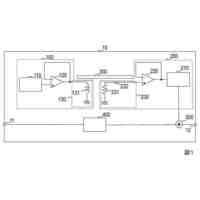
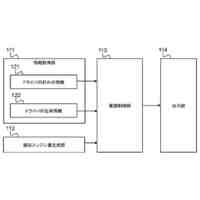
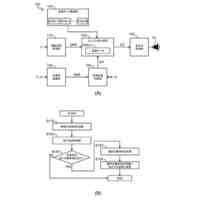
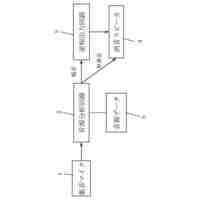
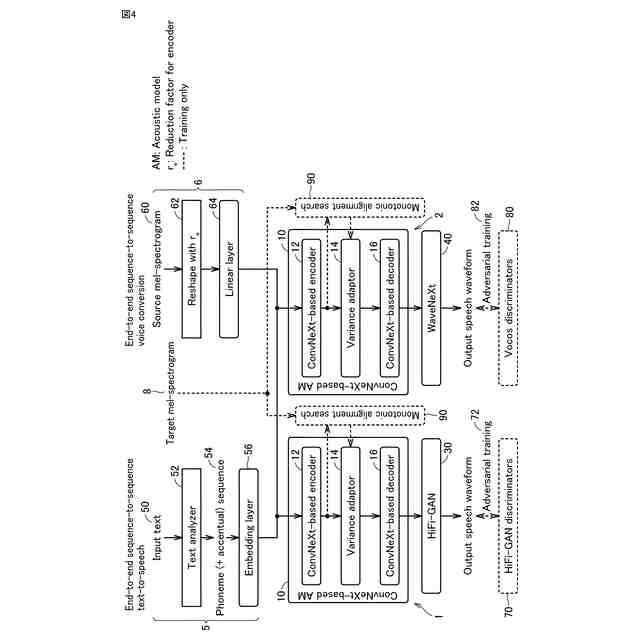
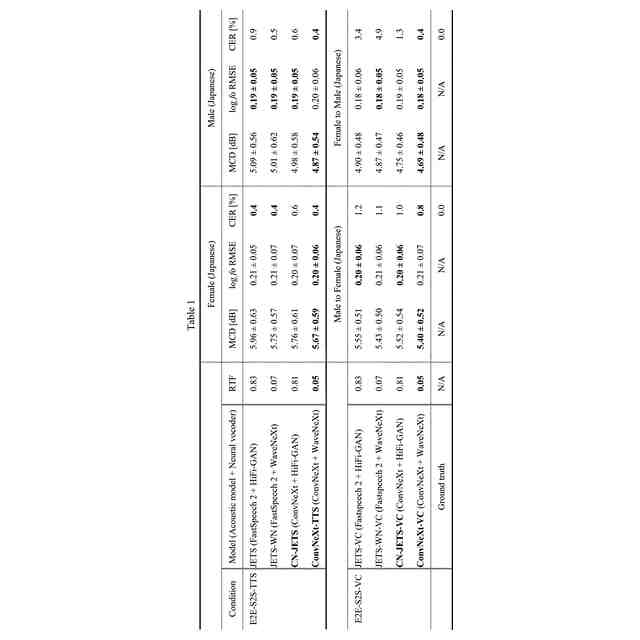
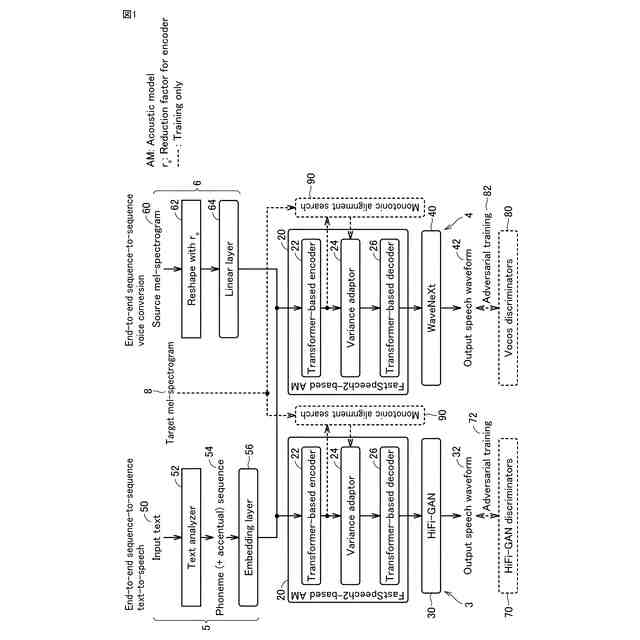
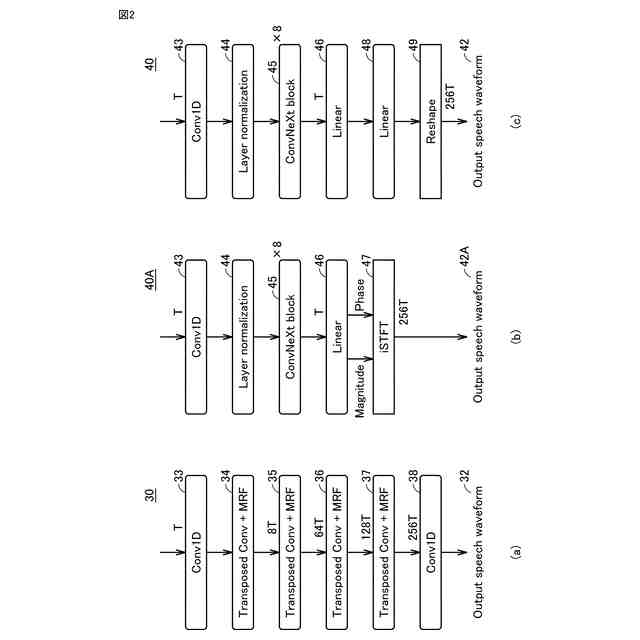
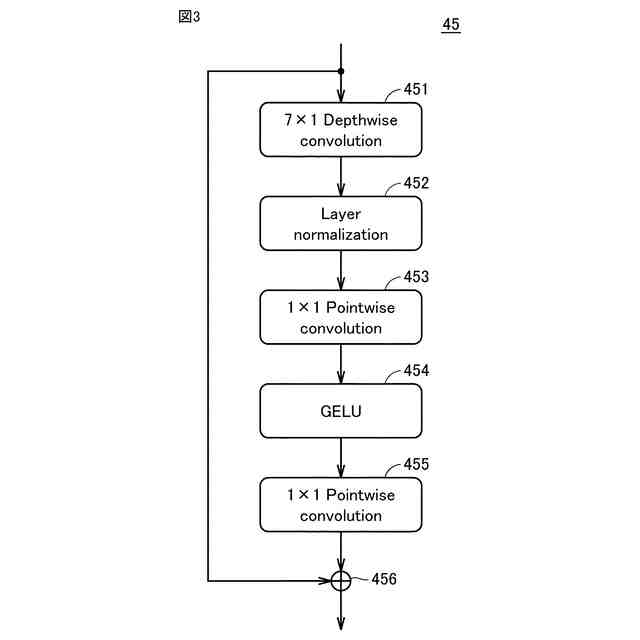
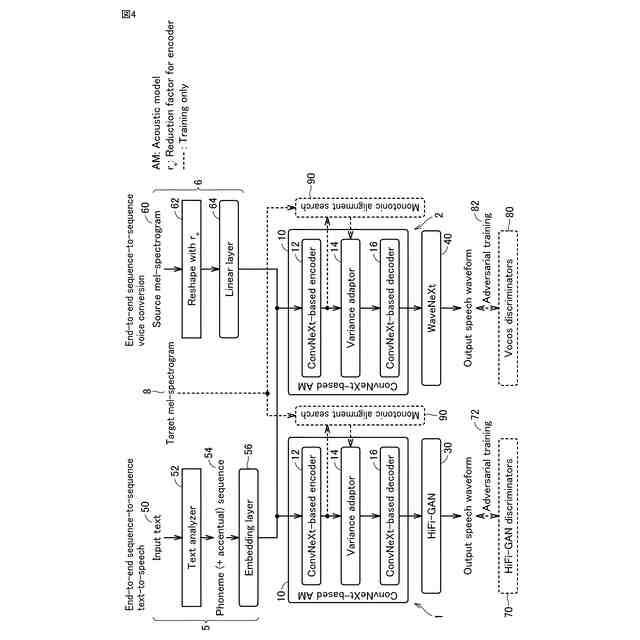
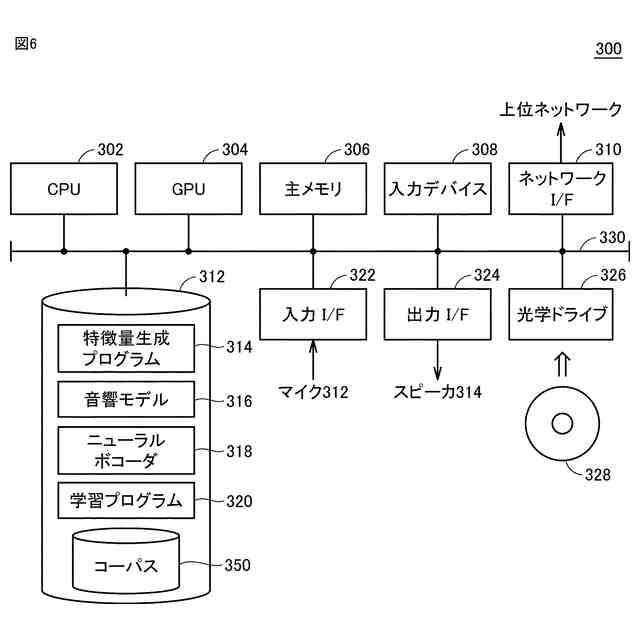
発明の詳細な説明【技術分野】 【0001】 本発明は、音声波形生成システム、音声波形生成方法、および、音声波形生成プログラムに関する。 続きを表示(約 2,400 文字)【背景技術】 【0002】 ここ数年で、ニューラルネットワークを用いた音声合成・声質変換技術は大きく進展している。その結果、実験条件によっては、自然音声とほぼ変わらない高品質な合成が可能となっている。 【0003】 さらに、単一のニューラルネットワークを用いて、テキストから音声波形を直接生成する系列変換型End-to-endテキスト音声合成モデル、および、単一のニューラルネットワークを用いて、変換元音声から変換先音声波形を直接生成する系列変換型End-to-end声質変換モデルが提案されている。 【0004】 より具体的には、系列変換型のテキスト音声合成モデルおよび/または声質変換モデルのエンコーダおよび/またはデコーダには、機械翻訳タスクにおいて提案されたTransformer型ニューラルネットワークが広く用いられている(非特許文献1および2など参照)。Transformer型ニューラルネットワークを用いたモデルは、自己回帰モデルであるため、より多くの生成時間が必要となるが、入出力のアライメントを別モデルで習得することにより、非自己回帰型の高速モデルを実現できる(非特許文献3および4など参照)。非自己回帰型の高速モデルとニューラル波形生成モデルとを同時学習することにより、単一のニューラルネットワークを用いた、系列変換型End-to-endテキスト音声合成モデルおよび/または系列変換型End-to-end声質変換モデルを構築できる。このようなモデルは、従来モデルを凌ぐ性能を達成している(非特許文献5および6など参照)。 【先行技術文献】 【非特許文献】 【0005】 N. Li, S. Liu, Y. Liu, S. Zhao, M. Liu, and M. Zhou, "Neural speech synthesis with Transformer network," in Proc. AAAI, Jan. 2019, pp. 6706-6713. R. Liu, X. Chen, and X. Wen, "Voice conversion with transformer network," in Proc. ICASSP, May 2020, pp. 7759-7763 Y. Ren, Y. Ruan, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y. Liu, "FastSpeech: Fast, robust and controllable text to speech," in Proc. NeurIPS, Dec. 2019, pp. 3165-3174. T. Hayashi, W.-C. Huang, K. Kobayashi, and T. Toda, "Non-autoregressive sequence-to-sequence voice conversion," in Proc. ICASSP, June 2021, pp. 7068-7072. D. Lim, S. Jung, and E. Kim, "JETS: Jointly training Fast-Speech2 and HiFi-GAN for end to end text to speech," in Proc. Interspeech, Sept. 2022, pp. 21-25. T. Okamoto, T. Toda, and H. Kawai, "E2E-S2S-VC: End-to-end sequence-to-sequence voice conversion," in Proc. Interspeech, Aug. 2023, pp. 2043-2047 【発明の概要】 【発明が解決しようとする課題】 【0006】 系列変換型End-to-endテキスト音声合成モデルおよび系列変換型End-to-end声質変換モデル(以下、「系列変換型End-to-endモデル」とも総称する。)を用いることにより、従来モデルを凌ぐ性能を達成しているが、自然音声の品質までは到達していない。 【0007】 また、提案されている系列変換型End-to-endモデルにおいても、CPUの1コアの処理リソースであっても、リアルタイムに音声波形生成が可能であるが、モバイル端末でのリアルタイムの音声波形生成などを考慮すると、処理速度のさらなる高速化も必要になる。 【0008】 本発明は、音声波形生成をより高速化するとともに、品質をより改善することができる系列変換型End-to-endモデルを提供することを目的とする。 【課題を解決するための手段】 【0009】 ある実施の形態に従う音声波形生成システムは、入力される第1の特徴量から第2の特徴量を予測する音響モデルと、第2の特徴量から音声波形を予測する波形生成モデルとを含む。音響モデルは、第1の特徴量を連続表現に変換するためのエンコーダと、連続表現から各音素の継続長を予測するバリアンスアダプタと、バリアンスアダプタの出力から第2の特徴量を予測するデコーダとを含む。エンコーダおよびデコーダの各々は、深さ単位畳み込み層と、層正規化ブロックと、点単位畳み込み層と、ガウス誤差線形ユニットとを含む。 【0010】 第1の特徴量は、テキストから生成される言語特徴量、および、メルスペクトログラムから生成される音響特徴量のうち少なくとも一方を含んでいてもよい。 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する

 特許ウォッチ
特許ウォッチ